谷歌训练BERT只用23秒,英伟达A100打破八项AI性能纪录,最新MLPerf榜单出炉

机器之心报道
编辑:泽南、张倩
在最新的 MLPerf 基准测试结果中,英伟达新出的 A100 GPU 打破了八项 AI 性能纪录,谷歌的 4096 块 TPU V3 将 VERT 的训练时间缩短到了 23 秒。华为昇腾 910 这次也跑了个分。

在今天官方发布的 MLPerf 第三批 AI 训练芯片测试结果中,英伟达 A100 Tensor Core GPU 在全部八项基准测试中展现了最快性能。在实现总体最快的大规模解决方案方面,利用 HDR InfiniBand 实现多个 DGX A100 系统互联的服务器集群 DGX SuperPOD 系统也同样创造了业内最优性能。
行业基准测试组织 MLPerf 于 2018 年 5 月由谷歌、百度、英特尔、AMD、哈佛和斯坦福大学共同发起,目前已成为机器学习领域芯片性能的重要参考标准。此次结果已是英伟达在 MLPerf 训练测试中连续第三次展现了最强性能。早在 2018 年 12 月,英伟达就曾在 MLPerf 训练基准测试中创下了六项纪录,次年 7 月英伟达再次创下八项纪录。
最新版的 MLPerf 基准测试包含 8 个领域的 8 项测试,分别为目标检测(light-weight、heavy-weight)、翻译(recurrent、non-recurrent)、NLP、推荐系统、强化学习,参与测试的模型包括 SSD、Mask R-CNN、NMT、BERT 等。MLPerf 在强化学习测试中使用了 Mini-go 和全尺寸 19×19 围棋棋盘。该测试是本轮最复杂的测试,内容涵盖从游戏到训练的多项操作。

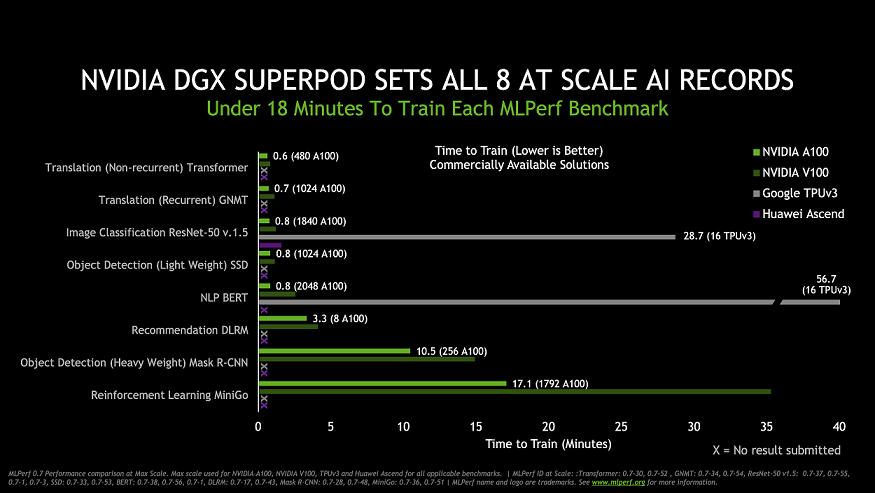
安培架构,市场采用速度刷新纪录
今年 5 月在 GTC 大会上正式发布的 A100 是首款基于安培架构的处理器,它不仅打破了 GPU 性能纪录,其进入市场的速度也比以往任何英伟达 GPU 更快。A100 在发布之初用于 NVIDIA 的第三代 DGX 系统,正式发布仅六周后就正式登陆谷歌云服务系统。
目前,AWS、百度云、微软 Azure 和腾讯云等全球云提供商,以及戴尔、惠普、浪潮和超微等数十家主要服务器制造商,均已推出基于 A100 的云服务或服务器产品。
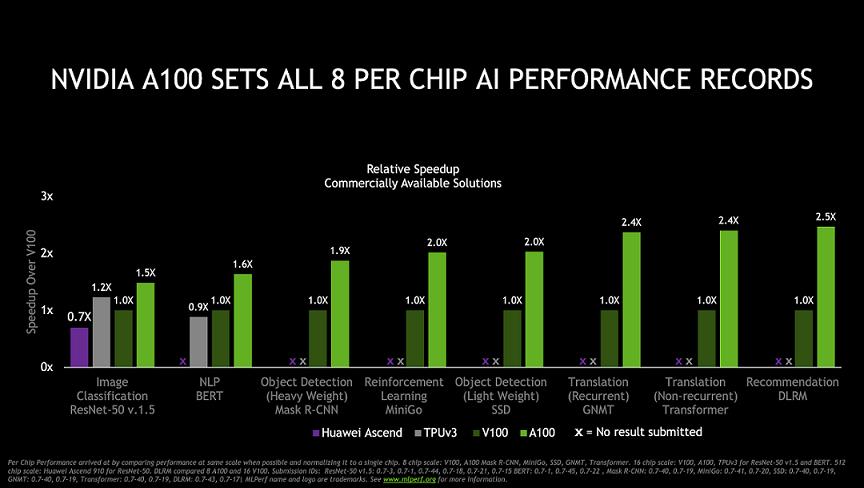
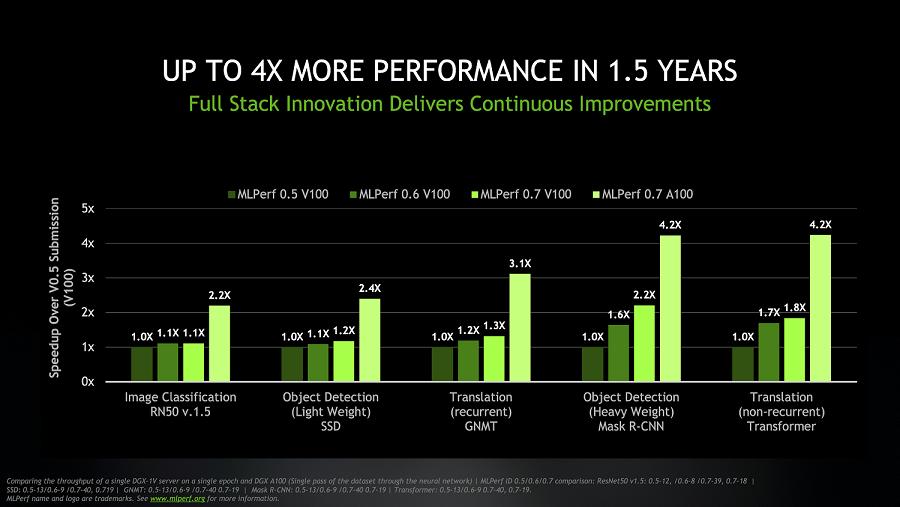
英伟达 GPU 性能的提升不仅来自硬件。测试结果显示,相较于首轮 MLPerf 训练测试中使用的基于 V100 GPU 的系统,如今的 DGX A100 系统能够以相同的吞吐率,实现高达 4 倍的性能提升。同时,得益于最新的软件优化,基于 NVIDIA V100 的 DGX-1 系统亦可实现高达 2 倍的性能提升。
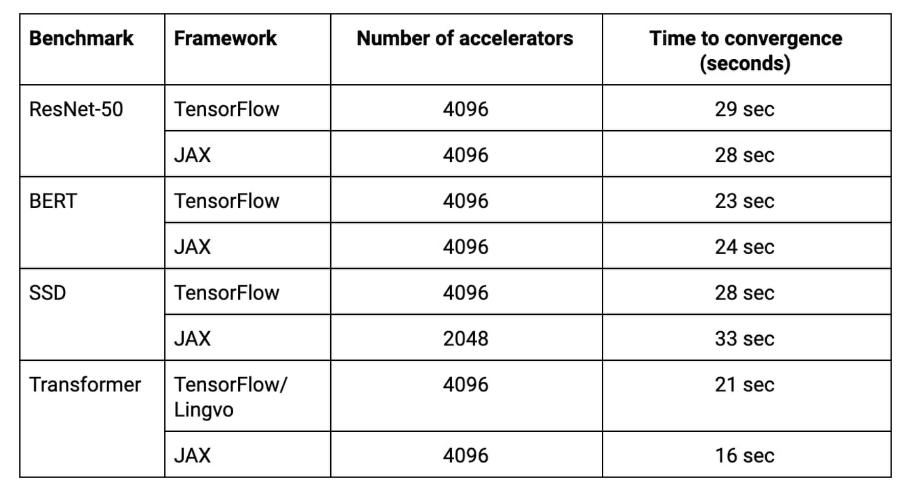
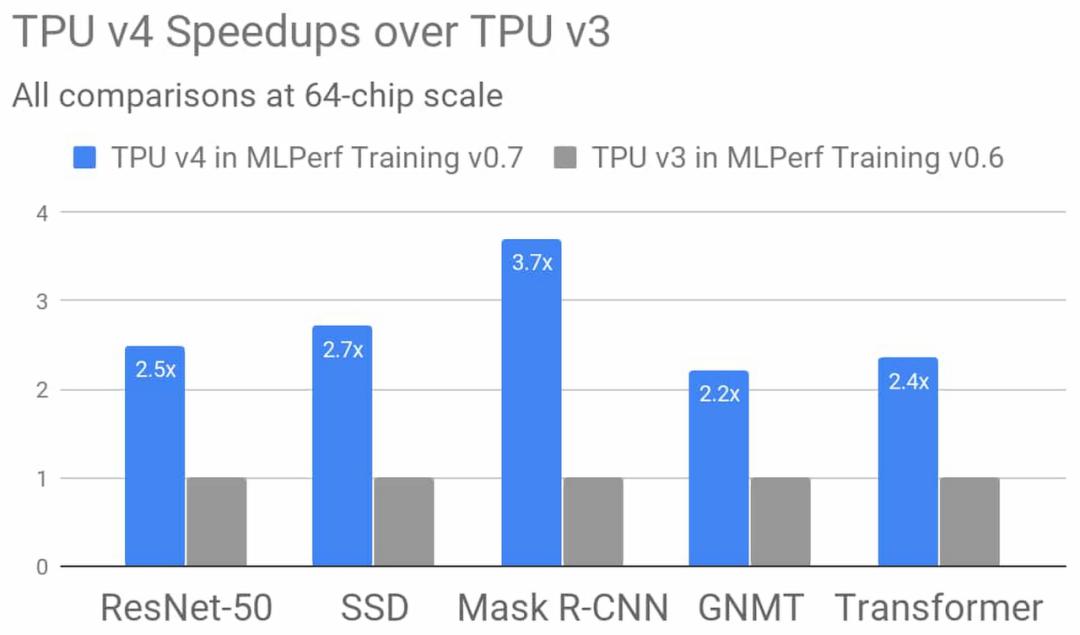
在最新的 MLPerf 测试结果中,谷歌的 TPU 加速器也获得了很好的成绩:在预览和测试组别中,TPU 集群打破了 8 项测试纪录中的 6 项,4096 块并联的 TPU v3 可以实现高达 430 PFLOPs 的峰值算力,训练 ResNet-50、BERT、Transformer、SSD 等模型都可以在 33 秒内完成。

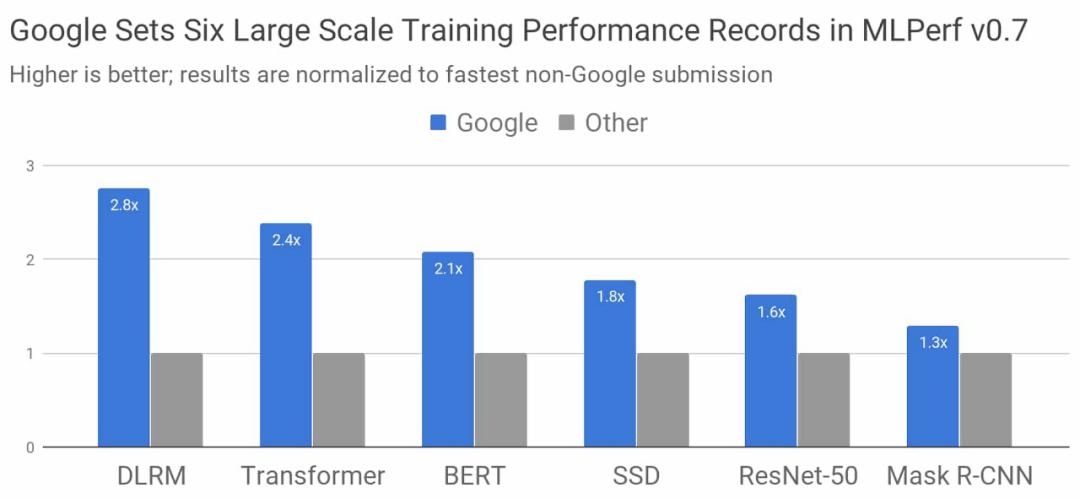
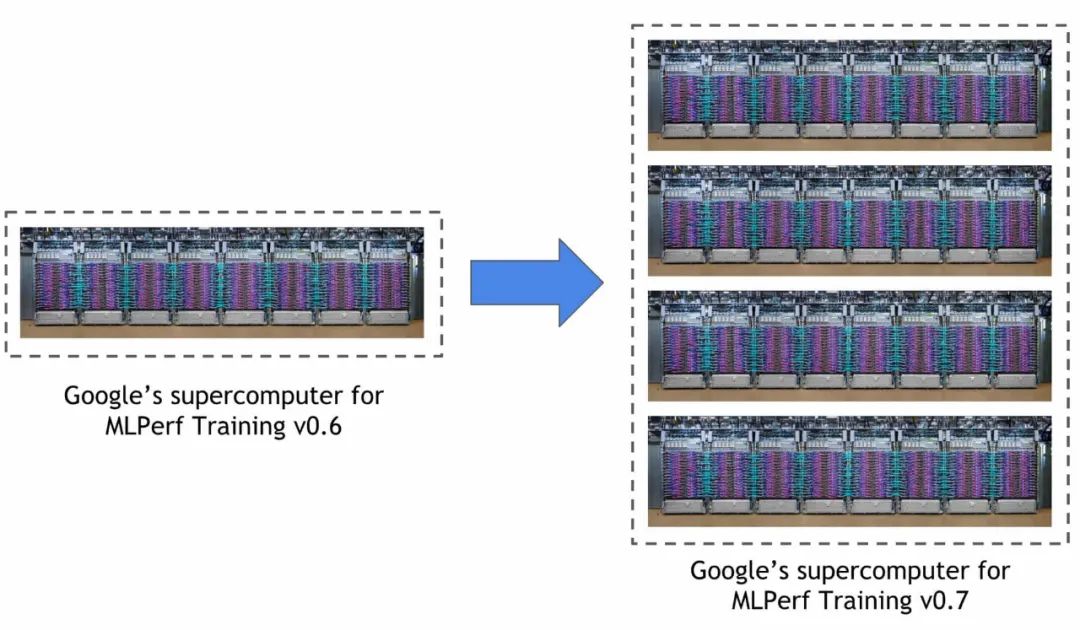
谷歌在本次 MLPerf 训练中使用的超级计算机比在之前比赛中创下三项记录的 Cloud TPU v3 Pod 大三倍。该系统包括 4096 个 TPU v3 芯片和数百台 CPU 主机,峰值性能超过 430 PFLOPs。
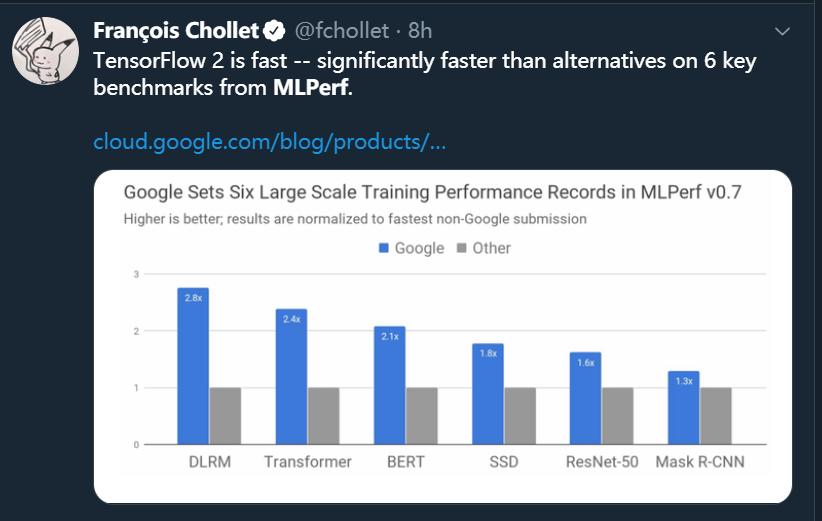

https://cloud.google.com/blog/products/ai-machine-learning/google-breaks-ai-performance-records-in-mlperf-with-worlds-fastest-training-supercomputer
https://blogs.nvidia.com/blog/2020/07/29/mlperf-training-benchmark-records/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+nvidiablog+%28The+NVIDIA+Blog%29
https://mlperf.org/training-results-0-7
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《谷歌训练BERT只用23秒,英伟达A100打破八项AI性能纪录,最新MLPerf榜单出炉》