为什么AI总是编造事实?AI:真不是故意的,容我狡辩一下


现在谁手机里没两三个AI助手?
以前有问题找搜索引擎,
现在张嘴就是“问AI”。
AI也几乎不让咱失望,
甭管什么问题,
它都能给你列一串看着贼有道理的答案。
但你要是问的特别重要,
比如健康问题,
或者写材料用的数据、案例,
那还是自己核实一下靠谱。
因为有时候,
AI会信誓旦旦给你一个看着合理、
实际压根不存在的答案。
其实这现象早就不是秘密了,叫“AI幻觉”。
OpenAI和佐治亚理工学院的研究员
发了篇重磅论文,结论是:
就算给AI的训练数据全对,
它在某些问题上也不可避免地会犯错——
这既是统计规律,
也是被现在的“考试制度”逼出来的。
一起来看一看?

第一关:还没毕业,底子就有问题
AI犯错,跟它的“预训练”阶段有关。研究员先建了个简单的二元分类模型,给它一堆绝对正确的数据去学。结果发现:有些问题它表现特好,比如检查拼写错误,基本不出错。但另一些问题,比如“数某个英文单词里某个字母出现了多少次?”、“某人的生日是几月几号?”AI就有可能会出错。
为啥?这样的数据在做分类的时候很难用一条直线进行二元分类,一些模型用这样的数据进行预训练的时候就可能会产生错误。

已获授权图,转载勿使用
打个比方:模型分类就像拿把刀想把数据一刀切成两半,但有的数据本身是弯弯绕绕的圆弧,你拿直刀硬切,能不切歪吗?
比如你问DeepSeek V3:“DEEPSEEK里有多少个D?”它可能会答2或3。换R1模型问,就没这问题——模型不一样,表现也不一样。这还只是“判断”,要是让AI直接生成内容,错的概率更大,比判断翻车高出两倍还多。
第二关:信息太少,它就开始“编”
还有个问题:假如训练数据中某个信息过少,那么AI在回答的时候出错的可能性也会比较高。
比如问爱因斯坦生日,它门儿清,因为到处都是这数据。但你要问某个普通人“田小豆”生日,就露馅了——这个数据出现次数特别少,AI出错的可能性也会变高。

已获授权图,转载勿使用
特别是当数据只出现了一次的时候,这时候可能会更糟糕。
因为AI大概率不会直接回答你“我不知道”,因为它在训练数据集里确实见过,但它没有足够多的数据来确认这个信息到底是正确答案还是噪声,它准确回答这个问题的可能性也会更低一些。
数据模式和模型本身的限制,以及极少样本的数据,都可能会让AI在预训练阶段就产生“幻觉”,生成错误的内容。
第三关:考试规则,逼着它蒙
前面说的都是“底子”问题,但人类评价AI的方式也逼着AI去“编造”。
想想咱们的考试:答对得分,答错或不答都不得分。所以考试时,就算不会,你也得蒙一个,万一对了呢?
AI的评分机制也差不多。如果它老实说“我不知道”,得0分;如果瞎蒙一个,万一对了,就得分。数学期望算下来,蒙一个比说“不知道”划算。所以AI和人类一样,学会了“蒙”。
那怎么办?研究也给了个思路:改评分规则。答对加分,答错扣分或得零分,但要是说“我不知道”,可以给个微小的奖励,至少不扣分。让它知道,诚实不亏。

已获授权图,转载勿使用
重要的事,别全信AI
总结一下:AI幻觉从“预训练”就埋下根,到了后训练阶段又被评分机制放大。科学家想了不少办法,但至少现阶段,AI幻觉没法彻底避免。
所以,重要的事,比如公开演讲用的数据、写报告引用的案例,还是自己核实一下。养成对AI产出的答案不轻信的习惯,用搜索引擎、查原始资料,交叉验证一遍。万一台上翻车,台下哄笑,尴尬的是你。
另一招是,和AI对话时,提前给它加好“护栏”。比如先把参考数据、条件限制发过去,让它严格按你给的资料来搜索、生成。框定了范围,它就不容易跑偏。
反过来,如果AI对你说“我不知道”,你应该感到庆幸,至少它没打算胡编乱造一个答案蒙骗你。

已获授权图,转载勿使用
所以,AI的局限,恰恰提醒了我们:
它善于输出答案,
但分辨真伪的主动权,
终究在自己手里。
用得聪明,才是真聪明。
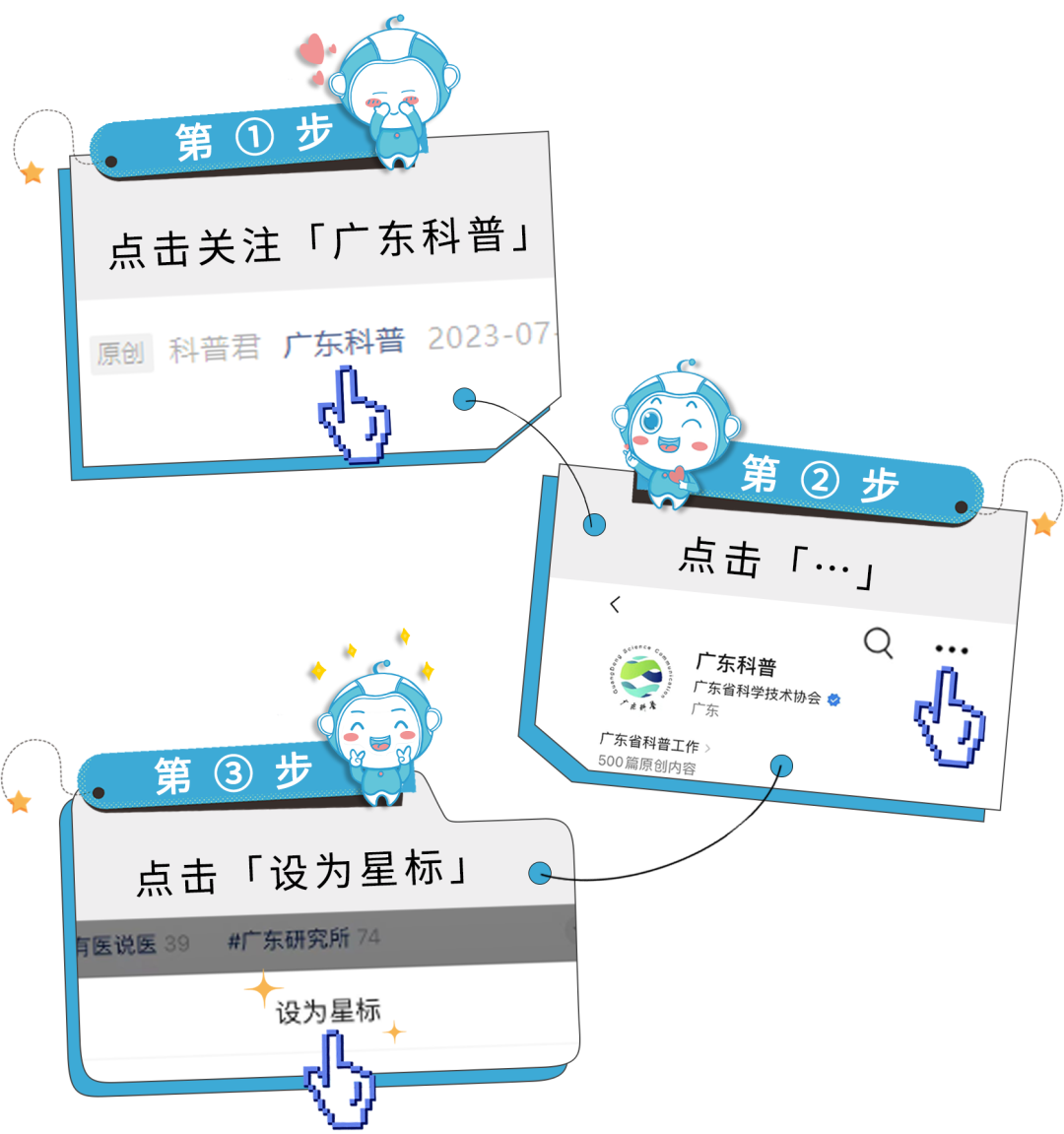
想及时收到更多科普知识
把“广东科普”设为星标吧~
↓↓↓
今日推荐视频
蚕与桑
改变世界的“动植物CP”
蚕与桑书写七千年传奇!
从嫘祖养蚕到丝路驼铃,
从《本草纲目》到蚕丝硬盘。
这对中国最强CP正用科技焕发新生。
热门阅读
(点击图片即可阅读)


原标题:《为什么AI总是编造事实?AI:真不是故意的,容我狡辩一下》