只有加法也能做深度学习,北大、华为等提出AdderNet

关注前沿科技 量子位
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在深度学习里,乘积是个避免不了的运算,比如做图像识别的卷积层,就需要做大量的乘法。
但是,与加法运算相比,乘法运算的计算复杂度高得多。
现在的深度学习在很大程度上依赖于GPU硬件,做大量的乘法运算,限制了它在移动设备上的应用,需要一种更高效的方法。

来自北京大学、华为诺亚方舟实验室、鹏城实验室的研究人员提出了一种加法器网络AdderNet,去掉卷积乘法,并设计一种新的反向传播算法,结果也能训练神经网络。
而且实验结果证明了,这种方法在MNIST、CIFAR-10、SVHN上已经接近传统CNN的SOTA结果。
加法网络早已有之
早在2015年,Bengio等人就提出了二元权重(1或-1)神经网络,用简单的累加运算来代替乘法,提高深度学习硬件的运行效率。

尽管将深度神经网络二元化可以极大地降低了计算成本,但是原始识别精度经常无法保持。另外,二元网络的训练过程不稳定,并且通常收敛速度较慢。
卷积通常作为默认操作从图像数据中提取特征,若引入各种方法来加速卷积,则存在牺牲网络性能的风险。
如何让避免CNN中的乘法呢?研究人员使用L1了距离。L1距离是两点坐标差值的绝对值之和,不涉及乘法。

研究人员在此基础上提出了加法器网络AdderNet,下图展示了AdderNet和CNN的不同之处:

可视化的结果表明,L1距离可用作深度神经网络中滤波器与输入特征之间距离的相似性度量。滤波器和输入特征的距离可以表述为:

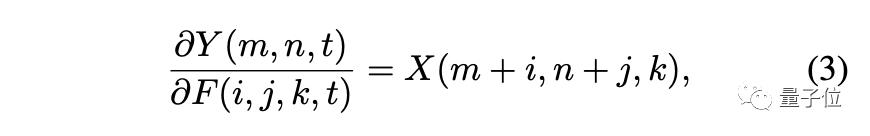
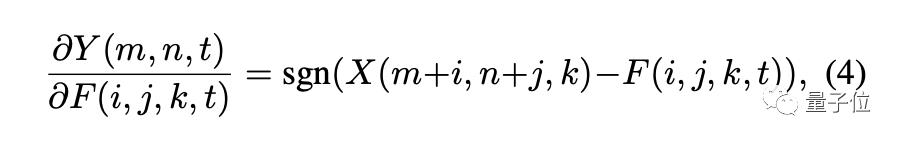
由此进行优化的方法叫做符号SGD(signSGD)。但是,signSGD几乎永远不会沿着最陡的下降方向,并且方向性只会随着维数的增长而变差。因此要使用另一种形式的梯度:
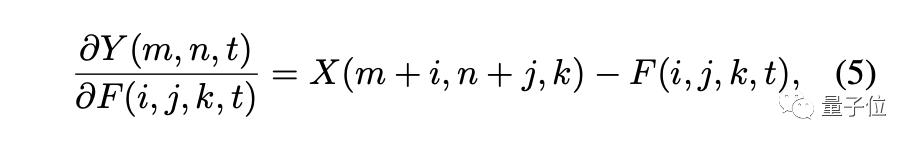

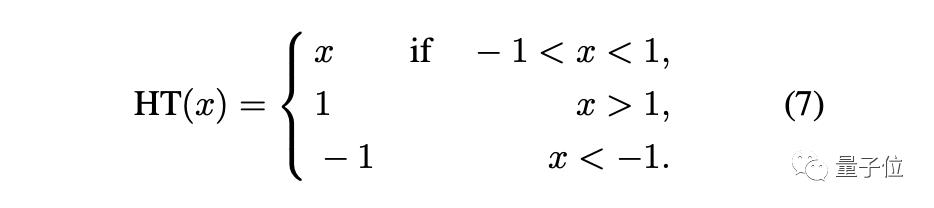

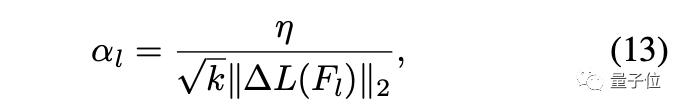
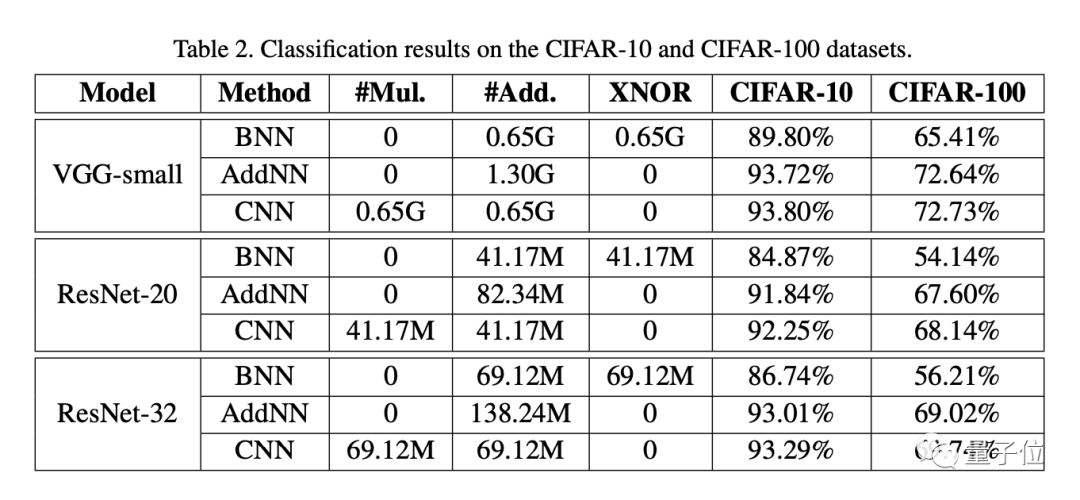
最后,在CIFAR-10的图像分类任务中,AdderNet相比原始的二元神经网络BNN性能有大幅的提升,并且性能已经接近了传统CNN的结果。
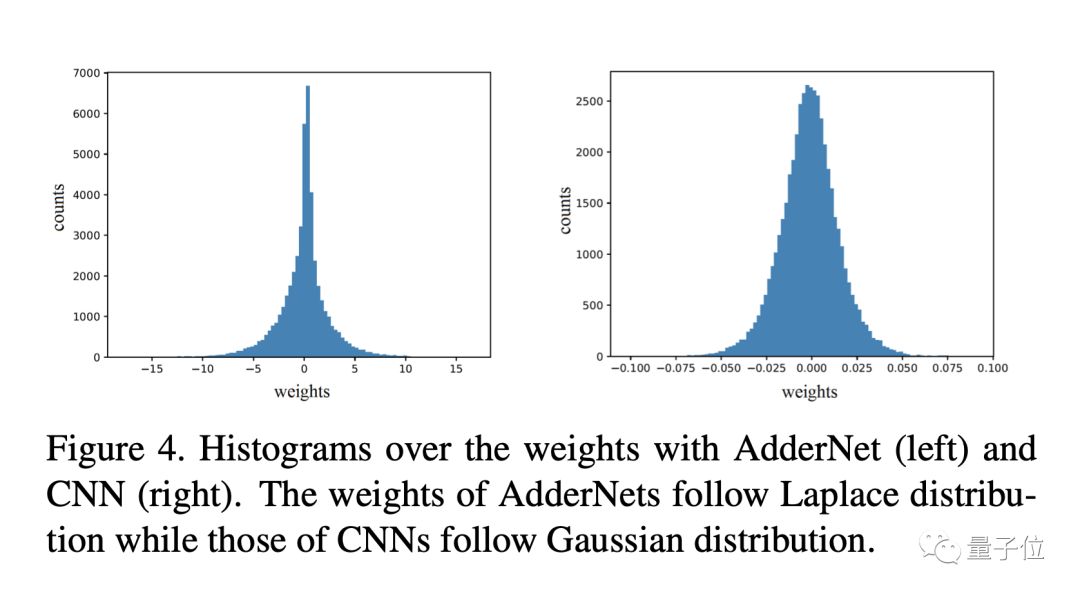
遭网友diss
这篇文章发布到网上后,引发了Reddit论坛机器学习板块的热议。
有网友认为,文章以提高运算性能为目的,但在结尾只提到了图像分类认为的正确率,不免让人感到文不对题。
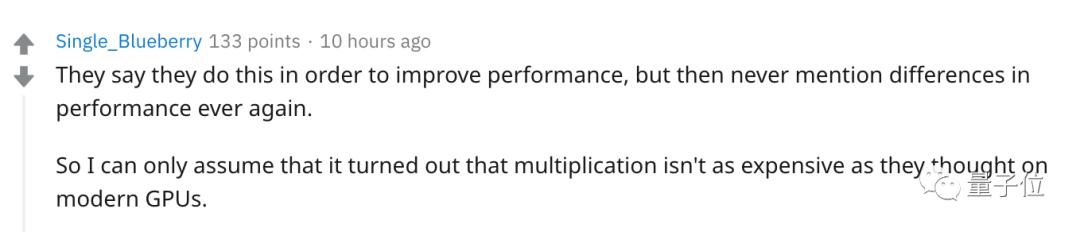
而且现在各种专用AI芯片、FPGA都对深度学习任务做了优化,算浮点乘法并不一定与加法消耗资源相差太大。
论文链接:
https://arxiv.org/abs/1511.00363
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
原标题:《只有加法也能做深度学习,北大、华为等提出AdderNet,性能不输传统CNN》