突破量子计算两道“天堑” NVIDIA推出全球首个开源量子AI模型“ISING”

作者:毛烁

量子计算为什么迟迟无法走向大规模商用?
其实,量子计算这些年并不缺少阶段性突破。但真正让行业没有跨入“大规模可用”的原因在于,整个量子计算系统在扩展过程中暴露出的复杂性,远远超过了预期。
用业内的一句大实话来说:流片容易,调校要命。
01 量子计算的两道“天堑”
眼下,摆在量子计算产业化进程前的,是两道门槛,一是量子处理器的校准,二是量子纠错。
先看校准。
要知道,量子处理器并不是传统意义上“流片完成、通电运行”的芯片。无论是超导、离子阱、自旋量子点还是中性原子,量子比特都处在极其脆弱的物理条件之下。
温度漂移、电磁环境扰动、材料缺陷、控制链路波动、器件间串扰,都会直接影响其工作状态。而硬件数量一旦上升,系统就不再是若干独立量子比特的简单叠加,而会迅速演化为高度耦合、持续漂移、需要反复调参数的复杂系统。
而所谓校准,就是从大量测量结果中识别量子比特频率、门操作窗口、读出条件、耦合关系和噪声特征,再据此确定整套控制参数。
每一次冷启动、环境变化、每一段运行周期之后,都可能需要重新扫描、拟合、补偿。在几十比特规模的系统里,这项工作甚至需要经验极深的团队持续介入。而硬件规模达到数百乃至数千量子比特时,依靠专家经验和人工调参的方式甚至都很难继续维持。
走到这一步,校准已经不再只是实验物理问题,而是控制工程、统计建模、自动化软件和机器学习共同参与的系统问题。
再看纠错。
量子计算的另一层挑战在于,量子态本身极易受噪声影响,门操作和读出过程会引入误差。只要规模稍大,系统就不可能依赖“裸比特”直接完成有意义的计算。
所以,纠错几乎是必经之路。
理论上看,目前行业已经有较成熟的编码方案;但从实际工程上看,困难点其实在于把纠错持续、稳定、实时地运行起来。
一个逻辑量子比特背后,往往需要大量物理量子比特来支撑。随着码距增大、测量轮次增加、系统规模上升,错误信息会以持续数据流的方式不断产生。经典系统必须在很短时间内完成syndrome解码,并及时给出后续控制所需的信息。只要这个过程的时延压不下去,吞吐跟不上,纠错就会失去意义,量子态也会在累计误差中迅速失稳。
当量子硬件继续提速、量子比特继续扩容,真正的压力开始转移到经典计算一侧——解码算法是否足够高效,控制系统是否能承受持续并发的数据流,软硬件协同是否能把整个闭环稳定压在物理退相干时间之内。
到了这个阶段,量子计算就成为了一场围绕实时性、吞吐、容错和系统协同展开的“工程战”。
这也是为什么,Google、IBM等巨头近年来推进量子研究时,重点越来越少放在“单次展示多少量子比特”上,而更多转向逻辑比特、误差抑制、纠错实验、控制栈和系统集成。
行业的难点已经发生了变化。现在,大家更关心的是量子比特做出来之后,能不能把它们变成一台真正可用的机器。
换句话说,决定量子计算未来几年产业走向的,是完整的“算力工程问题”——如何让量子硬件、控制电子学、校准软件、纠错解码器和经典加速系统共同构成一套能扩展、能运维、能持续运行的体系。
02 NVIDIA Ising 让量子计算告别“手工时代”
为了攻破上述两大核心痛点,NVIDIA祭出了杀招——NVIDI Ising。
这个名字,其实也致敬了伊辛模型(极大地简化了复杂物理系统理解的标志性数学模型),其目的,是用AI彻底简化复杂的量子工程。
NVIDIA Ising 是针对性极强的开源AI模型系列,专门为解决“校准”和“解码”这两大痛点量身定制。
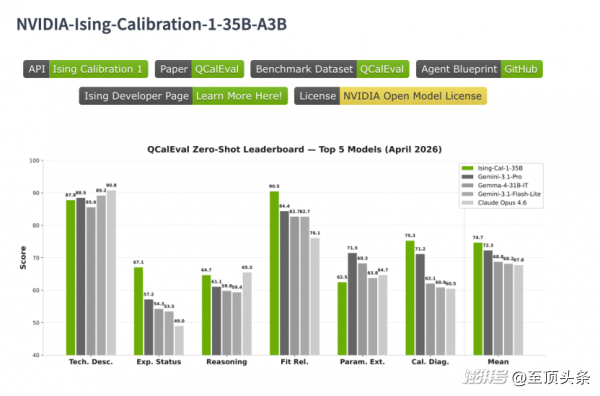
NVIDIA Ising的核心组件之一NVIDIA-Ising-Calibration-1-35B-A3B(Ising 校准)拥有350亿参数(35B),其底层架构基于阿里开源的Qwen3.5-35B-A3B进行微调衍生,采用的是混合专家视觉语言模型架构。
截取自huggingface
在推理阶段,每个token仅激活约30亿活跃参数(包含256位专家,每个token 8位活跃专家),这种MoE 架构保证了模型在拥有海量知识容量的同时,依然能保持极高的推理效率。
除了参数和效率,NVIDIA Ising的另一个特点在于,让量子校准,不是“算出来”的,而是“看出来”。
NVIDIA并没有走传统的数值优化老路,而是极其创新地引入了视觉语言模型(VLM)。NVIDIA Ising具备高达262144个token的超长上下文窗口,支持图片(PNG、JPEG)和文本的混合输入。能够像最资深的量子物理学家一样,快速“看懂”来自量子处理器的测量数据实验图,并根据六个核心分析问题类别,自动生成结构化的高质量技术文本。
同时,NVIDIA Ising的核心组件之一Ising Calibration(Ising 校准)还可以进行技术分析、得出实验结论、进行显著性评估、拟合质量评估、参数提取,甚至自动进行实验成功分类。
更关键的是,这些能力并非停留在“分析层”。通过与AI 智能体(AI Agents)的结合,NVIDIA Ising的输出可以直接驱动连续校准流程,使原本高度依赖专家经验、需要数天人工干预的工作,被压缩至数小时内完成。
在部署层面,NVIDIA Ising同样体现出较强的工程可行性。仅需 2 块 NVIDIA L40S(48GB)或1块 H100(80GB)GPU 即可运行,大幅降低了算力门槛。
而在模型训练上,NVIDIA 采用了两阶段顺序 SFT(监督微调,涵盖72.5K条数据),将大量专家经验系统性地融入这套350亿参数模型之中,使其具备了贴近真实科研流程的分析与决策能力。
面对量子纠错问题,NVIDIA的解法是,用神经网络的并行计算能力,碾压传统算法的串行瓶颈。
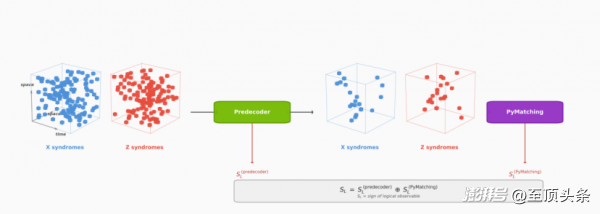
Ising Decoding(Ising 解码)提供了两个3D卷积神经网络(3D CNN)模型变体,分别针对“速度”“精度”进行优化。其实,3D CNN天生适合处理具有时空相关性的量子纠错拓扑数据,专门用于量子纠错的实时解码。
截取自Github
实测数据显示,相比当前开源行业标准pyMatching,Ising解码模型在速度上最高快了2.5 倍,在准确率上最高提升了3 倍。这在分秒必争的量子态相干时间里,2.5 倍的速度提升甚至决定了纠错的成败。
在数据训练层面,NVIDIA也采取了两条路径,并且刻意做了区分。
对于解码模型,其完全基于合成数据(synthetically generated data)进行训练。通过在模拟环境中引入特定的去极化噪声(depolarizing noise),可以生成大规模、可控的数据样本。这带来的直接好处是,开发者无需依赖昂贵的量子硬件,也能够完成模型的训练与微调。
而在校准模型上,数据来源则明显更“重”。除了模拟器生成的数据之外,还融合了来自多家量子处理器(QPU)合作伙伴多年积累的真实运行数据。这部分真实数据提供了更复杂的噪声分布和工程细节,使模型的分析能力更贴近实际系统。
这样的数据策略在于,解码模型追求规模与可扩展性,校准模型则强调真实性与工程贴合度。
03 开源背后的“三重奏” 加速生态扩展
NVIDIA Ising模型的领先性能不言而喻,但NVIDIA却将其全面开源。
从GitHub、Hugging Face,到NVIDIA官方平台,相关模型、数据与训练框架均已开放获取;其中Ising-Calibration-1-35B-A3B甚至采用了相对宽松的Apache 2.0 及 NVIDIA 开放许可协议。

截取自Github
这份“慷慨”的背后,指向了三层目标。
第一层,是构建“生态基建”。事实上,量子计算仍处于技术路线高度分裂的阶段,超导、离子阱、光量子、硅自旋并行推进,没有统一标准,也不存在“唯一正确答案”。
除了仍在接入中的光量子路线,NVIDIA Ising 已与主流技术路径展开合作。原因也很直观,没有任何一家厂商,能够独立构建完整且真实的噪声模型。
因此,开源并不是让渡能力,而是加速演进的机制。
当更多噪声数据被引入进行微调(fine-tune),这一模型便会逐步演化为整个行业共享的“公共底座”。而随之一套更加统一、可复用的技术基础设施也随之形成。
第二层,是释放开发者的“非共识创新”。其实,过去一段时间,一些关键性的量子架构突破,并非来自传统巨头,而是出自新兴团队,例如Iceberg Quantum、Atomic,以及DeepSeek 这样的团队。
这背后的原因,是创新正在加速“去中心化”。
NVIDIA显然不打算错过这波红利。通过开源,可以将量子纠错研究的门槛,从“必须拥有量子硬件”,降低为“只需具备算力平台”。
与此同时,NVIDIA也一并补齐了配套工具——从 Kuquanim 模拟库,到标准化workflow“cookbook”,再到 NVIDIA NIM 微服务体系,形成了一套完整工具链,并支持本地部署以满足数据安全需求。
这意味着,即便硬件资源受限,开发者依然可以参与最前沿的量子研究。
某种程度上,这也是一次“技术平权”。
第三层,是补齐“混合算力体系”的拼图。
NVIDIA Ising与NVIDIA CUDA-Q 以及 NVIDIA NVLink / NVQLink 等底层能力深度协同。
而这,造就了一条完整的技术链路。
底层,NVQLink提供低延迟的QPU-GPU实时通信;中层,CUDA-Q提供混合量子—经典计算框架。上层,NVIDIA Ising模型承担校准与纠错决策。
而这套“模型 + 框架 + 硬件互联”的体系一旦成型,其外溢效应很快体现在产业层面。
目前,除了NVIDIA Ising纳入其开放模型矩阵之中,还有智能体Nemotron、面向物理AI的 Cosmos、自动驾驶领域的Alpamayo、机器人方向的Isaac GR00T,以及生物医药领域的 BioNeMo。
更重要的是,市场的反馈也随之迅速显现。
在学术界,包括Cornell University、University of Chicago、University of California San Diego、Harvard John A. Paulson School of Engineering and Applied Sciences 等顶尖高校,以及 Fermilab、Lawrence Berkeley National Laboratory、National Physical Laboratory 等国家级研究机构,已经率先引入这套模型体系,用于量子计算相关研究与实验平台。
而在产业侧,参与者的覆盖面同样迅速扩大。包括IonQ、IQM Quantum Computers、Q-CTRL、Infleqtion、Atom Computing 在内的一批量子计算企业相继入局,连同 Academia Sinica、EeroQ、Conductor Quantum、EdenCode、Quantum Elements、SEEQC 等机构,共同构成了一张横跨科研与产业的应用网络。
当不同技术路线、不同类型的参与者开始基于同一套工具体系展开探索,一个更加统一、协同的量子计算生态,也正在逐步成形。
04 写在最后
身处量子计算圈内的人都知道,过去两年,行业其实正在经历一段挤水分的“阵痛期”。
NISQ(含噪中型量子)时代的红利正在被加速耗尽。 迈向FTQC(容错量子计算)的高墙,光靠物理学家在实验室里“搓”材料、调微波,已经跨不过去了。
而NVIDIA Ising 的全面开源,却撕开了这道高墙的掩体,将量子产业的底层逻辑展现在所有人面前。
我们仔细盘点黄仁勋在量子领域的落子,你会发现一种极其前瞻的战略定力。在一众科技巨头纷纷下场自研超导、离子阱或光量子的洪流中,NVIDIA至今没有动手造过任何一颗物理量子芯片,但它却正在生产量子芯片“呼吸”所需的氧气。
从CUDA-Q建立统一的编程桥梁,到NVQLink实现QPU与GPU之间的极低延迟互联,再到今天用开源的NVIDIA Ising 模型补齐关键的实时校准与解码拼图。NVIDIA 的初衷非常清晰——为所有探索者铺设一条通用、高效的基础设施高速公路。
量子计算发展了三十年,硬件工程师们像精密的钟表匠一样,小心翼翼地呵护着脆弱的量子态。而现在,随着大语言模型和3D CNN 接管了调参和解码,量子计算终于开始告别“手工作坊”与“实验物理”的时代,真正迈入了由AI驱动的、高度自动化的“大工业时代”。
有人说AI的尽头需要量子计算支撑,而量子的黎明却正由AI照亮。如今,这两大人类技术之巅双螺旋的交汇,刚刚开始......