看懂这十步,8岁的小朋友都能理解深度学习

郭一璞 编译
量子位 出品 | 公众号 QbitAI
在对技术毫无了解的人看来,人工智能是什么?
《流浪地球》里的AI语音助手MOSS么?还是《终结者》里的天网?
如果对当今人工智能的主流技术——深度学习没有了解,可能真的会有人觉得,当前的科学家们在创造无所不能、无所不知的电影AI形象。
那么,如何用最浅显的方式,给大众解释什么是深度学习呢?
法国博主Jean-Louis Queguiner撰写了这篇《给我8岁的女儿解释深度学习》,以用深度学习技术搭建识别手写数字的神经网络为例,用清晰的方式,解释了深度学习的原理。

1、和数数一样简单
首先,考虑到0~9这十个数字,本身也是存在各种笔画的,那我们就拆解开来,看每个手写体数字里,有多少横竖撇捺,曲折弯弯。
左边竖着的一列是是个数字,上方横着的红色字符则是拆解出来的笔画,用这个表格,来统计每个字符里有多少个相应的笔画。
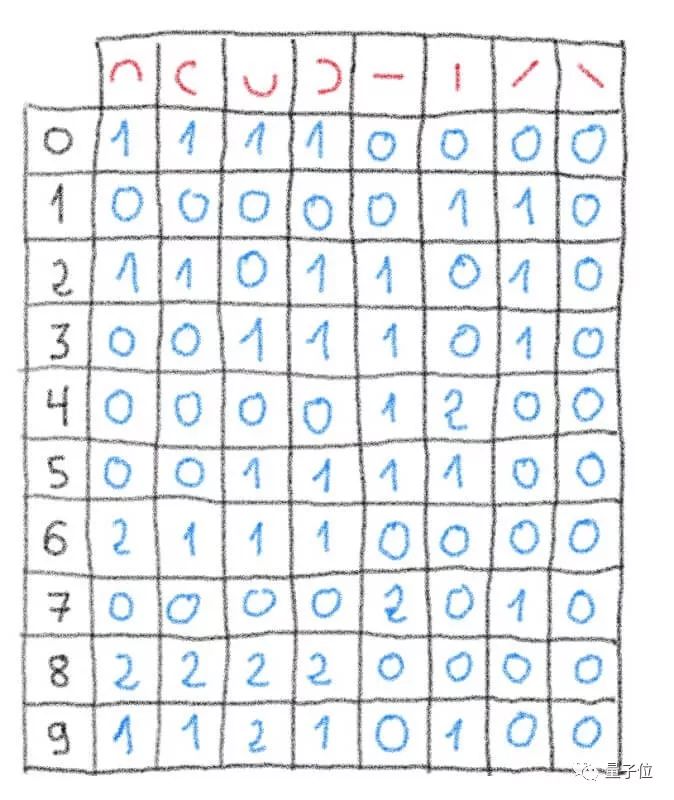

比如,第一个数字里,有一个“ / ”,一个“丨”,我们发现有这种特征的,是“1”这个数字,而且完全符合,那第一个数字就是“1”。
第二个数字,上下左右半圆各有2个,另外还有一个“ / ”,一个“丨”,总共10个笔画。比较之下,会发现上表中的数字“8”有8个笔画符合,数字“9”有6个笔画符合,那么这第二个数字就是“8”。
看懂这一步,那恭喜你已经搭建了世界上最简单的识别手写数字神经网络。
2、图像即矩阵
矩阵这个概念,大部分8岁的小学生肯定是没学过的,可以简单的理解为一串横竖的格子里,每个放一个数。
对于计算机来说,每张照片都是细微的像素组成的,这些像素排列成矩阵格子,每个格子一个颜色,拼起来便是一副图像。
比如这些红红绿绿的格子,你缩小来看,原来是一张草莓图片的一部分。
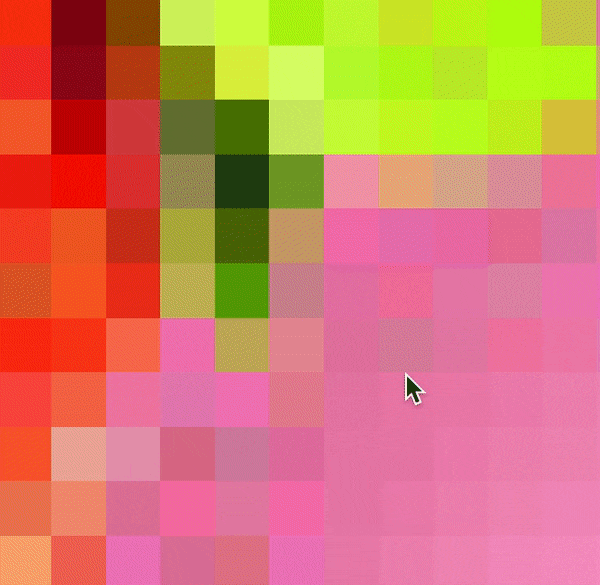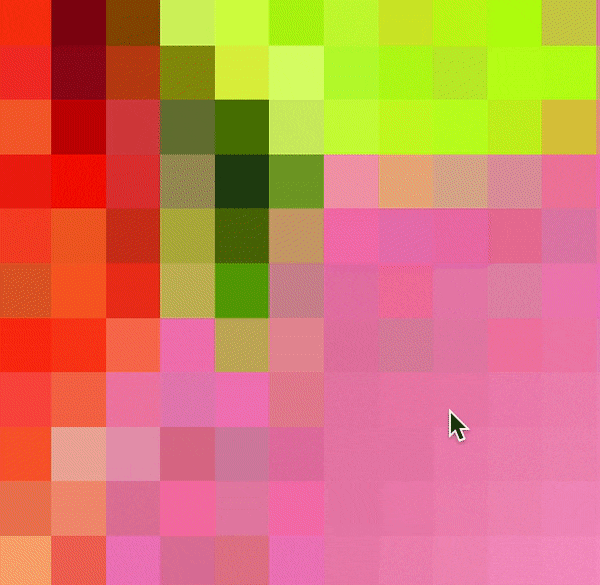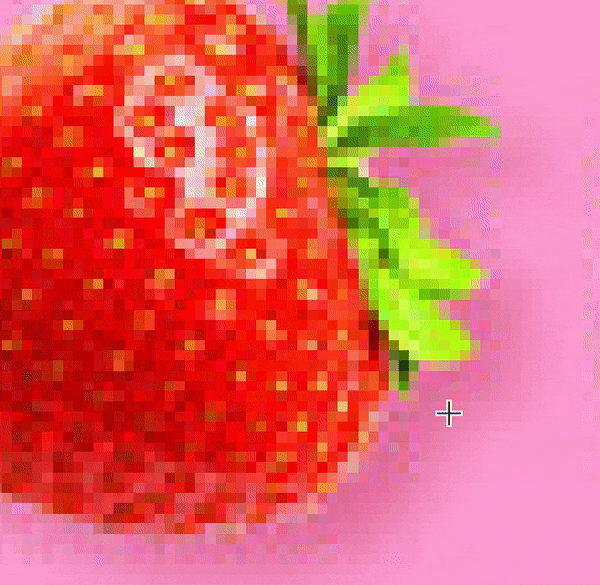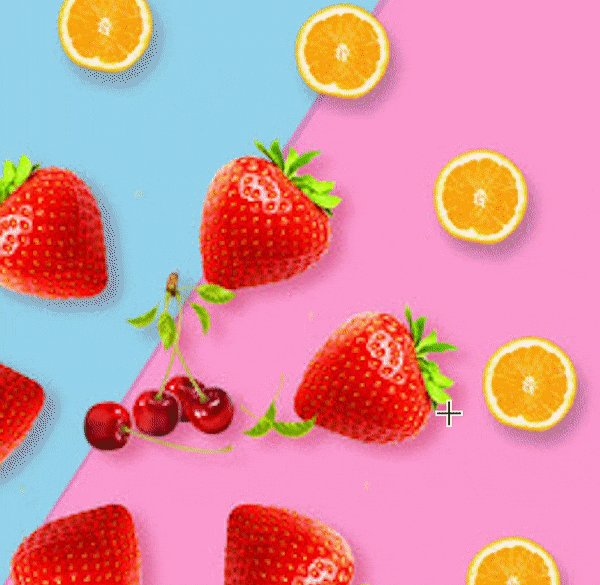
而颜色,对于计算机来说,正是用数表示的,草莓图片中彩色的颜色是红绿蓝三种色光,各自有一个数,总共三个数;而手写数字都是黑白的,只要一个数,0表示纯黑色,255表示纯白色,两者中间的数则是灰色,数字越小颜色越深,数字越大颜色越浅。
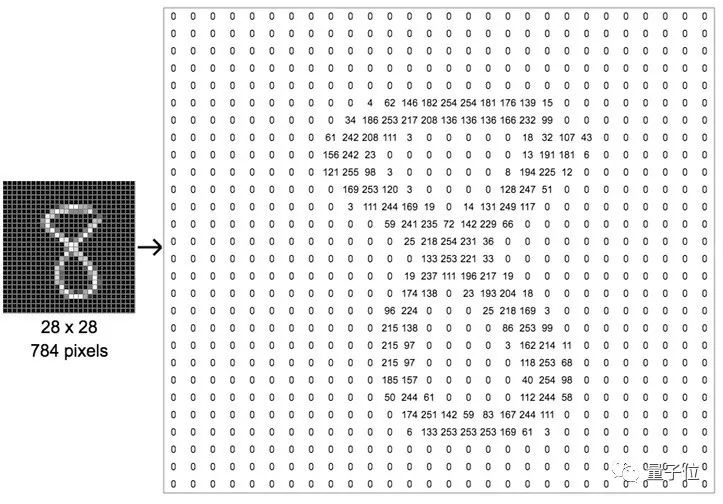
所以,看这个手写数字,一共28行28列,784个像素格子,没有笔画的黑色格子就是0,有笔画的部分,笔画中心是更浅的白色,数字在一两百左右,笔画边缘则是灰色,数字只有几十,这就构成了这个手写数字的矩阵。
3、卷积层:找到笔画轮廓
现在,我们知道了图片的每个像素格子都是数字,但如何找出这些数字中的笔画呢?
深度学习的神经网络是有许多许多“层”组成的,找轮廓这一步需要用到卷积层,本质上就是在前面用数字表示的图像上加一个过滤器,把没有笔画的部分过滤掉,留下有笔画的部分。
过滤器就像下面这个玩具一样,识别出图案的轮廓,如果轮廓匹配,就可以放进盒子里,轮廓不匹配,那就放不进去,三角形的过滤器匹配三角形的木块,正方形的过滤器匹配正方形的木块

过滤器过滤的过程就像这张动画一样,每一次扫描都是独立的,所以可以同时进行许多次扫描,每次扫描互不干扰。

前面的过程,是我们的手写数字图像被多个过滤器过滤,但是为了提高准确性,只要把前一次过滤的图像再拿来过滤就好了,用的过滤器越多,过滤的次数越多,结果越准确。
而且,由于手写的数字并不像玩具中的三角形、五角星一样规整,每个人写数字“8”都可能写成不同的样子,因此笔画的布局都不一样。
为了让过滤出来的笔画更清晰,需要不断创建新的过滤器,直到过滤器被精确到我们前面看到的那些红色横竖撇捺半圆的形状。
6、卷积:乘法和加法
但过滤中具体的扫描过程是怎样的呢?
涉及到卷积运算,比如下图,左边是一张8×8的图像,中间是一个3×3的卷积滤波器,3×3的格子在8×8的图像上逐一移动,挨个进行卷积。
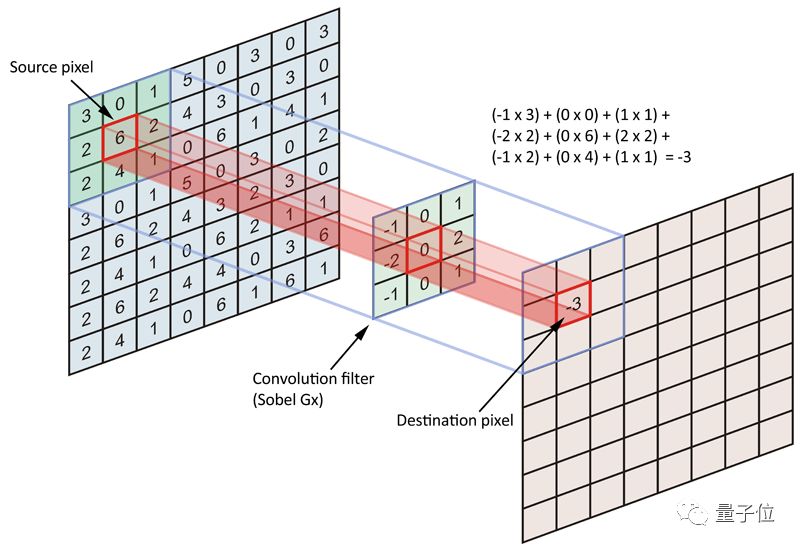
这里,需要告诉大家卷积是怎样算的。比如上图,左边的3×3格子的左上角是3,中间卷积过滤器的左上角是-1,那就需要把3和-1乘起来,得到-3。以此类推,同一位置的两个数相乘,得到9个乘积,再把9个乘积加起来,得到-3,就是卷积的结果。
当然,图上这个例子中涉及了负数,如果小朋友还没有学会负数的运算,可以先不要理它,当做一个整数就好啦。
7、池化层:把图片变小,易于总结
经过了复杂的卷积过程,我们现在需要进行总结采样,首先要把矩阵缩小,这里用到的是池化层。

比如,把四个格子缩成一个格子,可以取四个格子的最大值、最小值、平均值、求和等,这样矩阵的大小就只有原来的四分之一了。
8、神经网络
我们整个过程,是为了识别手写的数字是几,这个过程叫做图像分类,因为数字只有10个,所以需要把每个不同的手写数字分到0~9十类中。
经过了上面的多层处理,现在需要把它放进类中,需要准备10个神经元,每个代表一类,连接到最后一个池化层之后。
下面是Yann LeCun设计的最早的LeNet-5卷积神经网络,这是图像识别领域的几个早期成果之一。

不过,整个过程不只靠卷积完成,还需要依靠神经网络自身学习和适应的能力,比如借助一种叫做反向传播的方法,靠权重来减少神经元的数量。
简单来讲,我们看神经网络的输出的结果,如果输出的这个分类是错的,比如把手写的6认成了9,我们就认为,其中有一个过滤器犯了个错误,是个不靠谱的过滤器,担不起自己的责任,就把它的权重降低,下次神经网络就不会犯同样的错误了。
这样,整个神经网络系统就拥有了学习能力,保持自我提升。
10、写在最后
找了数千张图片,运行了数十个过滤器,采样输出……所有的步骤都可以完美的同时搞定,因此适合在GPU上运行。
另外,我们还没有讨论准确率的问题,在图像识别竞赛ImageNet中,根据历年的结果,我们可以看出,随着神经网络层数的增加,准确率在不断提升。
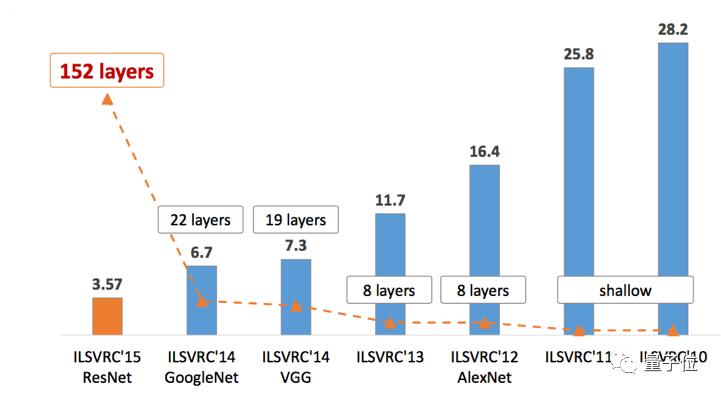
最后,本文讲得虽然是识别手写字母,但所有的图像识别,无论是用于医疗还是用于自动驾驶,原理都是一样的,靠很多层神经网络、各种滤波器,在不同的矩阵上做各种变换。
也就是说,所有图像识别都是在GPU上运行的矩阵运算。 传送门
英文原文:
https://www.ovh.com/blog/deep-learning-explained-to-my-8-year-old-daughter/
— 完 —