Nature子刊:上海交大陈晓军团队等开发AI新模型,用于显微眼科手术识别与导航

编辑丨王多鱼
排版丨水成文
人工智能(AI)中的基础模型(Foundation Model)正在通过利用大规模未标注数据进行预训练来彻底改变医疗健康领域。然而,由于高质量手术数据有限以及实时部署的计算瓶颈,其在术中的应用,仍处于探索阶段。
2026 年 3 月 3 日,上海交通大学陈晓军教授、汕头国际眼科中心张铭志教授,上海交通大学医学院附属新华医院赵培泉教授、郑策副主任医生作为共同通讯作者(涂朴勋、郑策、谢晓铃为论文共同第一作者),在 Nature 子刊 Nature Biomedical Engineering 上发表了题为:An ophthalmic video foundation model for surgical recognition and navigation with wet-lab porcine eye validation 的研究论文。
该研究开发了一种专为显微眼科手术识别与导航设计的眼科视频基础模型(OVFM),以及基于该模型研发的增强现实显微手术导航系统。

在医疗人工智能领域,基础模型已在疾病筛查与诊断等术前任务中取得显著进展,但由于高质量手术数据匮乏和实时部署的计算瓶颈,其在术中的应用仍面临巨大挑战。针对这一难题,研究团队联合 8 家医疗中心,构建了一个包含 11426 个显微手术视频的大规模眼科手术视频数据集,涵盖 144 种眼前段与眼后段手术类型,并将其采样为约 110 万个手术视频片段。在此基础上,研究团队提出了一种基于自监督视频 Transformer 架构的预训练策略,通过预测同一视频的不同时空视图,引导眼科视频基础模型(OVFM)模型学习眼科手术中复杂的时空运动特征。
实验表明,OVFM 模型在包括手术步骤识别、器械存在识别、并发症检测及手术场景分割等 7 个下游任务中,全面超越了现有的视频基础模型。为克服大模型参数量过大导致的推理延迟问题,满足术中导航的实时响应需求,研究团队设计了一种“从通用到特定任务”的双阶段知识蒸馏框架。该策略将模型规模最高压缩 15.8 倍的同时,依然保持了约 95% 的原始识别精度,成功实现了 OVFM 在计算资源受限的手术显微镜边缘处理单元中的直接部署。
基于此轻量化模型,研究团队研发了一套具备场景感知能力的智能手术导航系统。该系统能够在无需人工干预的情况下自动识别当前手术步骤,并以稳定速率实时投射切口引导线、撕囊范围圆等个性化导航信息。10 位具备不同临床经验的眼科医生参与了离体猪眼白内障手术实验,结果表明,该系统显著改善了主副切口角度误差及连续环形撕囊中心偏差等关键手术指标,且新手医生在系统辅助下展现出了比专家医生更大幅度的性能提升。
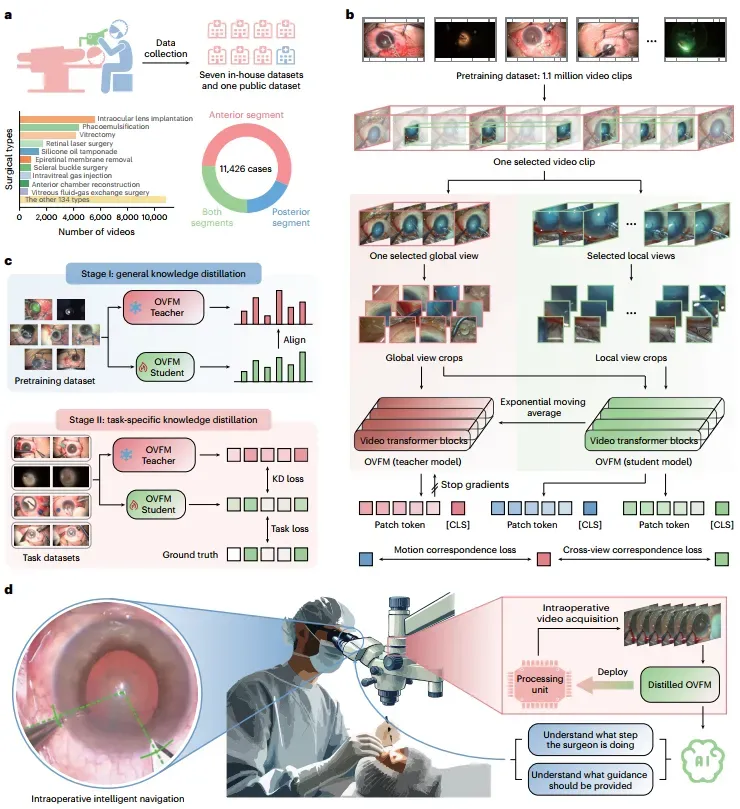
这项研究通过跨中心数据构建、核心算法设计与软硬件系统开发,展示了眼科视频基础模型在场景理解、实时响应和眼科医生技能增强等方面的潜能,为下一代高性能、智能化的超显微外科手术导航及机器人系统的研发提供了全新的技术路径。
论文链接:
https://www.nature.com/articles/s41551-026-01622-w
原标题:《Nature子刊:上海交大陈晓军团队等开发AI新模型,用于显微眼科手术识别与导航》