Nature:AI正在耗尽人类数据,我们应该怎么办?


互联网是人类知识的汪洋大海,但并非无穷无尽。人工智能(AI)研究人员几乎把它吸干了。
过去十年来,人工智能的爆炸性进步在很大程度上是通过扩大神经网络和在越来越多数据上进行训练而实现的。事实证明,这种扩展(scaling)在使大语言模型(LLMs)更有能力复刻会话语言和发展推理等涌现特性方面的效果令人惊讶。但一些专家表示,我们现在已经接近了扩展的极限。部分原因是计算所需的能源不断膨胀,但也因为 LLM 开发者正在耗尽用于训练模型的传统数据集。
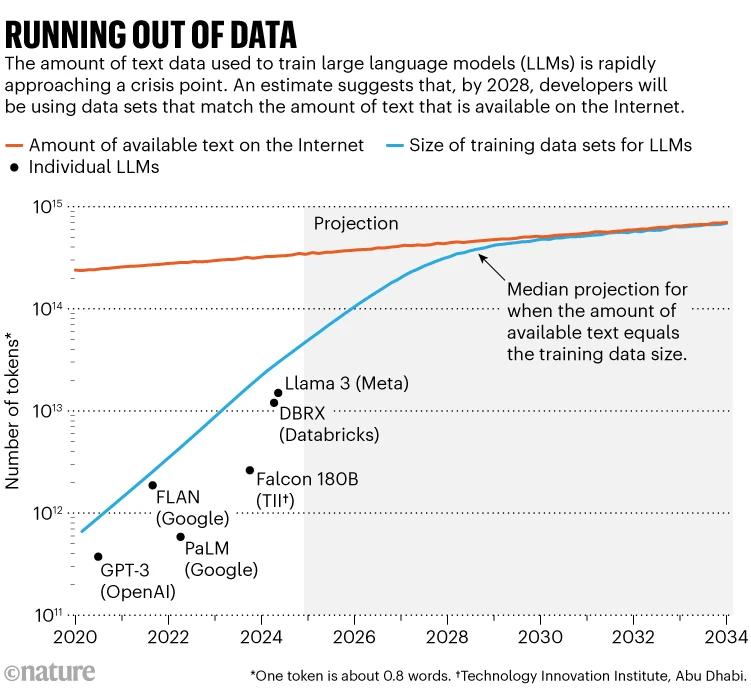
今年,一项著名的研究给出了一些数字,将这一问题推上了头条新闻:Epoch AI 研究人员预测,到 2028 年左右,用于训练人工智能模型的典型数据集的规模将达到公共在线文本的估计总存量。换句话说,人工智能很可能在 4 年左右的时间内耗尽训练数据。与此同时,数据所有者(如报纸出版商)也开始限制其内容的使用方式,从而进一步收紧了数据的使用权。麻省理工学院人工智能研究员 Shayne Longpre 表示,这正在导致“数据公共资源”规模的危机,他领导着数据出处倡议(Data Provenance Initiative),这是一个对人工智能数据集进行审计的基层组织。
训练数据即将面临的瓶颈可能已经开始显现。Longpre 说:“我强烈怀疑这种情况已经发生。”
尽管专家们表示,这些限制有可能会减缓人工智能系统的快速发展,但开发者们正在寻找变通办法。Epoch AI 研究员 Pablo Villalobos 说:“我不认为大型人工智能公司有人感到恐慌。或者说,至少他们不会给我发电子邮件表示恐慌。”
例如,OpenAI 和 Anthropic 等著名人工智能公司已经公开承认了这一问题,同时表示他们有计划解决这一问题,包括生成新数据和寻找非常规数据源。OpenAI 的一位发言人告诉《自然》:“我们使用多种来源的数据,包括公开数据、来自合作伙伴的非公开数据、合成数据生成和来自人工智能训练者的数据。”
即便如此,数据紧缩可能会迫使人们建立的人工智能生成模型类型发生变化,从大型、通用的 LLM 转向更小、更专业的模型。
数万亿训练 token
在过去十年中,LLM 的发展已经显示出其对数据的贪婪需求。尽管有些开发者并不公布其最新模型的规模,但据 Villalobos 估计,自 2020 年以来,用于训练 LLM 的“token”(即单词的一部分)数量已经增长了 100 倍,从数千亿增加到了数万亿。
Villalobos 估计,目前互联网上的文本数据总量为 3100 万亿 token,这可能是互联网上的一大部分内容,尽管总量巨大,难以确定。各种服务利用网络爬虫抓取这些内容,然后消除重复内容,过滤掉不受欢迎的内容,从而生成更干净的数据集:一个名为 RedPajama 的常用数据集包含数十万亿个单词。一些公司或者学者自己抓取和清理,从而制作定制的数据集来训练 LLM。互联网上有一小部分内容被认为是高质量的,比如经过人工编辑的、社会可接受的文本,这些文本可能出现在书籍或新闻报道中。
可用互联网内容的增长速度之慢令人惊讶:据 Villalobos 估计,其年增长率不到 10%,而人工智能训练数据集的规模每年增长一倍多。对这些趋势的预测显示,这两条线将在 2028 年左右相交。
与此同时,内容提供商正越来越多地加入软件代码或完善其使用条款,以阻止网络爬虫或人工智能公司获取其数据用于训练。Longpre 和他的同事于今年 7 月发布的一份预印本显示,许多数据提供商阻止特定爬虫访问其网站的情况急剧增加。在三个主要净化数据集中质量最高、最常用的网络内容中,限制爬虫访问的 token 数量,从 2023 年的不到 3% 已上升到 2024 年的 20%-33%。
目前有几起诉讼正在进行中,试图为人工智能训练中使用的数据提供商赢得赔偿。2023 年 12 月,《纽约时报》起诉 OpenAI 和微软侵犯他们的版权;今年 4 月,Alden Global Capital 旗下的 8 家报社联合提起类似诉讼。反方的论点是,应该允许人工智能像人一样阅读和学习在线内容,这构成了对材料的合理使用。OpenAI 曾公开表示,它认为《纽约时报》的诉讼“毫无根据”。
如果法院支持内容提供者应获得经济补偿的观点,那么人工智能开发者和研究人员将更难获得他们所需要的东西,包括那些没有雄厚资金的学者。“这些交易对学术界的打击最大,”Longpre 说。他补充说:“拥有一个开放的网络有很多好处。”
寻找更多数据
数据紧缩给人工智能的传统扩展策略带来了一个潜在的大问题。Longpre 说,虽然可以在不增加训练数据的情况下提高模型的计算能力或参数数量,但这往往会导致人工智能发展缓慢且成本高昂——这通常不是首要选择。
如果目标是找到更多数据,一种选择可能是获取非公开数据,如 WhatsApp 消息或 YouTube 视频的转录。尽管以这种方式获取第三方内容的合法性尚未得到验证,但公司确实可以获取自己的数据,一些社交媒体公司表示,他们使用自己的材料来训练人工智能模型。例如,Meta 公司表示,其 VR 头盔 Meta Quest 收集的音频和图像会被用于训练人工智能。然而,政策各有不同。视频会议平台 Zoom 的服务条款规定,该公司不会使用客户内容来训练人工智能系统,而转录服务公司 OtterAI 则表示,它确实会将去身份化和加密的音频和转录内容用于训练。
不过,据 Villalobos 估计,目前这些专有内容可能总共只有 4 万亿文本 token。考虑到其中很多都是低质量或重复的内容,他说,即使假设一个人工智能可以访问所有这些内容,而不会造成侵权或隐私问题,这也足以将数据瓶颈的时间推迟一年半。他说:“即使数据存量增加十倍,也只能为你赢得三年左右的扩展时间。”
另一种选择可能是专注于天文或基因组数据等专业数据集,这些数据集正在快速增长。“AI 教母”李飞飞已经公开支持这一战略。她在今年 5 月举行的彭博社技术峰会上表示,考虑到医疗、环境和教育等领域尚未开发的信息,对数据枯竭的担忧过于狭隘。
但 Villalobos 说,目前还不清楚这些数据集对训练 LLM 有多大的可用性和实用性。Villalobos 说:“许多类型的数据之间似乎存在某种程度的迁移学习。不过,我对这种方法并不抱太大希望。”
如果生成式人工智能可以在其他数据类型(而不仅仅是文本)上进行训练,其可能性将更为广阔。一些模型已经能够在一定程度上对无标签的视频或图像进行训练。扩展和改进这些能力可以为更丰富的数据打开大门。
今年 2 月,在加拿大温哥华举行的一次人工智能会议上,Meta 首席科学家、纽约大学计算机科学家、被誉为现代人工智能奠基人之一的 Yann LeCun 演讲中强调了这些可能性。用于训练现代 LLM 的 10^13 token 听起来很多:根据 LeCun 的计算,一个人需要 17 万年才能读完这么多。但是,他说,一个 4 岁的孩子在清醒时仅仅通过观察物体所吸收的数据量就比这多 50 倍。LeCun 在 AAAI 年会上展示了这些数据。
让人工智能系统以机器人的形式从自己的感官经验中学习,最终可能会利用类似的丰富数据。LeCun 说:“我们永远不可能通过语言训练达到人类水平的人工智能,那是不可能的。”
如果找不到数据,可以生成更多数据。为训练人工智能,一些人工智能公司花钱雇人生成内容,另一些公司则使用人工智能生成的合成数据。这是一个潜在的巨大来源:今年早些时候,OpenAI 表示他们每天生成 1000 亿个单词,即每年生成超过 36 万亿个单词,与当前的人工智能训练数据集规模相当。而且这种产出还在快速增长。
专家们一致认为,一般来说,合成数据似乎适用于有明确规则的领域,如国际象棋、数学或计算机编码。人工智能工具 AlphaGeometry 使用 1 亿个合成示例,在没有人类演示的情况下,成功训练出解决几何问题的能力。合成数据已经被用于真实数据有限或存在问题的领域。这包括医疗数据,因为合成数据不涉及隐私问题;也包括自动驾驶汽车的训练场,因为合成汽车碰撞不会对任何人造成伤害。
合成数据的问题在于,递归循环可能会固化错误、放大误解并普遍降低学习质量。2023 年的一项研究创造了“模型自噬障碍”(Model Autophagy Disorder)一词来描述人工智能模型如何以这种方式“走向疯狂”。例如,一个部分基于合成数据训练的人脸生成人工智能模型开始绘制嵌有奇怪哈希标记的人脸。
或许可以「以少胜多」
另一种策略是放弃“越大越好”的概念。尽管开发者仍在继续构建更大的模型,并通过扩展来改进他们的 LLM,但许多人正在追求更高效、更小的模型,专注于单个任务。这些模型需要提炼、专业的数据和更好的训练技术。
总的来说,人工智能已经在用更少的资源做更多的事情。2024 年的一项研究认为,由于算法的改进,每 8 个月左右,一个 LLM 实现相同性能所需的计算能力就会减少一半。
随着人工智能专用计算机芯片的问世以及其他硬件的改进,人工智能为以不同方式使用计算资源打开了大门:一种策略是让人工智能模型多次重读训练数据集。斯坦福大学博士生、数据溯源计划(Data Provenance Initiative)成员 Niklas Muennighoff 说,虽然很多人认为计算机具有完美的记忆能力,只需要“阅读”一次资料,但人工智能系统是以一种统计方式工作的,这意味着重新阅读可以提高性能。在 2023 年发表的一篇论文中,他和他的同事在 HuggingFace 工作时发现,一个模型在重新阅读给定数据集 4 次后所学到的知识,与阅读相同数量的唯一数据所学到的知识一样多——尽管重新阅读的好处在此之后很快就消失了。
尽管 OpenAI 没有透露其 o1 模型的规模或训练数据集的信息,但该公司强调,该模型采用了一种新方法:花更多时间进行强化学习(模型获得最佳答案反馈的过程),花更多时间思考每个响应。观察家们认为,这种模型将重点从海量数据集的预训练转移到了训练和推理上。Longpre 说,这为扩展方法增添了一个新的维度,尽管这是一种计算成本高昂的策略。
LLM 在阅读完互联网上的大部分内容后,有可能不再需要更多数据,就能变得更聪明。卡内基梅隆大学研究人工智能安全的研究生 Andy Zou 说,人工智能可能很快就会通过自我反思取得进步。Zou 说:“现在,它已经有了一个基础知识库,这可能比任何一个人都要强大,”这意味着它只需要坐下来思考。“我认为我们可能已经非常接近这一点了。”
Villalobos 认为,从合成数据到专业数据集,再到重新阅读和自我反思,所有这些因素都将有所帮助。“模型既能自我思考,又能以各种方式与现实世界互动——两者的结合可能会推动前沿技术的发展。”
原文链接:
https://www.nature.com/articles/d41586-024-03990-2
翻译:李雯靖
如需转载或投稿,请直接在公众号内留言素材来源官方媒体/网络新闻继续滑动看下一个轻触阅读原文

学术头条向上滑动看下一个
原标题:《Nature:AI正在耗尽人类数据,我们应该怎么办?》