实测数据告诉你:带引用的AI也不可靠


图片由Chatgpt生成,prompt如下:图片尺寸为16:9,请你想象这样一个场景:AI幻觉泛滥,会给整个社会带来什么影响?
“约 35% 毕业生进入报社、电视台、通讯社等机构,如《人民日报》、央视、澎湃新闻等,近 40% 毕业生进入互联网平台(如字节跳动、腾讯)、数字营销公司或自媒体领域,约 15% 进入金融、咨询、教育等行业,从事品牌传播、市场分析等工作。”
这段带数据且言之凿凿的内容由AI提供,附有多个引用链接,看上去十分令人信服。
然而,这些数据全部是虚假的。
许多用户也有类似经历:向AI提问,它能信誓旦旦地给出一个看似合理的答案,甚至还可以给出了“权威出处”,但深入核实后发现,这些信息来源或是根本不存在,或是与答案毫无关联。
这种现象在人工智能研究领域被称作AI幻觉(AI Hallucination),是指AI创建虚假信息并将其呈现为真实信息的情况。它不同于人类偶尔的记忆错误或口误,而是 AI系统性地生成看似合理但实际上完全错误的信息,并且以看似准确的方式呈现给用户。
那么,AI的幻觉到底有多严重?联网搜索、深度思考这些机制,能否帮助消除AI幻觉?我们尝试从学术研究中搜集相关数据,并实测国内几款主流的大模型,来回答上述问题。
01|幻觉,一个所有大模型都会犯的错误
AI幻觉,并非某个特定模型的缺陷,而是当前AI技术架构的固有限制,是每一个大模型都会犯的错误。
引发AI幻觉产生的机制相当复杂,在模型开发与使用的每个阶段都有可能引入错误信息或不稳定因素,从而导致幻觉的出现。
比如,大语言模型所依赖的海量训练数据来自互联网,数据源就包含着错误信息。如果训练数据中某专业领域的知识较少,模型在面对相关问题时也会编造看似正确但实则错误的答案。此外,指令调优过程也有可能会过度强化模型“必须回答用户问题”的行为。
最重要的是,本质上,大模型只是一个“概率生成机器”——它并不理解学习内容的真正含义,只是根据在训练中学到的词汇搭配频率来生成回答。
不过,不同大模型的幻觉程度有所不同。
为了检验不同大模型的幻觉水平,人工智能公司Vectara推出了专门的幻觉评估模型,可以基于模型在文本摘要任务中的表现,检测生成内容与原始文本的语义一致性,进而评估模型的幻觉率。这款模型已经成为行业内部有关“AI幻觉”的权威测试工具。
在7月最新更新的一次AI幻觉排行榜中,谷歌的Gemini 2.0及2.5系列模型表现出色,整体幻觉率在0.7%-1.8%之间,其中Google Gemini-2.0-Flash-001模型在本次测试的所有模型中幻觉率最低。
在幻觉率最低的20个大模型中,来自Google或OpenAI的模型占据较大比例,这显示出头部厂商在提升模型可靠性上的进展。聚焦于国产模型,则是KIMI和智谱GLM模型的表现较为优秀。

观察幻觉率最高的20个大模型可以发现,其中大部分都是参数量在10B以下的小模型,此外,一些指令调优模型(instruct/it版本)的幻觉率也较高。
前阶段大热的DeepSeek-R1的幻觉率达到了14.3%,在测试的149个模型中位居第16位。专家推测,这可能是R1模型文学创造力过强带来的副作用。
为了提升AI生成内容的可信度,突破大模型训练数据过时的局限,联网搜索与引用机制应运而生。2021年12月,OpenAI发布了WebGPT模型,这也是最早实现网页搜索并能够标注信息出处的大模型之一。
现在,联网搜索和引用功能已经成为不少主流AI工具的标配。但是,这真的可以使AI生成的内容更加准确吗?
02|AI幻觉,联网搜索也无法彻底规避
为了回答上面的问题,我们进行了一次简单的实验。我们模拟了一次专业信息查询的过程。在开启联网搜索的情况下,小组成员围绕着自己的专业情况对AI展开提问。我们选择了国内几款比较主流的大模型,对每个大模型在开启深度思考与不开启深度思考的情况下分别询问8个问题,总计提问400次。具体的实验流程如下:

在AI生成的400个答案中,有链接被引用的次数是3123次。然而,仅有1706次引用能完全支持AI生成的答案内容,仍然有45.37%的链接不能完全支持答案文本中的阐述。具体到模型的表现上,则是智谱清言和豆包的引用错误率较高,为50%以上。
也就是说,仍然有一定的概率,AI生成的内容与链接文章的内容无法实现完全匹配。如果不点开链接进行进一步确认,用户将会很容易地被“骗”过去。
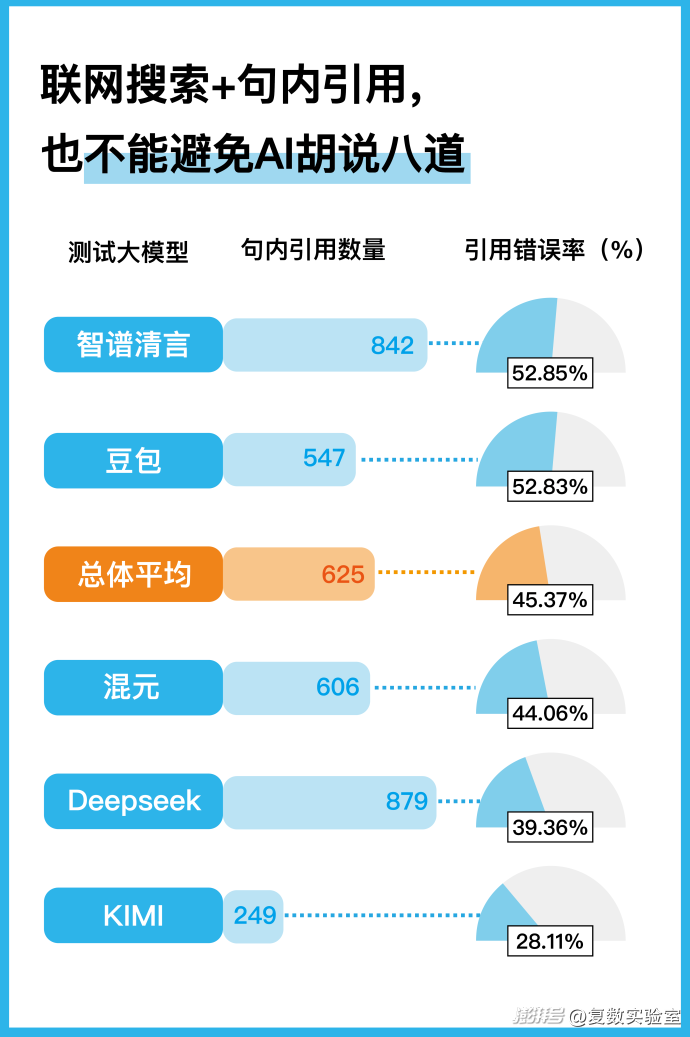
我们进一步观察了引用链接无法支持生成文本的具体情形。除了链接失效以外,我们重点关注了错误的类别,包括无中生有、张冠李戴、时间混乱、以全概偏、计算错误、以偏概全六类。其中,无中生有这一类错误尤为常见。在3123个引用中,无中生有类引用共计出现了952次,占比30.48%。

此外,由于现阶段这些AI工具并不具备事实核查的能力,只能从检索到的文本中进行学习。因此,即使生成答案标注了来源链接,也无法保证信息的真实性和准确性。
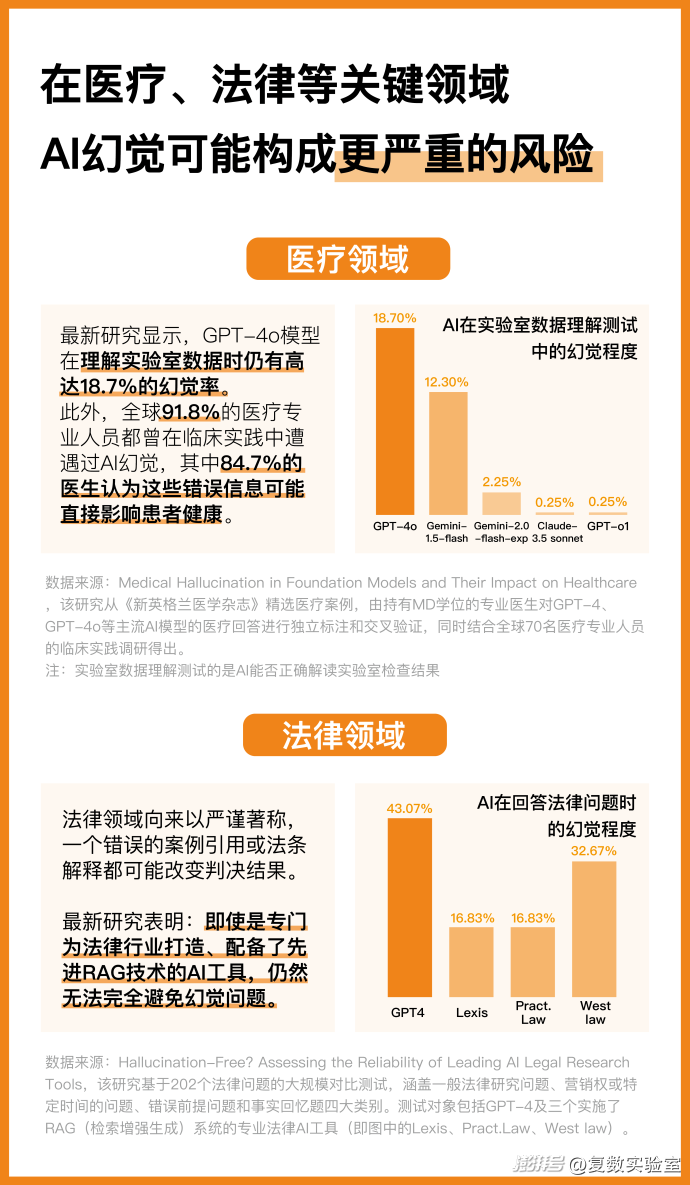
而脱离开我们所模拟的信息查询情景,AI幻觉也对我们的日常生活造成越来越切实的影响。尤其是在医疗、法律这些高度依赖信息准确性的领域中,AI幻觉可能会构成更严重的风险。
比AI幻觉本身更令人担忧的是,公众对这一风险仍然普遍缺乏警觉。
根据上海交通大学的研究结果,大部分人都没有对AI幻觉形成足够的认知:45.6%的受访者仅表现出模糊或轻微的担忧,缺乏对幻觉产生机制和误导后果的具体理解,29.7%的群体几乎没有意识到AI可能构成信息误导,对AI幻觉保持“高警觉”的人群仅占 8.5%。
作家Mathew Maavak这样表达他对AI幻觉的担忧:“我相信错误的数据和有缺陷的输入已经从AI系统流入交易和金融平台、航空控制、核反应堆、生化武器实验室和敏感的化学工厂——就在我写这篇文章的时候。”
但就像人工智能教父杰弗里·辛顿说的:“人们还不明白发生了什么。”
“我们就像拥有一只非常可爱的老虎幼崽的人。除非你能非常确定它长大后不会想杀你,否则你应该担心。”
03|和幻觉共生的未来
面对大模型的幻觉问题,大厂的技术引领者们持有着不同的看法。
一方面,大模型厂商认为基于 “预测下一个单词” 的训练机制,幻觉率归零 “非常困难”,公司只能通过迭代降低风险而非完全杜绝;另一方面,也有人期待,AI 幻觉只是大模型发展中的阶段性问题,可通过技术手段逐步解决。例如,微软就将幻觉视为 “可通过科学研究破解的机制问题”,并投入资源研究模型架构优化。
近年来,各个大模型厂商开始致力于运用各种方法消除AI幻觉。尤其是通过不断优化模型架构,例如:通过开发推理模型来降低AI幻觉。
从原理上来说,依靠“思维链”的推理模型,能够实现从拆解问题、逐步推导,再到得出结论的结构化推理,这样一来,模型就可以减少因逻辑错误产生的幻觉,并能通过对上下文的逻辑推导,更精准地把握信息间的关联,从而避免断章取义。
然而,推理模型的实际表现不尽如人意。
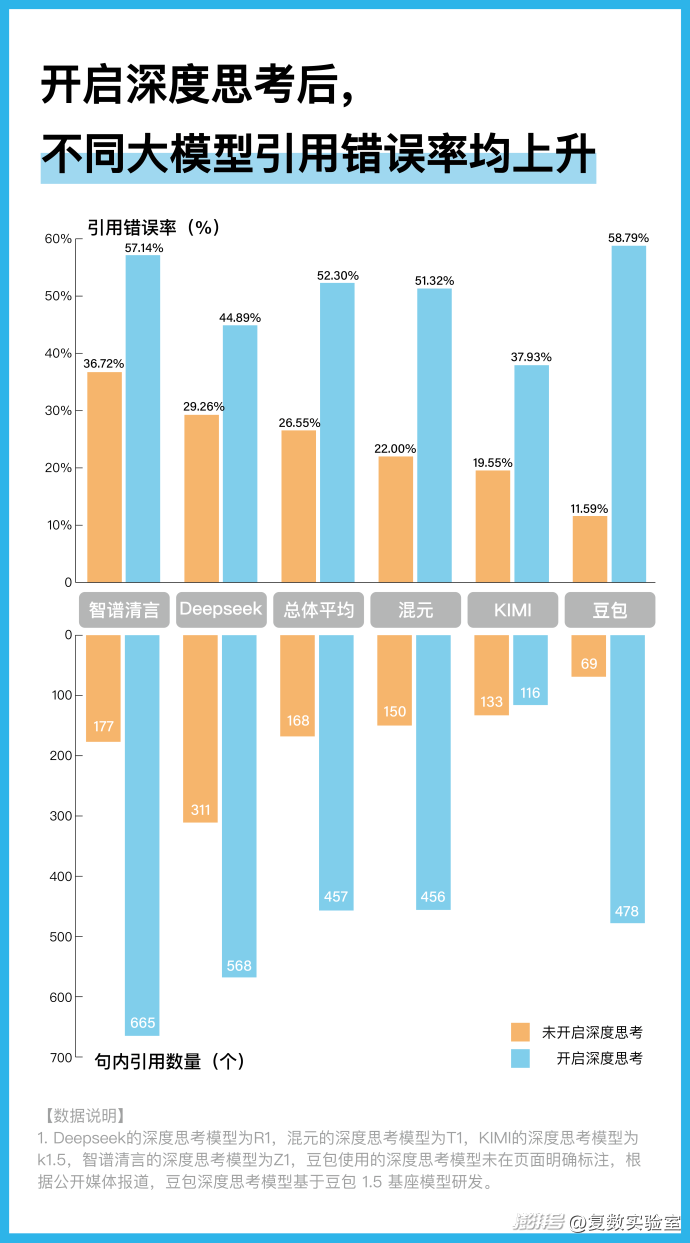
我们的小实验表明,在开启深度思考的情况下,除KIMI以外,所有的大模型的句内引用数都有所增加,但与此同时,大模型的引用错误率明显上升——不同大模型的引用错误率在开启深度思考后都达到了30%以上。
例如,在未开启深度思考模式时,豆包的错误率为11.59%,为五款大模型中表现最好的大模型;但在开启深度思考后,其错误率为58.79%,成为深度思考模式下引用错误率最高的大模型。
上述观察和实际的规律相吻合。根据OpenAI的内部测试,推理模型 o3 和 o4-mini 比该公司之前的推理模型 o1、o1-mini 和 o3-mini 以及 OpenAI 的非推理模型(如 GPT-4o)产生幻觉的频率更高。
采用专门优化的推理架构的DeepSeek-R1也出现了类似情况。在Vectara的幻觉评估测试中,其幻觉率高达14.3%,是前代模型DeepSeek-V3的近四倍。
如此看来,推理这个本来预期降低AI幻觉的功能,却增加了AI幻觉率。
有学者推测,这可能是由于推理模型倾向在事实间建立虚构连接,造成逻辑过度外推;另一方面,高推理模型不会轻易说 “不知道”,而是自信地输出一个符合概率的错误答案,甚至在初始假设错误的情况下,也可能基于错误前提进行下一步推理,这些情况都会导致推理模型的幻觉增加。
这背后的具体原理还有待学界的进一步探究。正如OpenAI在其针对 o3 和 o4-mini 的技术报告中写到的, “需要更多研究来理解为什么随着推理模型的扩展,幻觉会变得越来越严重。”
技术的进步需要时间。尽管目前人工智能技术取得了惊人进展,但很明显,它仍然远未达到可以被完全信任的程度。理解AI的局限性、学会与不完美的AI系统共处,或许是未来一段时间人机互动的常态。而在AI完全成熟之前,我们都是这场人机共存实验的参与者。
最好的生存策略,也许就是永远记住:再聪明的机器,也需要人类那颗会思考、会质疑的心来为它把关。
参考资料:
[1] Huang L, Yu W, Ma W, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions[J]. ACM Transactions on Information Systems, 2025, 43(2): 1-55.
[2] 字节跳动技术团队 - 一文搞懂 | 大模型为什么出现幻觉?从成因到缓解方案, https://mp.weixin.qq.com/s/vCz2kyitgtOjN669gbHd6g
[3] OpenAI - WebGPT: Improving the factual accuracy of language models through web browsing, https://openai.com/index/webgpt/
[4] 新华网 - “已读乱回”你有警觉吗?调研发现近七成公众对大模型AI幻觉低感知, http://sh.news.cn/20250610/3223aa0ca7654a63a0b8db7e5b40ee3c/c.html
[5] RT - AI hallucinations: A budding sentience or a global embarrassment?, https://www.rt.com/news/618100-ai-hallucination-global-embarrassment/
[6] Fortune - ‘Godfather of AI’ says AI is like a cute tiger cub—unless you know it won’t turn on you, you should worry, https://fortune.com/article/geoffrey-hinton-ai-godfather-tiger-cub/
[7] Microsoft - Why AI sometimes gets it wrong — and bigstrides to address it, https://news.microsoft.com/source/features/company-news/why-ai-sometimes-gets-it-wrong-and-big-strides-to-address-it/?utm_source=chatgpt.com
[8] OpenAI - OpenAI o3 and o4-mini System Card, https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
[9] TechCrunch - OpenAI’s new reasoning AI models hallucinate more, https://techcrunch.com/2025/04/18/openais-new-reasoning-ai-models-hallucinate-more/
[10] 清华大学新闻与传播学院新媒体研究中心 - DeepSeek与AI幻觉, https://www.lib.szu.edu.cn/sites/szulib/files/2025-02/DeepSeek与AI幻觉-清华大学-附知识库_0.pdf
[11] 36kr - DeepSeek-R1超高幻觉率解析:为何大模型总“胡说八道”?, https://www.36kr.com/p/3163559253993986K
[12] AP news - Researchers say an AI-powered transcription tool used in hospitals invents things no one ever said, https://apnews.com/article/ai-artificial-intelligence-health-business-90020cdf5fa16c79ca2e5b6c4c9bbb14
复旦大学新闻学院《数据新闻与可视化》(硕士生)课程作品
指导老师:徐笛
作者:夏昊扬 李林杰 宋语阳 唐小茗