Harness内心OS:大模型只管想,剩下烂摊子全我的

大模型说"我要调搜索",
谁去调?
Harness去。
让不让它调?
Harness来决定。
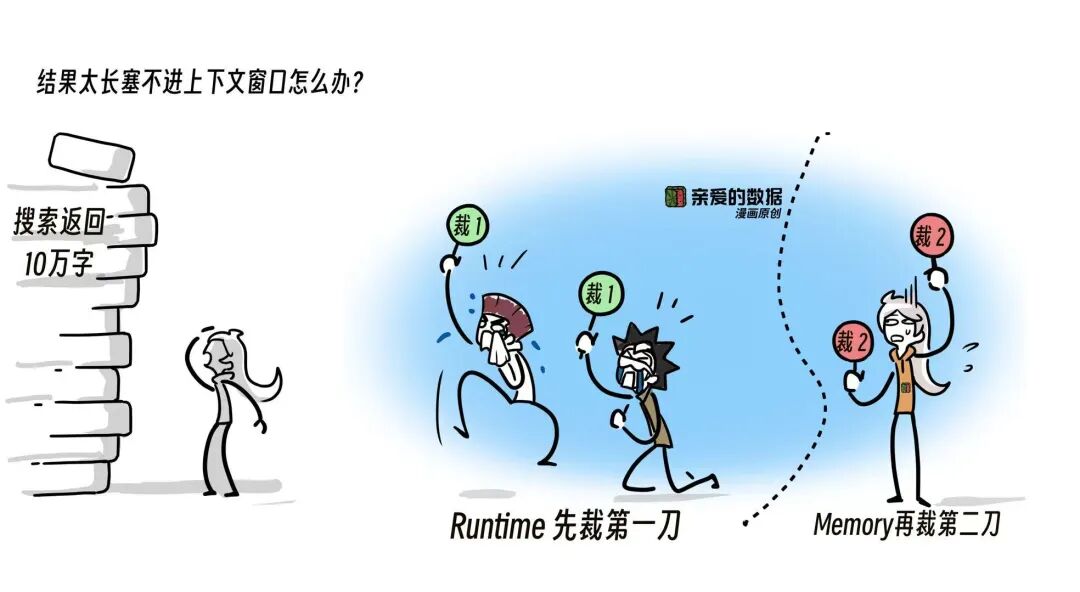
结果太长,塞不进上下文窗口怎么办?
Harness来裁剪。
沙箱崩了怎么办?
Harness来兜底。
Harness这么有用,有哪些组件?
想了解Harness组件,
强烈建议先看开头这篇,
少瞎吹系列:AI智能体基础,infra就不基础
其实就是几个月前的叫法不同,
我列出的这些组件:
Runtime(执行环境)、
Memory(记忆)、
Gateway(网关)、
Browser Tool(浏览器工具)、
Identity(身份管理)、
Code Interpreter(代码沙箱)、
Observability(可观测性)、
Policy(策略)、
Evaluations(评估)。
这些东西都就叫Harness。
无论是to B,还是To C,
无论Agent是什么设计理念,
Harness都是脚手架,优化Agent运行。
世界上没有脱离Harness的Agent。
本质上,Agent的核心能力就一个:
大模型自己决定下一步调什么函数,
是大模型实时判断出来的,
也是大模型根据当前的上下文"想"出来的。
其余的归Harness,
都为了让"大模型自己决定调什么函数"的过程,
能跑得稳、跑得快、跑得安全。

看看有哪些误解:
误解一:Harness给大模型,
搭建了一套完整的工作环境。
正解一:可不止工作环境。
只说搭工作环境,不全面,
准确地说,它做的事情至少还有两层:
第一,管控体系,
第二,支撑系统,
误解二:Harness是一个组件;
正解二:不是一个具体的组件,
它是一个总称。
就像"汽车"不是指某一个零件,
而是指发动机 + 底盘 + 刹车等,
组装在一起。
误解三:有的大模型能调用工具,
所以大模型自己就是 Agent。
正解三:大模型负责"想",
Harness又动手又兜底。
大模型说"我要调搜索"的时候,
它只是输出了一段JSON文本。
它没有真的上网,没有真的连接搜索引擎,
没有真的拿到结果。
是Runtime解析了这段JSON;
是Gateway把请求转发给了搜索 API;
是Policy在调用前检查了权限;
是Memory把结果记录了下来。
Harness才"动了手"。
误解四:Harness搭好一次就不用动了。
正解四:是跟模型能力绑定的。
旧模型容易输出格式错误,
Harness就加了格式校验和重试。
新模型不犯这个错了,这个逻辑就废了。
Anthropic原话说得很直白:
Harness编码的假设会随着模型改进而过时。
所以,Harness不是搭完就完了,
它得跟着模型一起迭代。
误解五:Harness的难点是技术,
搞定代码就行。
正解五:最难的部分不是写代码,
是做决策。
上下文窗口快满了,
该丢哪些信息保留哪些?
工具调用失败了,
该重试还是放弃还是换一条路?
大模型反复做同一件事,
第几次该判定它陷入死循环?
这些都没有标准答案,
取决于你的业务场景、
你的用户容忍度、
你的成本预算。
代码不难死人,
但"在什么情况下做什么选择"这套策略,
是靠踩坑踩出来的,会难死人。
误解六:Harness出错了看看日志就行,
跟普通软件调试一样。
正解六:比传统软件调试复杂一个量级。
普通软件是确定性的,Agent不是。
普通软件同样的输入,
一定得到同样的输出,你能复现。
Agent给它同样的写代码再搜索,
结果可能完全不同。
而且,一个任务可能跑了200步,
中间调了5次工具,
任何一步的微小偏差,
都可能导致最终结果跑偏。
| | |
|---|---|
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
本质是,Harness到底做了哪些事,
来优化Agent运行。
细数九件事。

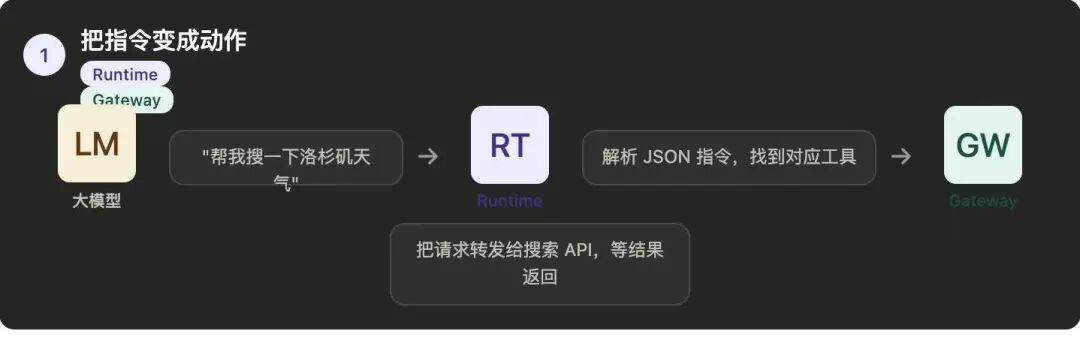
第一件事:把大模型的"话"变成真正的"动作"
组件:Runtime + Gateway
大模型输出的只是一段字,
比如:
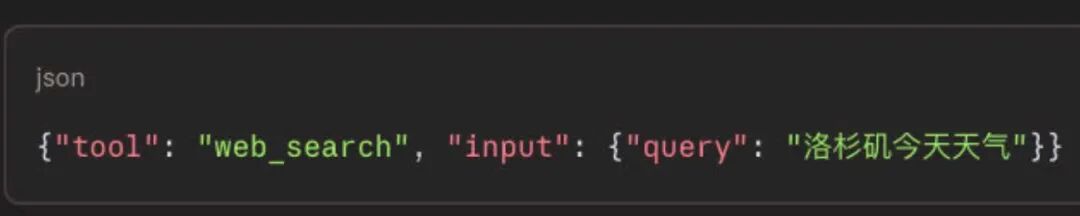
Harness要做的是:解析这段 JSON,
从工具注册表里找调用那段代码,
传入参数,等待返回结果,
把结果格式化成大模型能理解的文本,
再塞回大模型的下一轮输入里。
Runtime 是执行环境,
负责接收大模型输出的JSON 指令,解析它,
启动真正的执行流程。
Gateway是路由层,负责找到这个工具调用应该发给谁,
是发给搜索 API、还是发给沙箱、还是发给企业内部系统,
然后把请求转发过去,等结果返回。
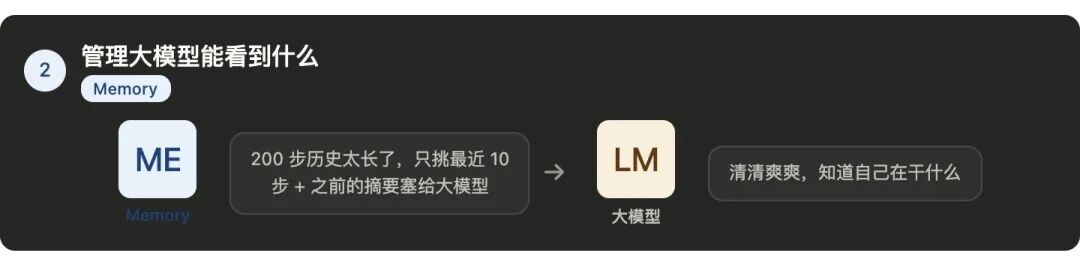
第二件事:决定大模型每一轮能"看到"什么
组件:Memory
大模型的上下文窗口是有限的。
一个复杂任务跑了200步,
之前所有的对话、工具调用,
返回结果加在一起可能有几十万字,
远超上下文窗口的容量。
Harness要做的是:
决定这一轮调用大模型时,
塞进去哪些内容、丢掉哪些内容。
最近几轮的对话要保留,
很早之前的工具返回结果可以压缩成摘要,
跟当前任务无关的历史可以暂时不放进去。
这直接影响大模型的决策质量。
如果Harness塞了太多无关信息,
大模型会被干扰。
如果Harness丢了关键信息,
大模型会做出错误判断。
上下文管理是Harness对Agent质量,
影响最大的环节之一。
Memory管理所有的历史信息,
之前的对话、工具调用记录、中间结果。

第三件事:在大模型调用函数之前做检查
组件:Policy + Identity
Harness在每次工具调用之前会做一系列检查:
这个Agent有没有被授权使用这个工具?
这个操作是不是需要用户确认才能执行?
这个工具在过去一分钟内,
是不是已经被调了 50 次,需要限速?
检查通过才放行,不通过就拦截,
并把拦截原因告诉大模型,让它换个方式。
Policy是规则引擎,存储着"什么能做,
什么不能做"的规则。
比如"这个 Agent 不允许删除文件"
"调用外部 API 需要用户确认"
"每分钟最多调 10 次搜索"。
Identity 管理"谁在操作":
这个Agent以什么身份运行、
它有什么权限、它能访问哪些资源。
两者配合:Identity确认身份,
Policy根据身份查规则,决定放行还是拦截。

第四件事:在大模型拿到结果之后做处理
组件:Runtime
工具返回的原始结果可能有各种毛病。
搜索引擎返回了 10 页结果,每页几千字,
太长了,直接塞给大模型会浪费上下文窗口。
Runtime负责对工具返回的原始结果做截断,
提取关键信息,格式化。
搜索返回了10万字,
Runtime截取前 500 字。
这些处理逻辑跑在 Runtime 里。

第五件事:处理工具调用失败的情况
组件:Runtime + Policy
Harness根据错误类型选择策略。
Runtime 检测到失败(超时、崩溃、错误码),
Policy里存着对应的处理策略,
网络超时重试 3 次,
权限不足直接报错,
沙箱崩溃换新沙箱。
Runtime根据Policy的规则执行对应的恢复动作。
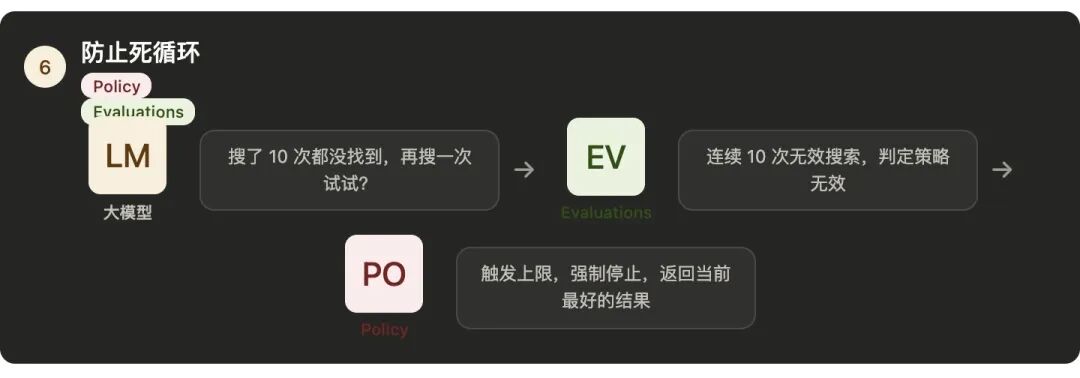
第六件事:防止大模型陷入死循环
组件:Policy + Evaluations
Harness根据错误类型选择对应的策略。
Policy里定义了硬限制:
最多调多少次工具、
最多用多少token、
最多跑多长时间。
Evaluations负责判断质量,
连续5次搜索都没找到有用信息,
Evaluations判定"当前策略无效",
触发Policy的终止规则。

第七件事:保存每一步的执行记录
组件:Memory + Observability
大模型每一次推理,
每一次工具调用、每一次返回结果,
Harness都写入Session日志。
这些记录有三个用途:
第一,恢复用。
进程崩了,读取日志,
从最后一步继续执行,不用从头来。
『执行到第200步失败了』,
『从第199步继续』靠这个实现的。
第二,调试用。
发现Agent的输出不对,
可以回溯日志看每一步发生了什么,
大模型在第15步做了什么判断?
第37步调了什么工具?
第52步拿到了什么结果?
是哪一步开始出的问题?
第三,计费用。
每次调用大模型用了多 token,
每次工具调用花了多长时间,
整个任务的总成本是多少。
Memory负责保存Session日志,
Observability在Memory的基础上,
做细粒度的追踪。
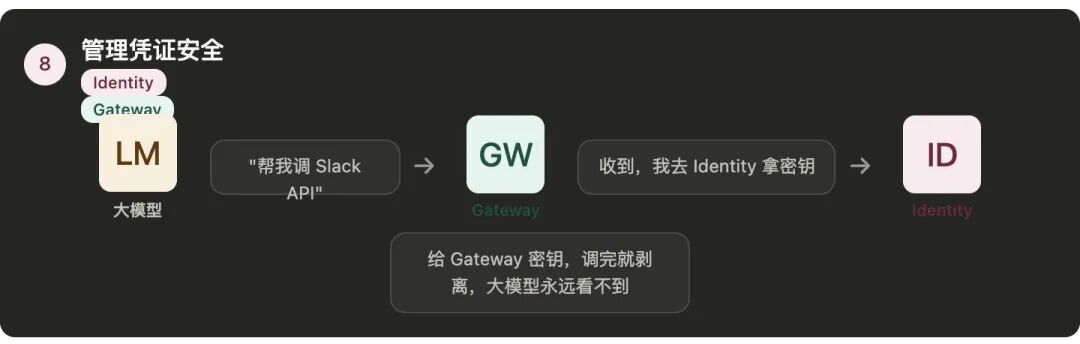
第八件事:管理凭证,不让大模型碰到密钥
组件:Identity + Gateway
大模型只发出"我要调数据库"这个指令,
Harness在执行时附上凭证去调,
调完之后把凭证相关的信息,
从返回结果里剥离掉。
Gateway在转发工具调用请求时,
从Identity那里拿到对应的凭证附在请求上,
大模型只跟Gateway交互,
永远碰不到Identity里的凭证。
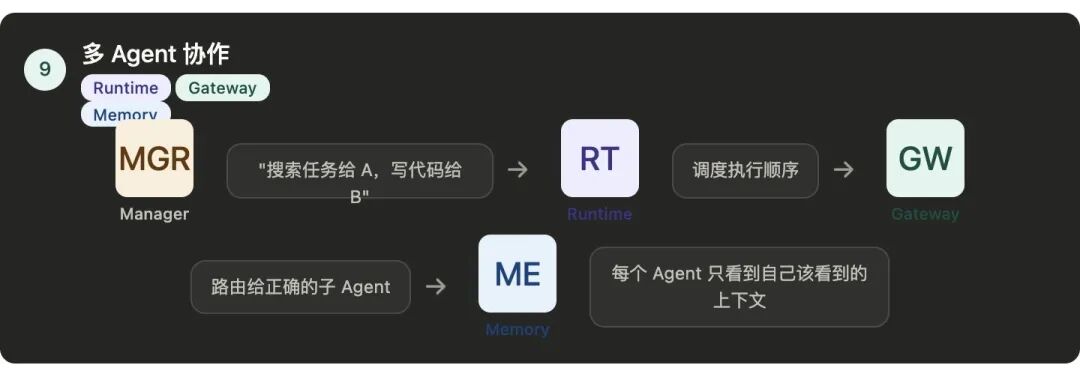
第九件事:编排多个Agent的协作
组件:Runtime + Gateway + Memory
Harness把Manager的指令路由,
给正确的子Agent,
把子Agent的结果收集回来,
交给Manager,
管理多个Agent之间的上下文传递,
让它们不会相互间干扰。
Runtime管理Manager Agent,
和子Agent的执行循环,
谁先跑、谁后跑、谁可以并行。
Gateway负责把Manager的指令,
路由给正确的子Agent,
把子Agent的结果收回来。
Memory管理多个Agent之间的上下文传递,
但每个Agent只看到自己该看到的部分。
写到最后了,
替Harness发个声吧:
『大模型只管想,
剩下烂摊子全是我的。』
《AI产品和技术模块》
1.Kimi Agent产品很厉害,然后呢?
2.搞懂“记忆”必看|吃透Engram,坐等Deepseek新模型
3.实属踩踏了?深水炸弹Seedance掩盖Seed2.0
4.少瞎吹系列:AI智能体基础,infra就不基础
《具身智能》
1.“26年具身智能,根本做不过来”:含陶大程教授独家专访
2.漫画:大模型“强控”具身智能机器人?
《AI+医疗》
1.独家深度丨夸克健康大模型调研报告
2.离谱!熬夜三年肝损害,AI博主也靠AI学“续命”医学知识
3.为什么AI能预警心脏主动脉“血管炸弹”?
4.对话作者:全球首个开源手术视频大模型SurgMotion(第一期)
《超节点系列》
1.对抗NVLink简史?10万卡争端,英伟达NVL72超节点挑起
2.英伟达:『照抄者死』,阿里华为:AI集群狂飙『全解耦』
3.阿里华为『血战』英伟达AI超节点:悲观者正确,乐观者赚钱
4.抢在英伟达护城河合拢前,硅光的冲刺与最后窗口
5.OCP现场 l 北美AI巨头罕见共识ESUN,为利益『握手』
6.为什么有些『闪断的锅』,硅光不背?

原标题:《Harness内心OS:大模型只管想,剩下烂摊子全我的》