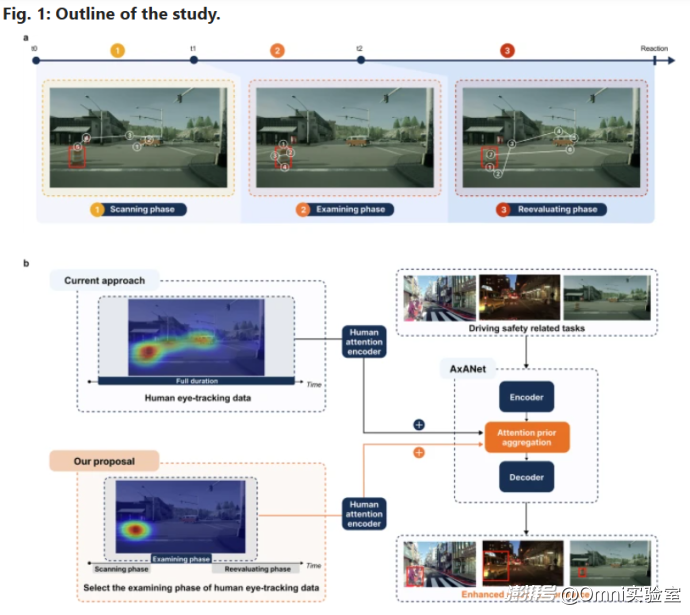
清华大学研究成果登刊:拆解为什么人类司机比智能驾驶安全?


自动驾驶已经不是一个新鲜事儿,但一直存在一个矛盾,算法能看清路标的每一个物体,却可能理解不了存在的潜在风险。
虽然现如今AI行业大量拼算力、参数,但面对复杂场景的时候仍然不好避免其中的安全问题。
近期清华大学人工智能研究院AIR团队在《npj Artificial Intelligence》发布最新研究成果,给出了一个相对务实的解决方案。
研究通过眼动实验、多算法验证、首次量化拆解人类和算法的注意力差异,并且用数据证明了不需要堆参数和算力,融入人类驾驶“核心注意力阶段”特征,就能提升算法安全性,相关技术已经提交专利,未来有可能完成快速落地。
整个研究成果论文逻辑清晰,共分三步推进。
第一步是开展人类驾驶注意力量化实验
实验共招募了36名实验者(18名驾龄超5年的老手、18名驾龄不足1年的新手)对比驾驶经验对注意力的影响,所有驾驶员都在模拟驾驶环境里,完成“找危险”“看能不能过”“认异常东西”这三件事儿,同时用高精度仪器记录他们看哪里、看多久。
通过实验,我们第一次弄清楚了人开车时的注意力有三个阶段:
第一个阶段是快速扫一眼路况,找到关键目标(比如行人、红绿灯),平均就观看的时间为0.186秒左右,老司机和新手差别不大,这种能力算法也能模仿。
第二个阶段是盯着关键目标仔细看,判断它有没有风险(比如行人会不会过马路),老司机平均看0.706秒,新手只看0.623秒,通过实验来看,老司机判断得更准,这是老司机和新手的差距,也是现在自动驾驶算法最欠缺的能力。
第三阶段是看完关键目标后,再确认一下周围环境,避免决策出错,相当于人开车时的纠错环节。通过实验结果来看,新老司机平均看0.248秒,而且路况越复杂看得越久,这个环节也是老司机确认得更准。
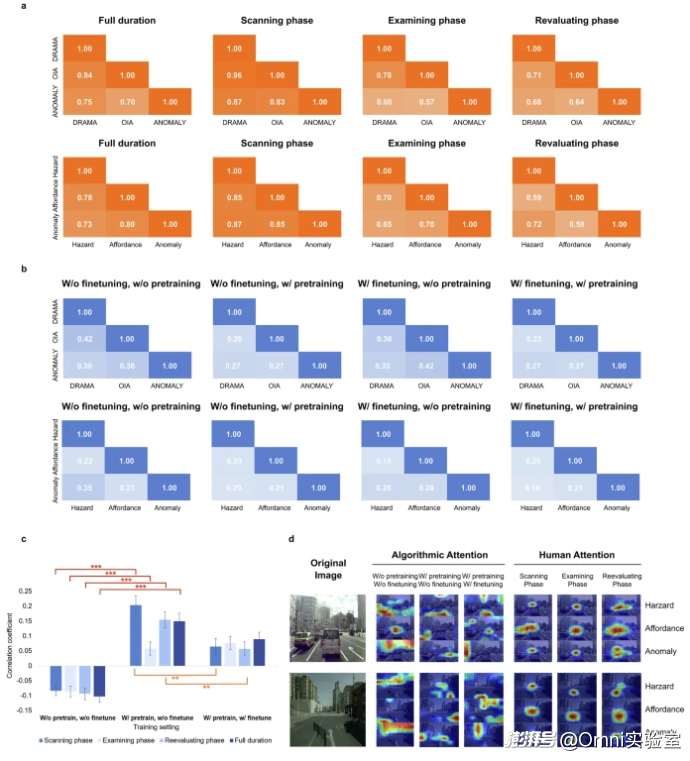
第二步是把人的注意力和自动驾驶算法的注意力做了对比
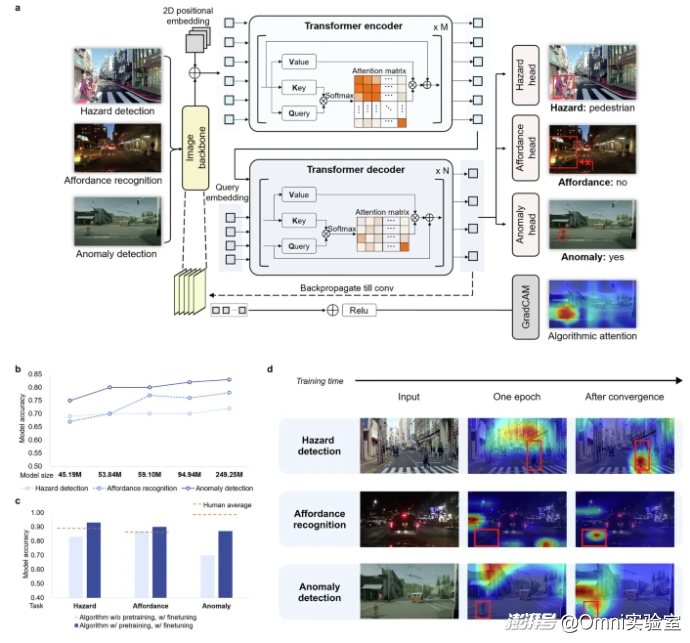
这一步用了现在行业里最常用的几种算法。通过实验发现两个大问题,第一个问题是算法只会“看见”,但不会“看懂”,能认出东西是什么,但不知道哪个更危险、更重要;第二个是算法虽然能讲道理,但很难精准对应到真实路况(比如你问题有行人通过要减速吗?他会跟你说要减速,但到了真实的环境里,它很难分辨行人具体在马路哪个位置、离车多远)。
而且算法自己怎么学,都很难学会人类的会看重点、能懂风险的能力,只有学会人类仔细观察、判断风险这一步时,效果才稳定。
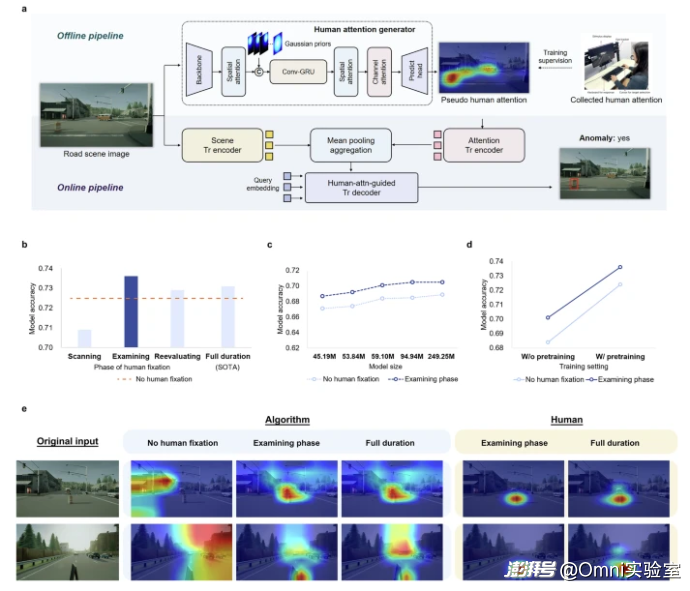
第三步是把人类开车时的注意力规律,教给算法,结果很明显。
(1)让算法学会人类仔细判断风险的方式,危险识别更准了
(2)让算法学人类随便扫一眼的方式,反而更不准
(3)在轨迹规划和避障上,车开得更稳、碰撞风险更低,而且不用加算力、不用加大模型。
(4)对负责理解场景的AI模型,也能让它描述得更准、更贴合真实路况。
清华大学这项研究的核心意义是给出了比较务实的轻量化解决方法,重新定义了自动驾驶的类人化——模仿人类认知逻辑,而不是单纯模仿操作。
为行业打开新思路,人工智能的发展,既要向外追算力,更要向内学人类认知。
部分实验图集