腾讯AI Lab联合清华、港中文,万字解读图深度学习历史、最新进展与应用

原创 Synced 机器之心
机器之心发布
机器之心编辑部
本文将分图神经网络历史、图神经网络的最新研究进展和图神经网络的应用进展三大部分归纳总结该课程 Theme II: Advances and Applications 部分的核心内容。作者包括腾讯荣钰、徐挺洋、黄俊洲,清华大学黄文炳,香港中文大学程鸿。
人工智能领域近几年历经了突飞猛进的发展。图像、视频、游戏博弈、自然语言处理、金融等大数据分析领域都实现了跨越式的进步并催生了很多改变了我们日常生活的应用。近段时间,图神经网络成为了人工智能领域的一大研究热点,尤其是在社交网络、知识图谱、化学研究、文本分析、组合优化等领域,图神经网络在发掘数据中隐含关系方面的强大能力能帮助我们获得更好的数据表达,进而能让我们做出更好的决策。比如通过图神经网络梳理人类社会关系网络的演变,可有望帮助我们理解人类社会的底层运作模式,进而让我们离理想社会更近一步。
在今年的计算机协会国际数据挖掘与知识发现大会(ACM SIGKDD,简称 KDD)上,图神经网络备受研究关注的现状得到了充分体现:粗略统计,今年 KDD 接收的 216 篇论文(research track)中有近 40 篇与图神经网络相关。也因此,一场为期一天的图神经网络相关课程得到了参会人员的重点关注。该联合课程的主题为「图深度学习:基础、进展和应用(Deep Graph Learning: Foundations, Advances and Applications)」,由腾讯 AI Lab、清华大学、香港中文大学等机构联合组织,从基础的图概念一直谈到了当今最前沿的图神经网络研究进展。
本次课程分为两个主题。本文将分图神经网络历史、图神经网络的最新研究进展和图神经网络的应用进展三大部分归纳总结该课程 Theme II: Advances and Applications 部分的核心内容,Theme I 以及更多详细的内容可参看课程幻灯片及相关论文:https://ai.tencent.com/ailab/ml/KDD-Deep-Graph-Learning.html
为了解决图学习中的一系列具有挑战性的问题, 探索图学习应用的边界并在于助力公司各类与图数据相关的业务。腾讯 AI Lab 于 2017 年下半年开始布局图深度学习的研究,积极探索图深度学习的应用边界。并且在各大机器学习数据挖掘顶级会议上发表多篇文章,涉及大图计算,超深图神经网络,无监督图学习,图的对抗攻击,图的样本学习等。在未来我们将探索图深度学习在广泛场景的应用,如社交推荐,药物研发等。使其能够真正造福人类。
一 图与图神经网络
1 什么是图?
汉语中的「图」可以对应成英语中多个不同的词:image、picture、map 以及本文关注的 graph。图(graph)也可称为「关系图」或「图谱」,是一种可用于描述事物之间的关系的结构。图的基本构成元素为顶点和连接顶点的边。根据边是否存在方向的性质,还可分为有向图和无向图。一般而言,我们通常可将图表示成点和连接点的线的形式,这有助于我们更直观地理解,如下图所示:
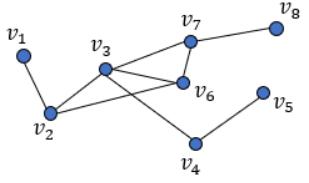
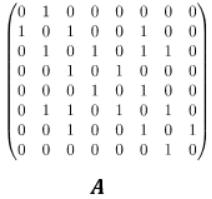
2 图神经网络
近些年在大数据和硬件发展双重助力下迎来跨越式发展的深度神经网络技术让我们具备了分析和理解大规模图数据的能力。总体而言,图分析任务可分为节点分类、连接预测、聚类三类。
图神经网络(GNN)就是处理图数据的神经网络,其中有两种值得一提的运算操作:图过滤 (Graph Filter, 分为基于空间的过滤和基于谱的过滤)和图池化。其中图过滤可细化节点特征,而图池化可以从节点表示生成图本身的表示。
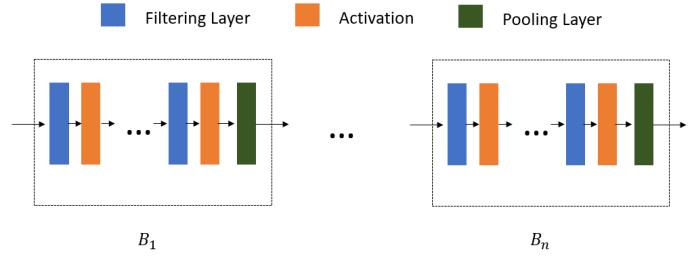
一般来说,GNN 的框架在节点层面上由过滤层和激活构成,而对于图层面的任务,则由过滤层、激活和池化层组成不同的模块后再连接而成。
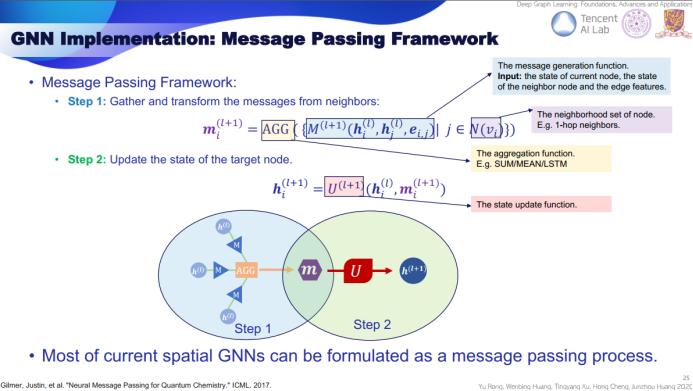
第一步是消息生成步骤。首先,从近邻节点收集状态数据,然后使用对应函数生成当前节点的消息。在第二步中,我们更新目标节点的状态。
3 图神经网络的发展历史
图神经网络(GNN)并不是一个新事物,最早的 GNN 的历史可以追溯到 1997 年,粗略总结起来,GNN 的发展过程大致可分为三个阶段。
在第一个阶段,GNN 所使用的主要方法是基于循环神经网络(RNN)的扩展。众所周知,RNN 擅长处理序列数据,而反过来,序列数据则可被视为一种特殊模式的图。因此,早期的一些工作(TNN97 / TNN08)将处理序列数据的 RNN 泛化用于树和有向无环图(DAG)等特殊的图结构。但那之后这一领域的发展几乎陷入了停滞状态。然而,在当前这轮深度学习热潮的带动下,对非结构化数据的建模和处理的研究开始广泛涌现,GNN 也迎来了自己的发展契机,顶级会议上的相关论文数量也迅猛增长。
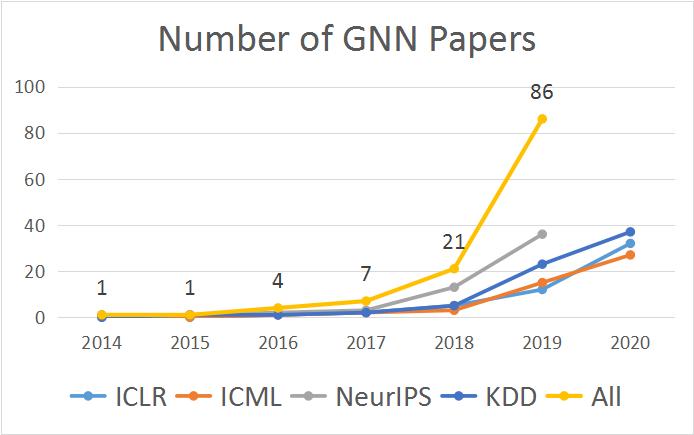
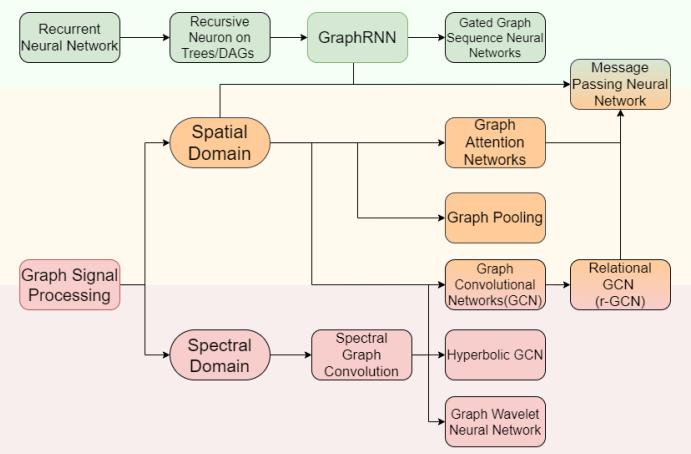
我们现在正处于 GNN 发展的第三个阶段。图卷积已经出现了多种变体,注意力机制已被引入 GNN 中,此外还出现了图池化(Graph Pooling)技术和高阶 GNN。这一阶段出现的重要技术包括:
变体卷积:Lanczos 网络(使用 Lanczos 算法来获取图拉普拉斯的低秩近似)、图小波神经网络(使用小波变换替代傅里叶变换)、双曲 GCN(将 GCN 构建到双曲空间中)。
注意力机制:图注意力网络(使用可学习的自注意力替换固定的聚合权重)、门控注意力网络(加入了可学习的门来建模每个头的重要度)、谱式图注意力网络(将注意力应用于谱域中的高 / 低频组件)。
图池化:SAGE(自注意图嵌入,在池化时使用自注意力来建模节点重要度)、通过图剪切实现图池化(通过图剪切算法得到的预训练子图实现图池化)、可微分图池化(DIFFPOOL,通过学习聚类分配矩阵以分层方式来聚合节点表征)、特征池化(EigenPooling,通过整合节点特征和局部结构来获得更好的分配矩阵)。
高阶 GNN:高阶 GNN 是指通过扩展感受野来将高阶相近度(high-order proximities)编码到图中。高阶相近度描述的是距离更多样的节点之间的关系,而不仅是近邻节点之间的关系。这方面的研究工作包括 DCNN(通过把转移矩阵的幂级数堆叠起来而将邻接矩阵扩展为张量,然后相互独立地输出节点嵌入和图嵌入)、MixHop(使用了归一化的多阶邻接矩阵,然后汇集各阶的输出,从而同时得到高阶和低阶的相近度)、APPNP(使用了个性化 PageRank 来为目标节点构建更好的近邻关系)。
下图简单总结了各种 GNN 变体之间的关系:
了解了 GNN 的基本知识和发展脉络,接下来我们将踏入当前的前沿研究领域,解读近期的一些理论研究成果和设计创新。
1 图神经网络的表达能力
我们知道图在表达事物的关系方面能力非凡,但图神经网络表达能力的极限在哪里?清华大学计算机系助理研究员、清华大学「水木学者」、腾讯「犀牛鸟访问学者」黄文炳在课程中介绍了相关的研究进展。
为了有效地评估 GNN 的表达能力,首先需要定义评估标准。目前来说,可通过三种典型任务来进行评估:图同构、函数近似和图检测 / 优化 / 评估。
对于图同构任务,GNN 的目标是确定任意给定的两个图是否同构。这是一个很重要的任务。对于图分类任务而言,如果两个图是同构的,则 GNN 需要为这两个图输出同样的标签。
但是,判定图是否同构的问题是一个 NP-hard 问题,传统的 Weisfeiler-Lehman(WL)测试方法除了少数图结构外,基本能否识别大多数图结构是否同构。而 GNN 能更好地解决这一问题吗?
并不一定。2019 年,Xu et al. 和 Morris et al. 已经证明 GNN 至多做到与 WL 测试一样强大。之后,Xu et al. 还进一步证明,如果 GNN 中的聚合和读出函数(readout function)是单射函数,则 GNN 就与 WL 测试等效。
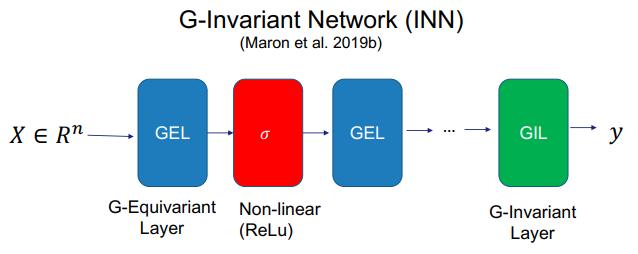
对于函数近似任务,该任务的目标是判断 GNN 能否以任意准确度近似任何基于图的函数。因为 GNN 本身也是基于图的某种函数,因此 GNN 在这一任务上的表现将能体现其能力。实际上,DNN 也有类似的评估任务。我们知道,只要隐藏单元足够多,DNN 可以收敛到任何向量函数,这就是所谓的「通用近似定理」。所以我们很自然也会为 GNN 提出类似的问题。
Maron et al. 提出了一种架构,对于拥有图不变映射层(graph invariant layer)和图等变映射层(graph equivariant layer)的 GNN,如果在一个非线性层(比如 ReLU)之后堆叠等变映射层,层层叠加,然后在最后添加图不变映射层。可以看出这样的模型能在输入的排列方式变化时保持映射不变性。这样的模型被称为图不变网络(INN)。
看过了图同构和函数近似的近期进展,更进一步,这两者之间又有何关系呢?Chen et al. 2019 证明在满足一些条件的情况下,这两者其实是等效的。
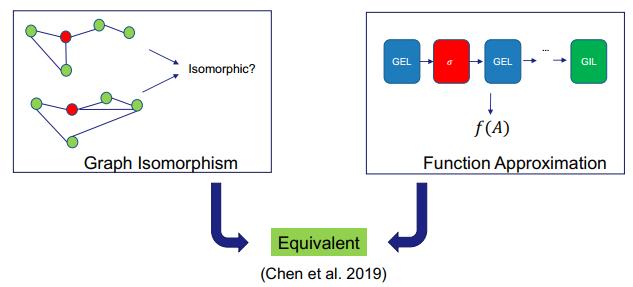
Loukas 证明 GNN 能解决这些任务,他得出结论:只要 GNN 的深度和宽度足够,而且节点之间具有可互相判别的属性,则 GNN 就能完成这些任务。这里深度是指 GNN 的层数,宽度则是指隐藏单元的维度。
因此,总结起来,只要架构合适,GNN 其实具有非常强大的表达能力;也因此,要充分发掘 GNN 的真正实力,我们还需要更多架构方面的研究探索。
2 训练深度图神经网络
前面已经简单提到,深度对 GNN 的能力而言是非常重要的。这一点在深度神经网络(DNN)上也有体现——更深的网络往往具有强大的表达能力,可以说深度网络就是当前的人工智能发展热潮的最主要驱动力之一。
那么,具体来说,更深度的 GNN 是否也有如此的优势呢?更深度的 GNN 能否像 CNN 一样获得更大的感受野?
答案当然是肯定的。举个例子,寻找最短路径问题需要非常深的感受野来寻找所有可能的路径,环检测和子图查找问题也都需要较大的感受野。
那么,我们可以怎样增大 GNN 的感受野,使其具备更强大的能力呢?为此,我们需要更深或更宽的 GNN。
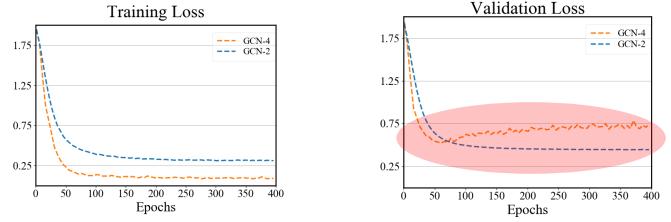
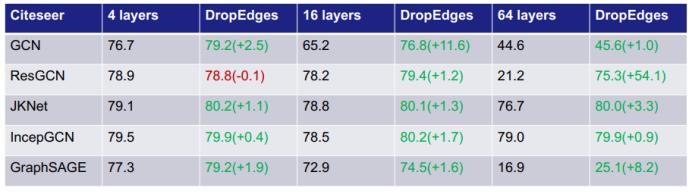
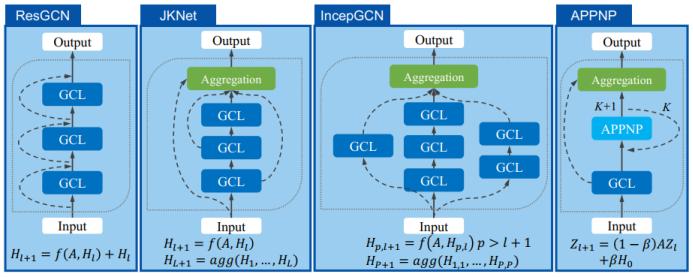
首先来看通过简单增加深度来扩展 GNN 的方法。可以看到,对于下图中的六种 GNN:GCN、GraphSAGE(进一步改进了池化方法)、ResGCN(使用了残差网络的思路)、JKNet(使用了 DenseNet 的思路)、IncepGCN(使用了 Inception-v3 的思路)、APPNP(借用了 PageRank 的思路),简单增加深度并不一定能提升准确度,甚至还可能出现相反的状况,比如 GCN、GraphSAGE 和 ResGCN 在深度增大时准确度反而显著下降。
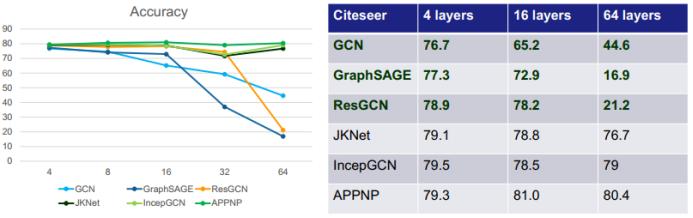
近期的研究找到了有碍 GNN 变得更深的三大根本原因:过平滑(over-smoothing)、过拟合(overfitting)和训练动态变化(training dynamics)。其中后两者也是常见的深度学习问题,而过平滑则是图深度学习方面特有的问题。
过平滑
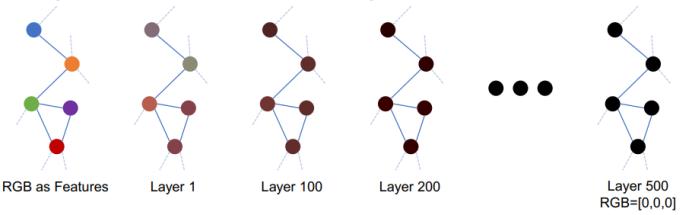
首先来看过平滑。GNN 本质上是逐层推送彼此相邻节点混合的表征,因此极端地看,如果层数无限多,那么所有节点的表征都将收敛到一个驻点,这也就与输入特征完全无关了,并会导致梯度消失问题。因此,过平滑的一个现象是模型的训练损失和验证损失都难以下降。那么,为什么会出现过平滑呢?
我们以线性 GCN 来进行说明。首先,GCN 与平滑有何关联?一般来说,GCN 可被视为拉普拉斯平滑(Laplacian smoothing)的一种特殊形式,如下所示:
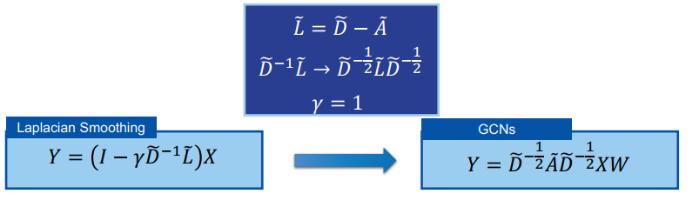
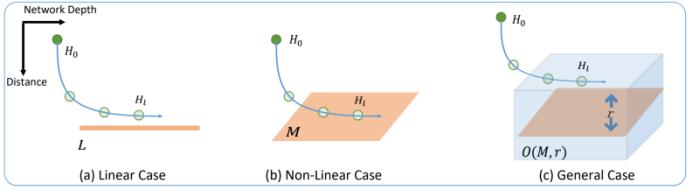
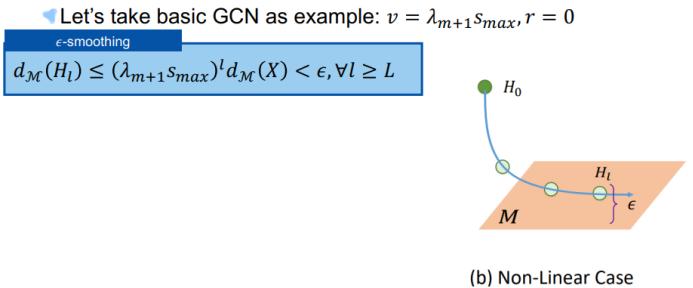
要知道这个过平滑过程发生的位置,我们先讨论一下 GCN 何时会因过平滑而失效?我们将讨论三种过平滑的情况。第一种是使用线性激活时,隐变量 H_L 会收敛到一个特定的点。第二种是使用 ReLU 激活时,H_L 会收敛到一个特定的平面 M。第三种是使用 ReLU 加偏差时,H_L 会收敛到一个特定的子立方体 O(M, r) 的表面。
然后,如果我们用一组在节点特征上的可学习参数替换这个初始概率,它就能转换成一个线性的 L 层 GCN。

详细地说,我们首先需要进行特征值分解,即将归一化的邻接矩阵分解为 n 个特征值 λ 及其对应的特征向量 u。
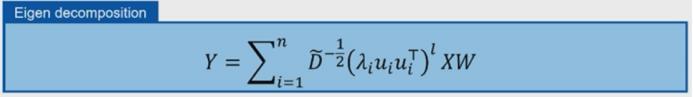
这个图谱中的特征值有一个性质。即,假设一个图 g 包含 m 个互相连接的分量,则归一化邻接矩阵的特征值便由 m 个为 1 的最大特征值构成,其余的 λ 则在 (-1,1) 的开区间中。
因此,当 lL 趋近无穷大时,最大的 m 项依然存在,因为其 λ 等于 1。但是,其余的项都将被忽略,因为这些 λ 的 l 次幂将趋近于零。这会使得隐变量 H_L 随网络深度增长而趋近于一个特定的点。
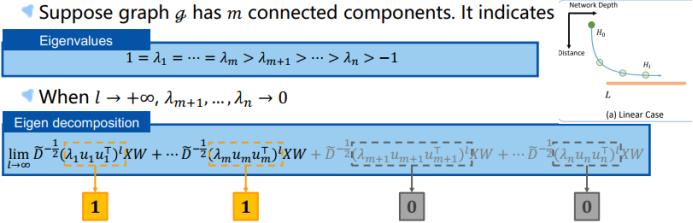
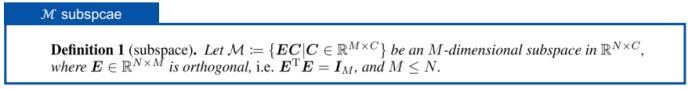
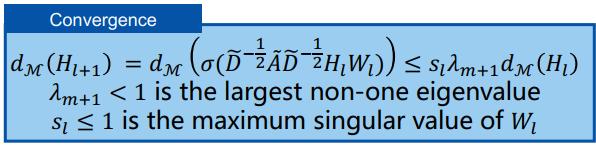
接下来我们开始解析这个收敛公式。这个归一化邻接矩阵的收敛满足这一不等式。
如果我们假设这个子空间的维度为 m,则 m 个最大的 λ 将位于该子空间,其余的则在 λ_m+1 的范围内。
然后,模型参数 W_l 和 ReLU 的收敛分别满足下列两个不等式:
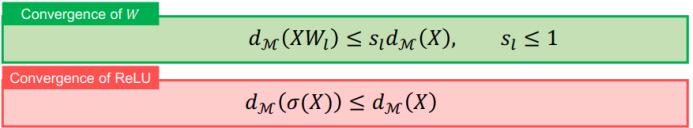
综合这些不等式,可得到隐变量的子空间距离沿层数变化的收敛性。可以看到,随着层数趋近于无穷大,子空间距离将趋近于 0,因此隐变量将会收敛到子空间 M。
接下来是更一般的情况,使用 ReLU 加偏差的 GCN 又如何呢?H_L 将收敛到一个特定子立方体 O(M,r) 的表面上。首先,我们写出带偏差的 GCN 的公式:
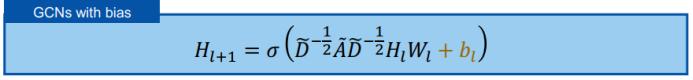
可以看到,当 l 趋近无穷大时,不等式右侧部分就是一个无穷等比序列的和:
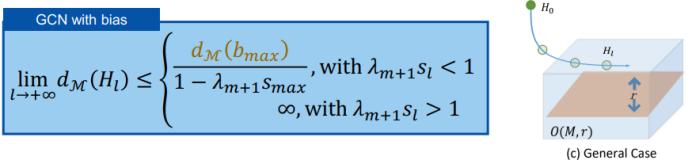
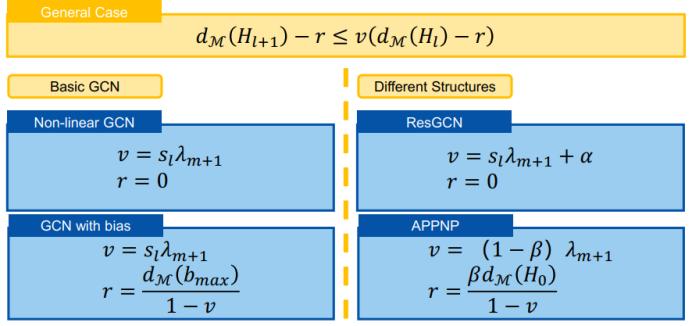
总结一下,通过分析上面三种来自不同场景的情况,可以发现这三种情况之下存在一种普适的公式。我们可用以下不等式统一过平滑的情况:
然后通过不同的 v 和 r 取值,我们可以得到不同的具体情况:

接下来我们看看过拟合问题。过拟合是深度学习的一个常见问题,当数据点数量少而参数数量很多时,就会出现这种情况。此时模型会与训练数据完全拟合(本质上就是记住了数据),而在验证数据上表现很差。
如何解决过平滑问题?
首先,如何量化平滑?以 GCN 为例,我们先定义一个 ε- 平滑,使得对于任意大于特定层 L 的 l,隐变量 H_l 的子空间距离将小于 ε:
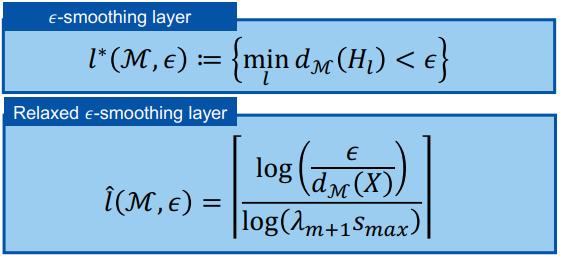
注意这里的 λ_m+1 与邻接矩阵相关,s_max 与模型权重相关,这也暗示了存在两个缓解过平滑问题的方向。
第一,我们可以通过处理邻接矩阵来缓解过平滑,即增大 λ_m+1,进而使得松弛化的 ε- 平滑层增大:
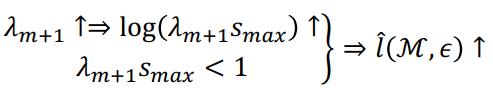
更多详情和实验论证可见腾讯 AI Lab 的 ICLR 2020 论文《DropEdge: Towards Deep Graph Convolutional Networks on Node Classification》。
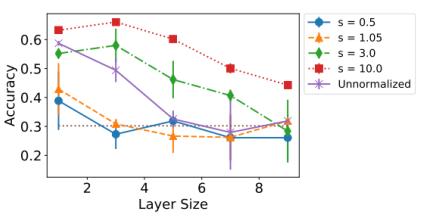
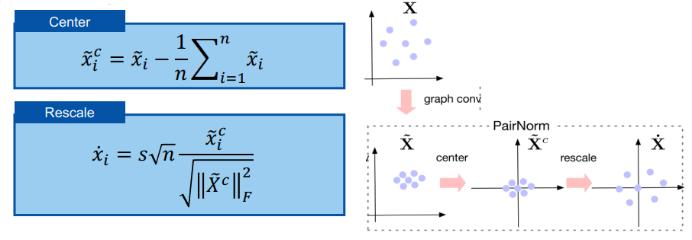
ICLR 2020 上还有一篇论文《PairNorm: Tackling Oversmoothing in GNNs》提出了一种用于解决训练动态变化问题的方法。
PairNorm 的思路对 GCN 输出进行居中和重新缩放或归一化,使得总的两两平方距离保持不变。如图所示,GCN 的输出点在图卷积之后通常会更接近彼此。但通过使用 PairNorm,新输出的两两距离能与输入的距离保持相似。
顺便一提,这些不同的 GNN 结构仍然满足过平滑的一般情况:
3 大规模图神经网络
真实世界的图可能具有非常大的规模,因此让 GNN 有能力处理大规模图是非常重要的研究课题。
基本的 GNN 通常无法处理大规模图,因为其通常无法满足巨大的内存需求,而且梯度更新的效率也很低。
为了让 GNN 有能力处理大规模图,研究者已经提出了三种不同的采样范式:基于节点的采样、基于层的采样和基于子图的采样。
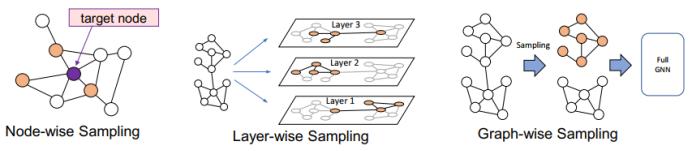
根据这三种范式,可以知道为了实现大规模 GNN,我们需要解决两个问题:如何设计高效的采样算法?如何保证采样质量?
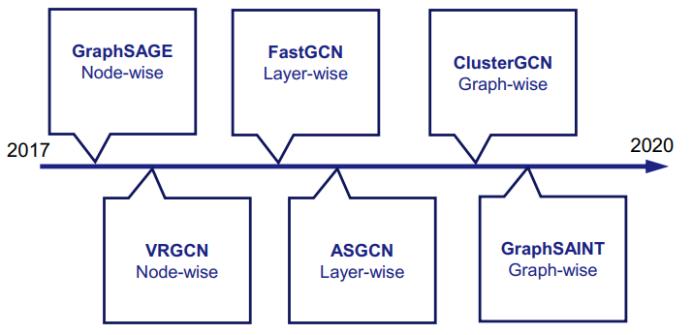
近些年在构建大规模 GNN 方面已经出现了一些成果,下图给出了这些成果的时间线:
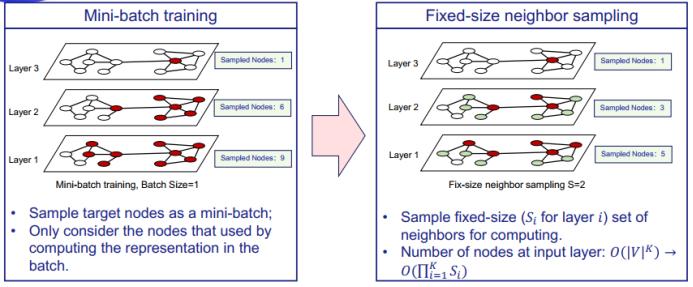
首先来看 GraphSAGE,其可被视为原始 GCN 的一种扩展:在 GCN 的平均聚合器的基础上增加了许多广义上的聚合器,包括池化聚合器和 LSTM 聚合器。不同的聚合器也会对模型产生不同的影响。此外,在聚合之后,不同于 GCN 使用的求和函数,GraphSAGE 使用了连接函数来结合目标节点机器邻近节点的信息。这两大改进是基于对 GCN 的空间理解得到的。
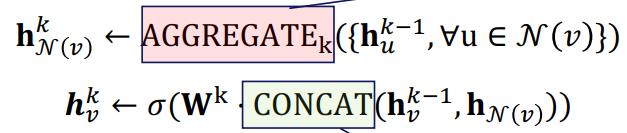
为了解决这一问题并进一步提升性能,GraphSAGE 采用了固定采样个数的的邻近采样方法,即每层都采样固定大小的邻近节点集合。
为了进一步降低采样规模和得到一些理论上的质量保证,VR-GCN 整合了基于控制变量的估计器(CV 采样器)。其可以维持历史隐藏嵌入(historical hidden embedding)来获得更好的估计,这个历史隐藏嵌入可用于降低方差,进而消除方差,实现更小的采样规模。VR-GCN 的数学形式如下:
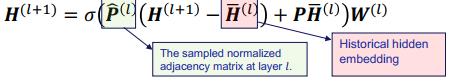
上面我们可以看到,基于节点的采样方法并不能彻底解决邻近节点扩张问题。接下来看基于层的采样方法。
FastGCN 提出从 Functional generalization 的角度来理解 GCN,并为 GCN 给出了基于层的估计形式:

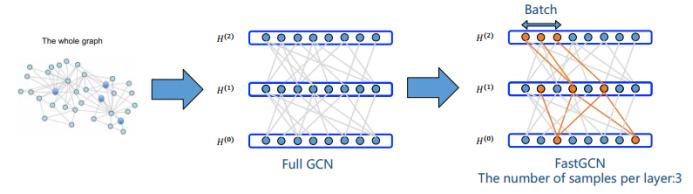
可以看出,基于层采样的 FastGCN 彻底解决了邻近节点扩张问题,而且采样方法有质量保证。但是该方法的缺点是无法获得层之间的相关性,模型的表现也可能受到负面影响。
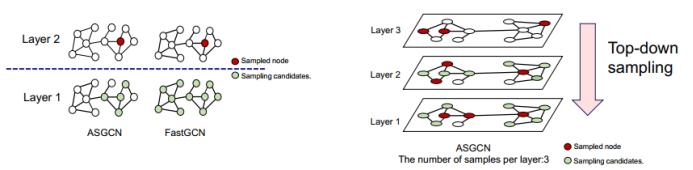
为了更好地获得层之间的相关性,ASGCN 提出了自适应层式采样方法,即根据高层采样结果动态调整更低层的采样概率。如下左图所示,在对底层采样的时候 ASGCN 会考虑采样高层采样的邻居节点,使得层之间的相关性得到很好的保留。如下右图所示,整个采样过程是自上而下的。我们首先采样输出层的目标节点,然后根据其采样结果采样中间层的节点,然后重复这个过程直到输入层。在采样过程中,每层采样节点的数目也会保持一个固定值。

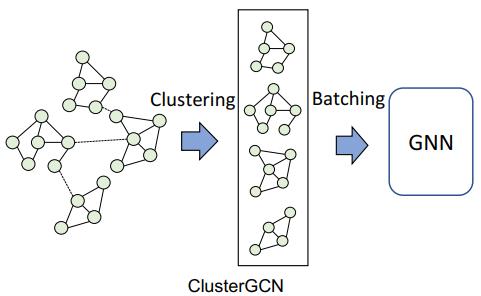
接下来出现了基于子图的采样方法。ClusterGCN 首先使用图分割算法将图分解为更小的聚子图,然后在子图层面上组成随机的分批,再将其输入 GNN 模型,从而降单次计算需求。
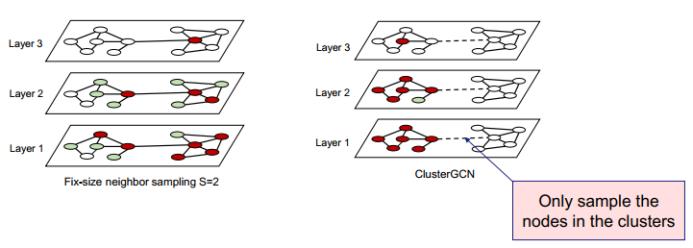
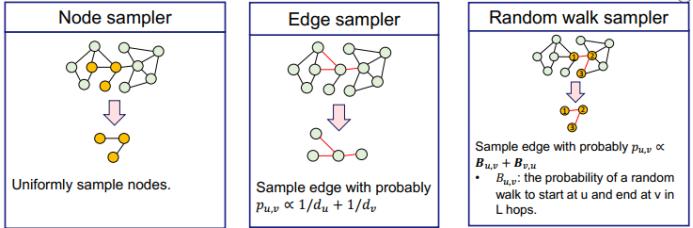
GraphSAINT 则并未在采样过程中使用聚类算法(这会引入额外的偏差和噪声),而是直接通过子图采样器来采样用于 mini-batch 训练的子图。其给出了三种采样器的构建方式,分别为基于节点的采样、基于边的采样和随机游走采样,如下所示:
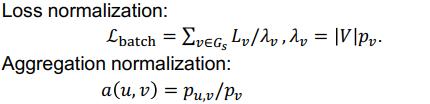
很显然,大规模图神经网络方面还有很大的进一步研究空间,比如更高效的采样技术、适用于异构图或动态图的架构等等。
4 图神经网络的自监督 / 无监督学习
前面讨论的 GNN 的表达能力、深度和规模都是基于监督式方法,也就是说我们有输入图的标签。但在现实生活中,获取这些标签却并非易事。比如在分子属性预测任务中,为了获取基本真值标签,我们必需专业人士的协助。此外,训练任务与测试任务并不总是一致的,比如对于社交网络推荐任务,我们可能在训练中使用的是节点用户购买商品的数据,但我们却想知道节点用户是否想看某部电影,此时训练标签可能对测试就毫无作用了。因此,我们需要研究如何在没有标签的情况下训练 GNN。
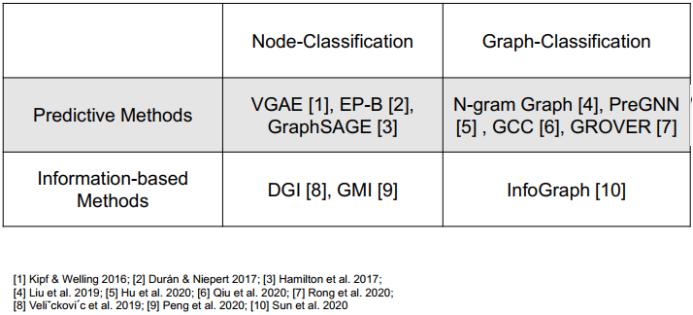
目前在自监督图学习方面已经有一些研究成果了。我们可以根据它们的机制将其分为两大类别:预测方法和基于信息论的方法。而根据所要解决的任务的差异,又可以分为两种情况:节点分类和图分类。
首先来看预测方法。Yann LeCun 说过:「自监督学习的系统是根据其输入的某些部分来预测输入的其它部分。」这就意味着在自监督学习中,输入的结构是很重要的。而图就是高度结构化的,因此天生就很适合自监督学习。
对于节点分类任务,实现自监督学习的方法通常有两种。一是强制使用相邻节点之间的相似性,二是基于邻近节点执行每个节点的重建。
首先,我们来看第一种方法,这种方法由 GraphSAGE 引入,其基本思想是强制每个节点与其邻近节点有相似的表征。在这种情况下,设 h_u 为 h_v 的邻近节点,则我们的目标是最大化它们的内积。我们称这些邻近节点为正例样本。然后,我们最小化 h_v 与通过负采样得到的其它节点之间的相似性,这些节点通常是从整个图均匀采样的。这样,我们就可以使用反向传播来训练 GNN 的参数了。
至于第二种方法,来自 Durán & Niepert 提出的 EP-B,其首先会计算邻近节点的表征的聚合。目标是最小化重建的结果与真实表征之间的距离。与此同时,又最大化这个聚合表征与其它节点的表征之间的距离。
EP-B 和 GraphSAGE 的主要区别是 EP-B 强制使用了邻近节点和每个其它节点的聚合之间的相似性,而 GraphSAGE 则直接强制使用了邻近节点与每个节点的相似性。
在图分类方面又有哪些方法呢?
我们要介绍的第一种方法是 N-Gram Graph。该方法分为两个阶段:节点表征阶段和图表征阶段。节点表征阶段使用了一种传统的自监督式节点嵌入方法 CBoW 来学习节点表征。在第二个阶段,由于已有节点表征,则首先会为每条长度为 n 的路径计算表征,称为 n-gram 路径。这个路径表征是以该路径中每个节点的表征的积形式得到的。因此,它们将历经图中所有的 n-gram 路径并归总所有路径的表征。最终的图表征是通过将 1-gram 到 T-gram 的路径连接起来而得到的。
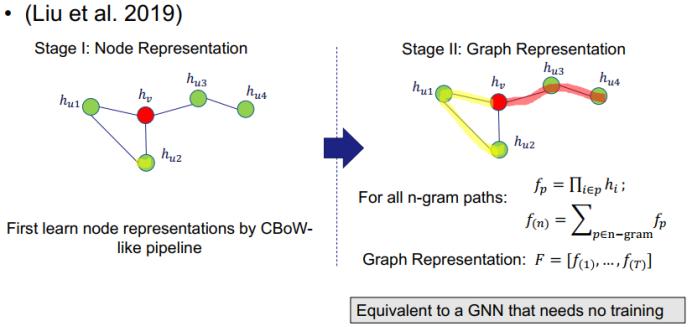
另一种用于图分类的方法是 PreGNN,它同样分为两个阶段:第一个阶段是执行节点表征(但使用了两种全新方法),第二阶段是使用简单的读出基于所有节点获取图层面的表征。但它是通过一种监督式策略交叉熵来训练图层面的表征。该研究指出,节点层面和图层面的训练对最终性能而言都很重要。
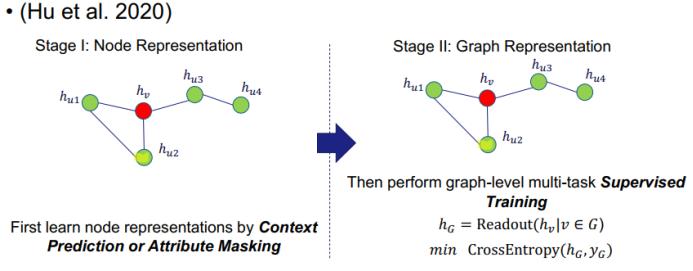
在这一阶段,PreGNN 提出了两种损失函数。周围结构预测(context prediction)是强制节点表征与其周围结构相似。另外我们还执行负采样来最小化 h_v 与其它节点的周围结构之间的相似性。这个方法的思路很简单:每个节点周围的结构定义了该节点的局部拓扑结构。
另一个损失则是属性掩码(attribute masking)。这个损失的设计灵感来自强大的 NLP 模型 BERT。简单来说,就是随机地使用掩码替换节点,然后构建训练损失函数来预测输入。方法很简单,但效果很好。
另一种值得一提的方法是 GCC。该方法使用了对比学习(contrastive learning)来执行图层面的无监督学习。不过 GCC 的一大主要问题是没有节点层面的训练。
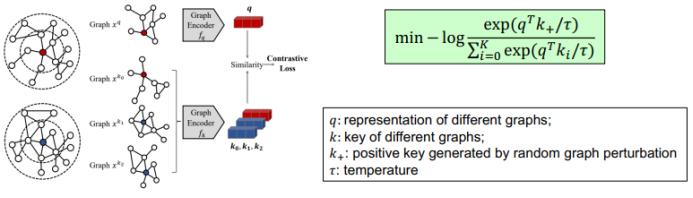
答案当然是肯定的。这就要谈到腾讯 AI Lab 研究团队提出的 GROVER 了。
GROVER 同样分为两个阶段。在节点阶段,我们还同时考虑了边,但为了说明简单,这里仅讨论节点表征过程。在这一阶段,首先为每个节点提取一个词典池。我们称之为 key。然后我们像 BERT 一样为每个节点加掩码,然后预测每个节点周围的局部结构。如果局部结构与词典中的一个 key 匹配,则在该维度上输出 1,否则便输出 0。注意这是一个多标签分类问题,因为每个节点的局部结构通常有多个。这样,我们仅需要一类掩码就能做到 PreGNN 的两件事。
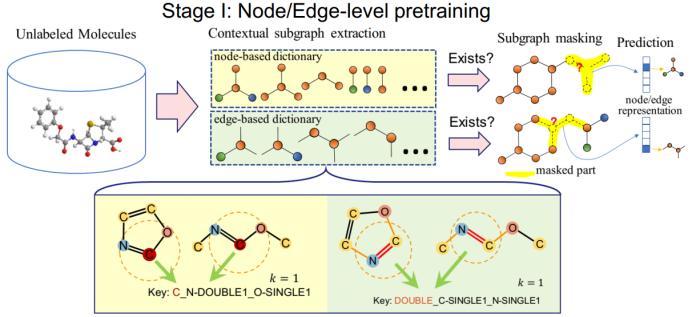
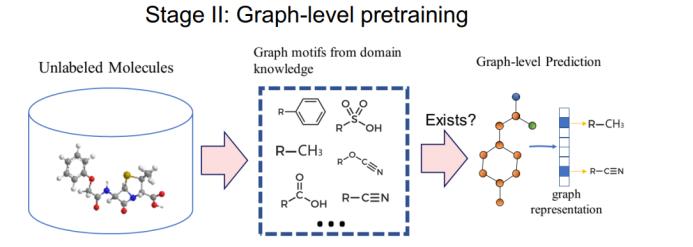
使用这个预训练的模型,我们可以针对下游任务进行微调。在此基础上,GROVER 可以取得显著优于 MPNN 和 DMPNN 等传统方法的表现,同时也优于 N-Gram 和 PreGNN 等自监督方法。
基于信息的方法
介绍了预测方法,我们再来看基于信息的方法。
优良的表征应该能将输入中的大量信息保存下来。受此启发,Vincent et al. 在 2010 年提出使用自动编码器来进行表征学习,这意味着隐藏表征应该可以解码到与其输入一样。
但自动编码器资源消耗高,既需要编码,也需要解码,而在图领域,如何解码图仍还是一个有待解决的问题。那么还有其它可以直接衡量表征与输入之间的信息的方法吗?有的,那就是互信息(mutual information)。
给定两个随机变量,互信息的定义是它们的边界属性和关节属性的积之间的 KL 散度,这又可以进一步推导为熵减去条件熵。
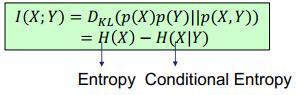
Hjelm et al. 2019 证明执行自动编码是计算互信息的重建误差的一个下限。
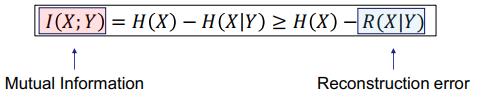

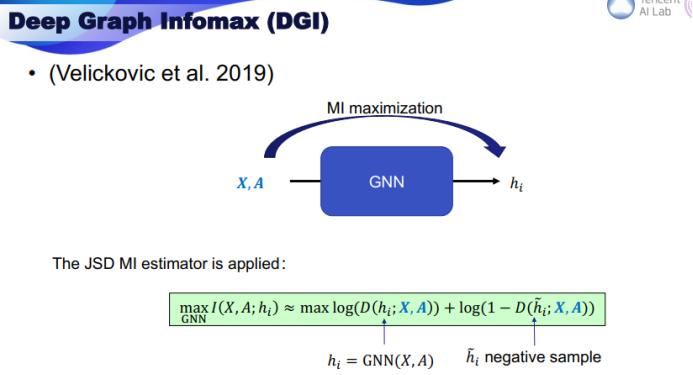
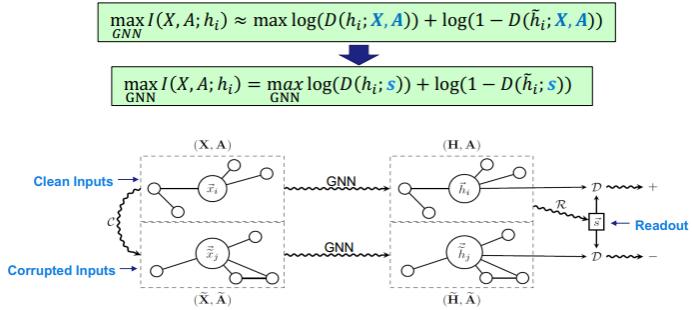
不过 DGI 仍还有一些问题。第一是它需要读出函数来计算互信息,而且这个读出函数需要是单射式的,这并不容易保证。另外它还需要构建错误的图来得到负例,因此效率不高。而在实验中,DGI 需要为不同的任务使用不同的编码器,这并不实用。
针对这些问题,清华大学、西安交通大学与腾讯 AI Lab 合作提出了 GMI,其基本思想是不使用读出函数和错误样本,而是直接计算互信息。
在 GMI 中,首先分两部分定义互信息。一是特征互信息,仅度量节点特征和表征之间的信息关系。二是拓扑互信息,这是预测的边和原始邻接矩阵之间的互信息。
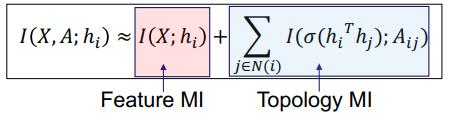
我们证明:特征互信息可以分解为局部互信息的加权和。而每个局部互信息计算的是每个节点及其表征之间的互信息。权重取决于不同的情况,将它们设置为与预测的边一样也不错。然后我们可以使用 JSD 互信息估计器来计算特征互信息和边互信息。

至于用于图分类的基于信息的方法,可参看 ICLR 2020 论文《InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization》,这里不再过多赘述。
三 图神经网络的应用进展
图神经网络作为一种有效的深度学习工具,已经在分子属性预测、生物学分析、金融等许多领域得到了应用。这里以腾讯 AI Lab 实现的在社交网络和医疗影像领域的应用为例,介绍图神经网络的应用进展。
1 用于社交网络的 GNN
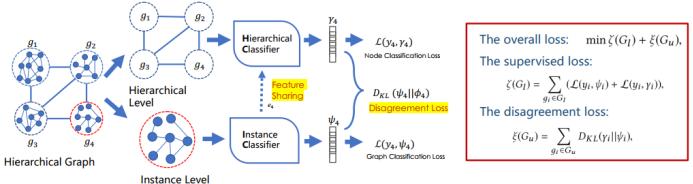
首先来看一篇 WWW 2019 论文《Semi-supervised graph classification: A hierarchical graph perspective》,其中腾讯 AI Lab 提出了使用分层图实现半监督图分类的方法。
分层图是指一组通过边互相连接在一起的图实例,如图所示:
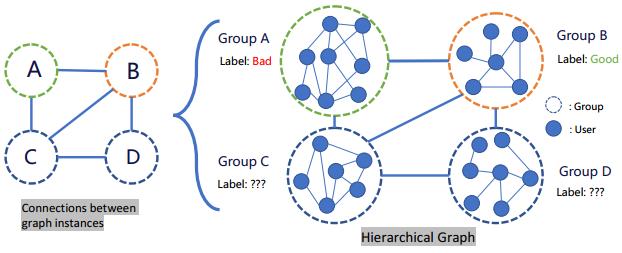
如果仅考虑组之间的联系,那么这个问题就又回到了节点分类。但是,可以看到每一组都有自己的用户图,忽略这样的信息并不合适。为了在用户和分组层面上利用图信息,我们面临着这样的难题:如何将任意大小的图表征为固定长度的向量?如何整合实例层面和分层层面的信息?
首先来看第一个问题。图表征与节点表征在不同的层面上;在节点层面上图 G 会被投射到大小为 n×v 的隐藏空间中;而在图层面上图 G 会被投射成大小为 v 的隐藏向量。因此,为了将节点层面的空间转换成图层面的向量,这里引入了自注意力图嵌入(SGAE)。
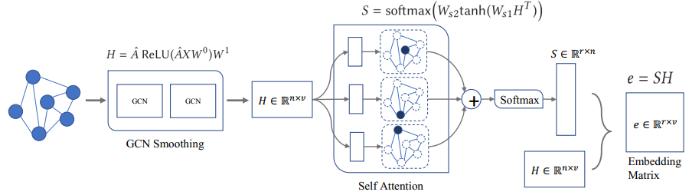
对于第二个问题:如何整合实例层面和分层层面的信息?这里实例层面是基于 SAGE 的图层面学习,分层层面模型是节点层面的学习。我们使用了特征共享来连接 SAGE 的输出和 GCN 的输入。然后又引入一种新的分歧损失(disagreement loss)来最小化实例分类器和分层分类器之间的不一致情况。
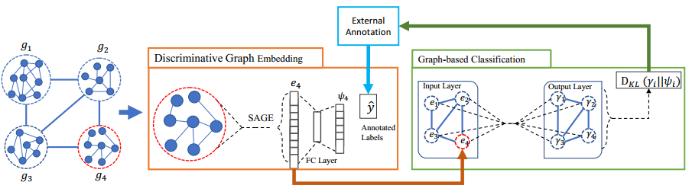
谣言可算是当今社会面临的一大顽疾。这篇论文提出通过关注和转发关系来检测社交媒体上的谣言。不管是谣言还是新闻,它们的传播模式都是树结构的。但通常来说,谣言的传播有两个属性。第一如下图 b 所示,其会沿一条关系链进行很深的传播。第二如图 c,谣言在社交媒体上传播时散布很宽。举个例子,一个 Twitter 用户可能有大量关注者。
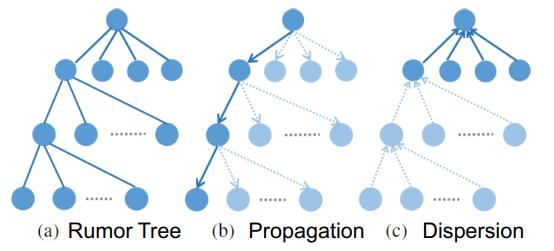
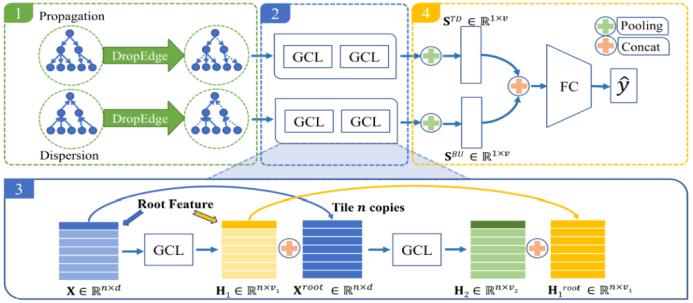
此外,我们还评估了谣言的早期侦测,此时仅给出谣言树上非常有限的节点并且还设置了一个侦测截止时间,结果表明基于图的方法非常适用于早期发现谣言。
2 用于医疗影像的 GNN
医疗影像也是 GNN 的一个重要应用场景,腾讯 AI Lab 近两年在这一领域取得了一些重要的研究成果。首先来看腾讯 AI Lab 的 MICCAI 2018 论文《Graph CNN for Survival Analysis on Whole Slide Pathological Images》,其中提出使用图卷积网络基于全切片病理图像进行生存分析。
生存分析的目标是预测特定事件发生的风险,这类事件包括器官衰竭、药物不良反应和死亡。有效的分析结果具有重要的临床应用价值。但实际操作时却面临着许多困难。
首先,全切片病理图像(WSI)分析是一个需要大量计算的过程,因为单张 WSI 的数据量就超过 0.5 GB,而且其中包含数百万个细胞,还涉及局部特征和全局特征,因此非常复杂。另外,如何将 WSI 的拓扑特征用于生存分析也还是一个有待解决的问题。
为此,我们提出将 WSI 建模成图,然后开发了一种图卷积神经网络(Graph CNN),其使用了注意力机制,可通过提供 WSI 的最优图表征来实现更好的生存分析。
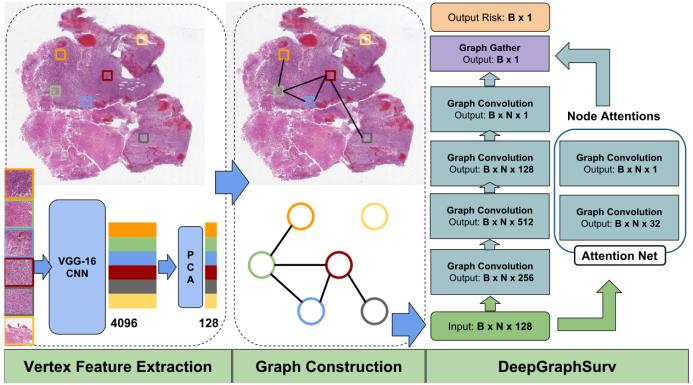
这一部分同时也介绍了近年来 GNN 在医疗图像上的其他工作:在 IPMI2019 发表的《Graph Convolutional Nets for Tool Presence Detection in Surgical Videos》中,作者提出使用 GCN 来检测手术视频中的工具,这是自动手术视频内容分析的核心问题之一,可用于手术器材使用评估和手术报告自动生成等应用。这个模型使用了 GCN 沿时间维度通过考虑连续视频帧之间的关系来学习更好的特征。
而在 MICCAI 2020 发表的论文《Graph Attention Multi-instance Learning for Accurate Colorectal Cancer Staging》中,作者提出使用图注意力多实例学习来准确判断结直肠癌是处于早期、中期还是晚期。
总结和展望
在这次课程中,我们介绍了图神经网络的发展历史、包括图神经网络的表达能力、深度、大规模扩展、自监督 / 无监督学习等方面的研究进展,也简要介绍了腾讯 AI Lab 在图神经网络的社交网络和医疗影像应用方面的一些初步成果。
图深度学习领域仍处于发展之中,有很多有趣的问题等待解决,例如逆向图识别(IGI),即我们在图分类问题中,是否可以根据图的标签来推断每个节点的标签?子图识别,即如何在图中找到关键的子图同时还有图与多示例学习问题的结合形成多图示例学习问题,以及在图上进行攻击与防御相关的图深度学习鲁棒性的研究。最后,层次图也是一个热门的研究方向。图神经网络必将在人工智能领域未来的研究和应用中扮演更重要的角色。
如何快速构建图片搜索引擎?
亚马逊AWS解决方案架构师邱越俊将于9月24日带来一场live coding,利用Amazon Elasticsearch Service,从零开始构建一个以图搜图的应用程序,包括用Amazon SageMaker对图片做特征向量提取,用Amazon Elasticsearch做特征向量搜索,用AWS Amplify快速搭建应用程序。
原标题:《腾讯AI Lab联合清华、港中文,万字解读图深度学习历史、最新进展与应用》