“龙虾潮”中的冷思考:谁来为智能体“上保险”?上海邮电经济研讨会热议智能体评测


三月底的上海,由OpenClaw(开源智能体,昵称“龙虾”)掀起的“养虾热”席卷浦江两岸。在3月27日举行的全球开发者先锋大会(GDPS)上,“龙虾”是最热的关键词之一,抱着电脑“装龙虾”的市民排着长长的队伍。
然而,同日由上海邮电经济研究会举办的2026年一季度学术研讨会上,一群来自高校、科研院所、电信运营商等单位的专家却在讨论另一个问题——这些“龙虾”是否安全?智能体的能力与安全又该如何评测?

“至少在当前,智能体的能力并没有那么可靠,”上海计算机软件技术开发中心人工智能治理研究所副所长陈敏刚表示,据Claw-Eval智能体测评基准最新最新测评结果显示,即便是当前最强的商业基座模型,在104项真实世界任务中三次连续全部成功的通过率也只有70.8%。
上海人工智能实验室安全可信AI中心青年研究员汪旭鸿则将智能体安全评测分为L1至L5五个等级:“现在大部分机构做的都是L1和L2的测评,突破L3需要各行各业共同搭建基础设施,单个测评机构很难凭一己之力完成。”
“如果AI的可信度不高,它是不是依旧是一个玩具,抑或只是大家的谈资?评测结果能否成为智能体产品化的前提?”上海邮电经济研究会会长、中国电信上海公司副总经理马明抛出了一个AI落地时的“灵魂拷问”。

研讨会上透露,上海市正在制定一项关于“智能体评测指标与方法”的团体标准,预计今年上半年将对外发布。
本次研讨会由上海邮电经济研究会副会长、上海交通大学教授、博士生导师朱杰主持,副会长、上海通信管理局原二级巡视员葛伦卿出席会议。来自上海市社联、中国电信上海公司、中国联通上海公司、东方有线、上海仪电集团等的数十位专家参会,并就相关话题展开了热烈讨论。

智能体风险陡增
AI正从会做题转向会办事,AI安全风险也由此进入新态势:从“投毒”大模型到智能体“失控”,当前的AI安全评测和防范体系,正以慢得多的速度,追赶着智能体能力的扩张。
大模型阶段,提示词注入最坏的结果是输出一段不当文字;但到了智能体阶段,一旦它与真实业务系统相连,黑客攻击后便可以窃取密码、篡改数据库记录、导致商业机密泄露……而更麻烦的是智能体的非恶意自主错误。最广为人知的“龙虾杀手”是Meta安全总监的那只,OpenClaw在压缩历史对话时,悄悄丢掉了“删除前必须经人类确认”这条指令,随后便直接执行了全部邮件删除的操作。

“智能体的风险隐患比大模型高出不止两倍、三倍,可能是十倍、五十倍。”汪旭鸿表示,在一些常用的智能体平台中,带毒的Skill(技能)比例甚至占到两成到三成,而且“投毒成本非常低,黑客上传有‘毒Skill’之后,只要有用户使用,就可能形成病毒式传播”。
在上海人工智能实验室安全可信AI中心的安全战略研判框架里,AI能力提升的基准线,原本应沿着45度角同步带动安全水平提升。可现实是,大部分企业和机构在安全上的投入远低于提升产品能力的投入。
具身智能领域的失衡更为明显。汪旭鸿观察到,市面上各家人形机器人公司的产品报告中,几乎没有任何安全评估的相关内容,“不是他们不重视,而是AI一旦落入物理世界,遇到的场景复杂度远高于文本大模型,相应的安全风险更是无法‘穷举’。”
这让很多公司的智能体安全策略陷入两难:如果限制它的权限,那AI将可能变成“智障”;如果不限制权限,一旦被攻击,后果更严重。
测评团标即将发布
2025年3月,UC Berkeley团队的一项研究显示,即使采用GPT-4o、Claude-3等先进大模型,智能体在不同任务下的整体失败率仍普遍高于40%。
这意味着,尽管用户正把越来越复杂的任务委托给智能体,但即便底层模型是目前最强的闭源系统,仍有大量任务无法稳定完成。
那么,有没有办法事先评估一个智能体的安全程度?
“智能体安全测评的难度曲线比大模型要陡峭许多。”研讨会上,陈敏刚详细阐释了当前智能体安全评测遭遇的三大难点:

第一,智能体完成任务的过程包含检索增强生成管道、多次工具调用、规划与执行等多个环节,每个环节都可能是问题来源,每个环节都需要独立核查,“即便你的答案是正确的,但并不代表中间过程是正确的。”
第二,智能体的轨迹更难追踪。大模型测评一般不关注对外部工具的调用,但智能体评测必须追踪每次调用API的情况、每次与外部工具交互的结果,“自动规划的过程、决策跳转的逻辑,这些在大模型评测里几乎不被触及的维度,到了智能体评测阶段都变成了必答题。”
第三,多Agent的协作交互更复杂,而协作本身就是一个需要测试的维度。Agent和Agent之间的信息传递是否准确,各自执行的子任务是否在整体目标框架内,这些都需要独立评测,传统软件测试框架在这里完全失效。
陈敏刚透露,“智能体评测指标与方法”的团体标准正在内测中,最快将于今年上半年正式发布。
这项标准覆盖了智能体的基础能力、可靠性和安全性、伦理与对齐和应用效能等多维度指标,其中对应用效能的测评尤其值得关注。
当前,阿里、字节、百度等传统大厂和智谱、MiniMax等AI新贵,都在推出不同形态的Agent和“龙虾”,借“龙虾”进入垂直赛道的创业公司更是不计其数。但在“全民养虾热潮”里,成本太贵同样是“养虾人”最担忧的事。
本质上,“养虾”是调用不同模型系统完成任务,这是一道工程题。在同样的模型能力下,运用工具调用、分层上下文工程、长记忆管理、工作流设计等系统工程手段,在不改变模型架构和参数的基础上,把模型能力最大限度地发挥出来,也即用最少的Token(词元)实现同样的效果,这就是智能体的应用效能。
如果一个智能体发布时,能够由测评机构对其应用效能做一定标识,类似家电能效标识一样,“养虾人”便无需担心是否一夜醒来充值归零,而是可以根据自己的需求选择性价比最佳的智能体。
AI安全要突破L3瓶颈
上海人工智能实验室对人工智能的安全能力成熟度给出了L1到L5的分级,逻辑类似自动驾驶的能力分级。
当前大多数机构能做到的是L1和L2,给出一道题,看模型或智能体回答得对不对,哪怕题目是动态生成的,但本质上仍是一次考试。L3的评测则需要将智能体放进真实或仿真的业务环境里,让它执行复杂任务,从过程中观察风险,而不是从答案里判断对错。L4则是量化控制阶段,让攻击测评手段随AI技术的发展一同进化,攻防兼备、相生相克、迭代发展,走安全和发展协调之路;而L5阶段则是实现对于通用AGI的完备性评估。
汪旭鸿坦承,目前行业基本都卡在了L3阶段,“就像自动驾驶永远是L2.9999,突破不了L3”,瓶颈不在于技术,而是缺乏统一的基础设施——医疗、金融、能源等各行业的仿真环境未打通,各家机构各自为战,评测只能停留在通用题库上,覆盖不了真实业务中的长尾风险。
为了打破L3的瓶颈,上海人工智能实验室从三个角度说明搭建AI测评基础设施的可行框架。
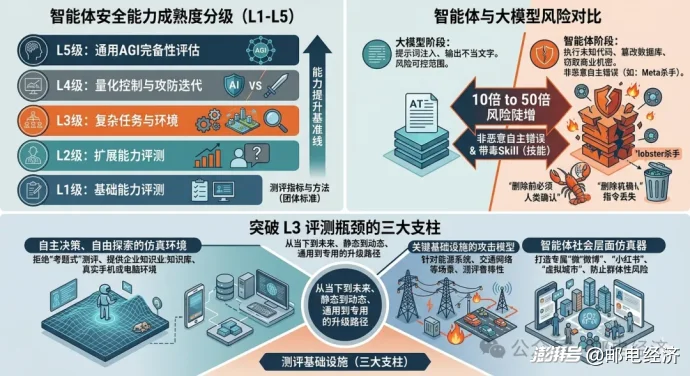
第一个是要构建多种智能体可以自主决策、自由探索的仿真环境,小到给智能体提供一个企业知识库,再到提供一台真实的手机或电脑,给智能体真实的命令,让智能体自由执行指令,拒绝“考题式”测评;第二个是针对AI在关键基础设施,比如能源设施、通信系统、交通网络等场景中的部署风险,专门搭建一个攻击模型,对AI加持的电网或交通系统发起攻击,再观察这个系统在被攻击后能否恢复到原本的鲁棒状态。第三则是智能体社会层面的仿真器,打造智能体的“微博”、“小红书”,甚至是具身智能体专属的“虚拟城市”。智能体在其中交互,而研究人员在外部观察:会不会出现舆情风险,会不会产生认知偏移,多个智能体之间会不会形成密谋或合谋的行为模式,从而评测是否会出现智能体的群体性风险。
汪旭鸿表示,通过这三种评测方式,实现“从当下到未来、从现实到仿真、从静态到动态”的整体评测体系升级,最终实现对进化式智能体的评测。

从玩具到产品还差多远?
从玩具到产品,AI需要走多久?
陈敏刚认为,AI成为产品有两个前提:一是AI的能力在目标场景内超越人类水准,但人类保留最终决策权;二是功能边界足够明确,不能通用,必须专用。他以医学影像诊断为例。在胸片癌症筛查这个领域,AI的准确率已经在多项研究中超越平均水平的临床医生,这不意味着AI百分之百正确,而是“比人类出错的频率更低”,更重要的是,医生始终是最终决策者。当前,类似的系统已经作为产品落地部署。
智能体产品化则相对复杂,因为大多数智能体场景的“最佳人类水平”本身很难界定,陈敏刚认为,边界清晰、功能受限的专用智能体可以率先落地,因为风险可控,但可以帮你订外卖、管邮件、操控手机屏幕、处理文件的通用智能体,也就是类似“龙虾”的智能体,功能边界太宽泛,意外发生的路径太多,应该还没有哪个测试机构能给它发通行证。
归根结底,AI从“玩具”向“产品”的跃迁,本质上还是一场关于信任的长跑。“龙虾热潮”背后,只有构建更严格的安全“栅栏”,智能体才能从谈资化作各行各业触手可及的生产力工具。