研究没思路的看过来,这是可信机器学习的1000个创新idea

机器之心专栏
作者:UIUC 汪浩瀚
I. 前言
1. 先讲一个故事
大概在 4-5 年前的时候,我还是卡内基梅隆大学(CMU)的 phd。身处在名校光环的照耀下,再加上顶级导师的加持,我对于科研和创新一向有极高的标准。我们决定要花时间的东西,一定不能是简单的东西。而且有很长一段时间,我一直以为大部分人都是这样想的。
直到有一次,在开会的时候我看到一个女孩在展示一个 poster,内容大概就是把 LSTM 用在基因表达(gene expression)上的预测效果比上个时代的 SVM 之类的效果要好。这实在是没有什么意外的,毕竟当时大家已经知道了,RNN 家族(就比如 LSTM)是序列数据(sequence data)上的绝对王者。我当时也没客气,直接就问了上去,
“就这么用一下有什么了不起的么?”
结果她的回答不卑不亢:
“没什么了不起的。真正的创新是你们这些读的了 CMU 的人该做的事,我做不到,我只想发个 paper,赶紧毕业,然后找个工作。”
这是我第一次感受到大家追求的参差,毕竟平时在学校里面,就算有人真的一直在灌水,他也不会承认的。
从此以后,我再也不想质疑别人的工作是不是在灌水了,毕竟大家的起点,经历,现实的诉求,和人生的愿景等等都不一样。
2. 简单说说这篇文章的背景
毕业后来到伊利诺伊大学厄巴纳-香槟分校(UIUC) 当了一年的 faculty,尽管我的 lab 很初级,但也尽量坚持做我们认为对得起人生追求的工作。在追赶学术会议 deadline 的同时,最近也放出了第一份我们认为出彩的工作【1】:
Liu, Haoyang, Maheep Chaudhary, and Haohan Wang. "Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives." arXiv preprint arXiv:2307.16851 (2023).
我们整理了可信机器学习的各个领域,诸如 “鲁棒性”,“对抗”,“可解释性”,和 “公平性” 的数学思想。这篇文章的整理从几年前的单模型时代跨越到现在的大模型时代,而且注意到,尽管机器学习的研究跨越了时代,这些数学思想甚至几乎没有改变。
整理这些东西一个最显而易见的好处就是可以帮助大家更好的了解这个领域,尽管这些年接触可信人工智能(trustworthy AI)的人很多,但是我认为真正懂这个东西的人少之又少。比如有很多人认为领域泛化(domain generalization)不过是在一套新的基准上刷刷性能。我们整理的这份工作希望能够让大家更全面的了解这些领域。
然而更重要的是,整理工作让大家够以更加高屋建瓴的视野看待可信机器习相关问题。在整理这个工作的时候,我就经常跟两位同学说,等我们弄完了,你应该轻易就会有 1000 多个继续发文章的 idea,他们也非常认同。
可是真正的问题从来不是有没有这些 idea,或者所谓的 “创新点”。而是这些 idea 是不是值得花大家的时间。我不允许我自己的 phd 做这种简单的 paper,这是一个慢慢贬低自己的过程。像 maheep 这样的 intern,想弄就弄吧,毕竟他还得攒点经历将来用来申请 phd。
那么我们整理出来的那么多个 idea 有什么用呢,不如索性把它们写出来送给需要的老师同学们。
不过这些 idea 估计也就能帮助一下像和上文提到的女孩有一致追求的同学,发发文章,毕业找工作用。有真正学术追求的同学可能不适合,毕竟能够真正有潜力创造一个时代的 idea 谁也没有多少,这一类有潜力的 idea 我更希望看到我自己的 lab 来推进。
3. 再说说为什么认为可信很重要
在 2016-17 年 ResNet 100 层刚出来的时候我就说过,这么巨大的结构其实不能只用准确率来评价,因为没有证据证明 SOTA 准确率其实来自于模型学到了真正有用的东西而不是数据集里面的混杂因素(confounding factors),毕竟对于如此巨大的模型,ImageNet 的体量就显得小了,混杂因素存在的可能性就大多了。只不过那个时候太幼稚,我不知道这些理念其实是可以用来发 paper 的......
到最近无论是 Dall-E,ChatGPT,Stable Diffusion,还是 SAM 等等,我也一直跟我的学生说,不用看这个模型各个似乎神乎其技,其实很大程度是因为用户还没有习惯于使用这些模型,就像当年 100 层的 ResNet 一样,刚出来的时候就有新闻说新的时代要来了,计算机视觉要被解决了,ResNet 确实带来的一个新的时代,但与其说是解决的计算机视觉,更多的是让我们看到了计算机视觉以前大家没有太关注的问题,例如可信下的各个子问题。我认为这是因为 ResNet 的巨大成功让我们看到了在日常生活中大规模依赖计算机视觉的可能性,进而当我们真的用它时,可信的各种问题就随之而来了。
ChatGPT 等等也是一样,远远领先了一个时代,但是等你适应了他的时代,用的久了,就会发现可信的问题就全都回来了。
II. 背景
1. 究竟什么是可信机器学习
可信机器学习一般认为是几个子领域的一个统称,究竟有哪些子领域似乎也没有一个确切的范围,但通常大家认为比较重要的子领域包括
鲁棒性:比如领域自适应(domain adaptation)、领域泛化等等的领域,这些领域主题就是说机器学习在应用(testing)时面对的数据通常和训练时的数据有一定的差异,如何保证这些差异不会对模型的性能造成影响。
对抗鲁棒性(安全,security):最著名的大概就是熊猫的那张图片,一般来讲就是研究模型对于只有一点微小的扰动过的数据是否依然能够保持原来的性能,这些微小的扰动并不是随意添加的,需要精细的算法专门生成。
可解释性:顾名思义,简而言之就是模型的工作过程机理等等是否能够解释出来让用户明白。具体的定义更是五花八门。
公平性:一方面是说模型的工作过程中有一些过于敏感的信息(比如性别,年龄,家庭背景等等)不应该被使用。另一方面是说一些少数族裔会在统计的过程中被自然的过滤掉,而这是不应该的。
我们的工作大概就包含了上面四个子领域,其他的,比如隐私保护,也通常被考虑在可信及其学习的范畴内。
我认为一个很多人忽视的问题:可信机器学习,从它的定义源头来讲,它就不是一个单纯的统计题目。可信机器学习,到底是谁来信,谁来认为是否可信。一个可解释模型,给人看能看懂,给宠物看就看不懂了,算不算可解释,那如果反过来,算不算可解释呢?每个地区的教育水平不同,那时保持相同的一本录取率算公平,还是全国一张卷算公平呢?这些问题本来就没有确定的答案,机器学习研究本身其实也没有必要回答。我们要做的其实就是当决策者定义出了一种 “可信”,我们能够把相关的方法做出来。但是做到这一点的前提就是要承认,“可信”(以及 “鲁棒”,“可解释”,“公平”)等等都是主观的。
在我们的文章里,我们用下图阐释了为什么 “鲁棒性” 是一个主观的概念, “semantics”,“suprious”(或者“shortcut”等等)的定义也是一个主观的概念。
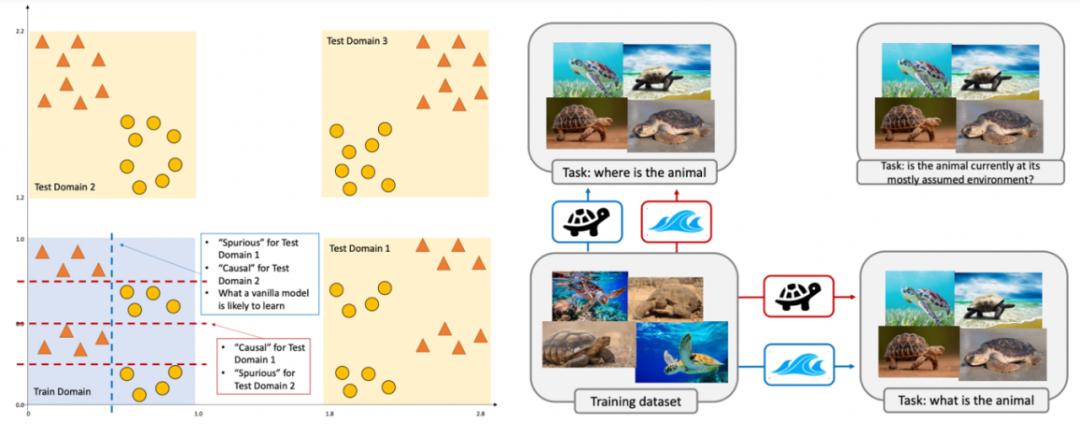 图 1. 可信机器学习的数学是通用的,但是什么才是 “可信”,其实是很主观的问题。比如我们要海龟和海洋通常有很强的相关性,那我们预测的究竟是动物还是环境就决定了哪个信号是 “semantics”,哪个是 “spurious”。
图 1. 可信机器学习的数学是通用的,但是什么才是 “可信”,其实是很主观的问题。比如我们要海龟和海洋通常有很强的相关性,那我们预测的究竟是动物还是环境就决定了哪个信号是 “semantics”,哪个是 “spurious”。而这张图也是从我之前的一篇文章【2】的中的更简单的图演变而来。
2.“可信” 的挑战从何而来
训练一个 “可信” 的机器学习模型并不是一件简单的事情,这里可能有很多理由,我们认为其中最主要的是数据本身带来的挑战。同时我们也认为这是近年来 Data-centric AI(DCAI)变得越来越重要的一个原因。下面这张图,是我多年来一直在尝试阐述的,现代机器学习最核心的挑战之一。
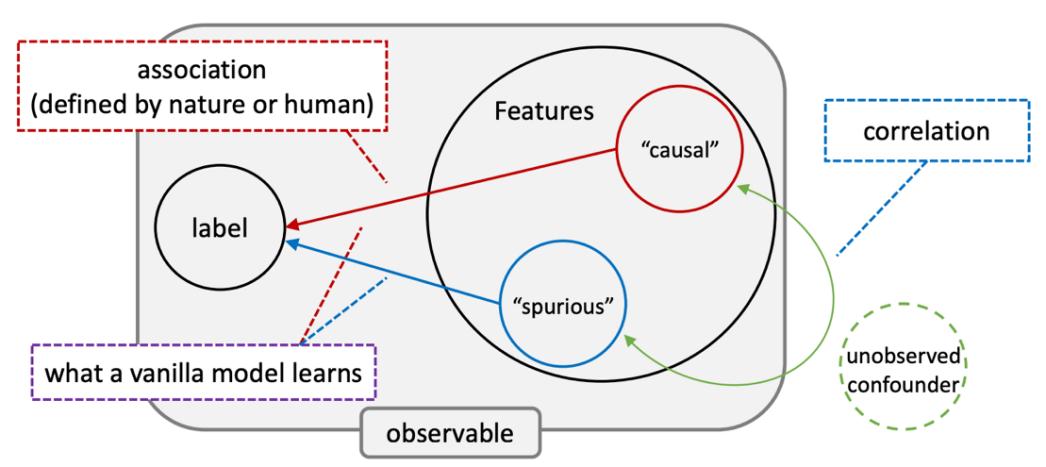 图 2. 我认为现代机器学习最核心的挑战之一,数据因为历史原因充满了各种 spurious correlation 或者偏见等等,这直接导致了深度学习这种依赖大量数据创造奇迹的方法在实际应用中到处都有可信的问题。
图 2. 我认为现代机器学习最核心的挑战之一,数据因为历史原因充满了各种 spurious correlation 或者偏见等等,这直接导致了深度学习这种依赖大量数据创造奇迹的方法在实际应用中到处都有可信的问题。这张图同样演变于我以前的一篇 paper【3】。
3.“可信” 解决问题的框架(范式)
据我们观察,大量的可信机器学习方法全部来源于 3 种主体框架(或者称之为范式)。
3.1. 类似于 DANN(domain adversarial neural network)类的方法
大概是用来解决最简单直接的办法。领域自适应主要想解决的问题是一个机器学习模型的训练数据集来自于一个领域(比如照片),而测试数据集来自于另一个领域(比如素描)。我们主观的认为,一个优质的模型,如果在照片中能够识别猫狗长颈鹿大象之类的动物,那么这个模型在素描中也应该能识别出这些动物(关于这个假设的数学模型,可以参考我们在 2022 UAI 的一个工作。【2】)
那么,怎么保证一个模型能够实现领域自适应呢?
最直观的方法大概是去训练一个模型,保证这个模型不会学习到任何与领域本身相关的特征(即模型无法区分一张图片是照片还是素描)。
那么如何保证一个模型无法区分一张图片是照片还是素描呢?
我们先来回答一个特别简单的问题:怎么保证一个模型能够区分一张图片是照片还是素描。答案很简单,用数据对应的领域信息作为相应的标签(label),训练一个有效的领域分类器(domain classifier)。
有了这个领域分类器,在解释下一步之前,先阐述这样一个事实:对于任何一个(没有循环(recurrent)结构的)深度学习模型,我们可以指定任意一层把它切开,把这层前面的称之为编码器,这层后面的称之为解码器,这层的信息我们就把它叫做表征。
现在把这个领域分类器当做解码器。我们现在想办法让这个领域分类器无法识别领域,但是这个领域分类器已经训练好了,我们不能改变它,那唯一的办法就是我们用编码器改变这个领域分类器的输入,让相对应的表征无法被领域分类器所识别。
然后别忘了,我们的最终目的是保证模型能够区分猫狗长颈鹿大象之类的动物,所以还要同时有一个正常的分类器作为解码器。
而把这些组合到一起,就是 domain adversarial neural network(DANN)【4】。
以上这些介绍尽管是基于鲁棒性中的最简单的领域自适应,但是同样的方法可以应用在可信的诸多领域,比如几乎一样的方法可以用来解决公平的问题,把领域分类器从两个领域拓展的多个领域就是好几篇领域泛化的 paper。我们的 survey 里整理了很多很多工作,表面看起来万千姿态,但是其实数学内核全都如出一辙,感兴趣的老师同学们可以具体读读我们的 survey。
还有一个家族的方法也是基于 DANN 的体系,稍有不同的就是这个领域分类器不再是通过类似 domain ID 一样的标签训练出来的 classifier,而是通过一些特别的架构得到的只能学习某一类的特征,比如我们做过的只学习纹理(texture)特征的,只学习 patch 的。更通用一点的用一个弱分类器(weak classifier)来扮演这个角色的。但是我个人认为这一系类的方法在他们自己的基准上还可以,但是在更广泛的任务中通常不太行。更多的相关讨论都在我们的 survey 中。
3.2. 最坏情况下(worst-case)的数据增强以及相关的正则化(regularization)
数据增强(data augmentation)大概是最简单直观的提高模型性能的方法之一了。在可信机器学习中,数据增强也发挥了巨大的作用。只不过更具有代表性的是 worst-case 的数据增强。相较于普通的数据增强(随机的对数据进行一些变换),worst-case 的数据增强最大的特点就是这些变换不是随机选择的,而是选择那个能够让损失(loss)变得最大的变换。
这一系列的方法效果最显著的就是在对抗鲁棒性(adversarial robustness)的研究中,最简单而且有效的方法就是直接用 attack 对应的方法来生成数据,然后用这些数据来训练,效果拔群【5】。
在通用的鲁棒性研究中,如果是旋转,翻转之类的,或者 mix-up 家族的增强,把这种随机增强换成 worst-case 的,收益通常非常小,而且由于是 worst-case 而不是随机,计算复杂度要多很多(要么用梯度(gradient)来帮忙,要么每个增强一个 forward 来选择),所以恐怕不值得。
另一种是用 GAN, VAE, 或者更新的 AIGC 系列模型来辅助生成数据。把 GAN 或者 VAE 的计算图(computation graph)和要训练的模型连到一起,通常可以很方便的实现 worst-case 的增强(可以直接使用模型的梯度信息),但是把这些模型加进主模型中本身就增加了相当的计算复杂度。
然后这里有一个很有意思的问题,如果我们用 GAN 或者 VAE 来生成数据,生成出来的数据和原来的数据差的太远,标签不一样了怎么办。所以这里必须要有人为定义的一个标准来保证生成的数据和原来的数据不会离的太远。
其实所有的数据增强都有这个问题,比如用那些变换来增强数据,或者在对抗鲁棒性里允许的差异是多大,而这些就是这一系列方法中 “主观” 的成分。
然后在通用的鲁棒性系列中,还有一种 worst-case 增强相对隐蔽一些,我们做的 RSC 相当于说把模型切成编码器和解码器,然后在中间的表征上做 worst-case 增强【6】。这个简单的方法似乎效果很好,不仅在当时的领域泛化 leaderboard 轻松达到 SOTA,我后来在几个生物数据上尝试效果也都不错。
既然我们增强的数据,现在每个数据至少有两个 copy,那是不是会有一些正则化能够把每组两个数据的这种模式更好的利用起来。我认为没有比下图更能说明白这件事的了。
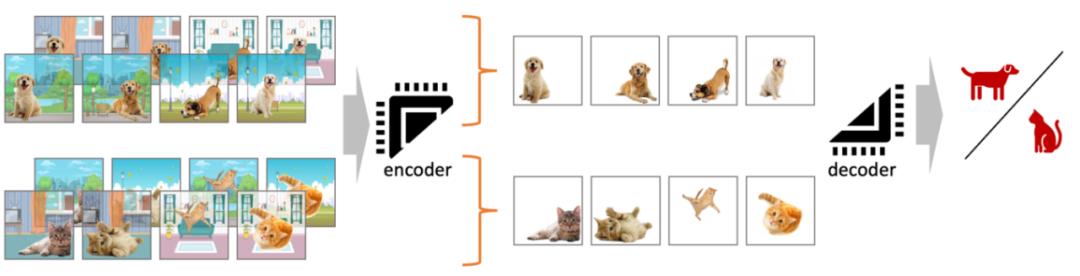 图 3. 与数据增强可以无缝衔接的正则化。这张图来自于我的另一个工作【7】。比如我们拿猫狗分类器来举例子,我们要做一个模型来分类猫和狗,但是通常我们发现猫多数时候待在室内,而狗更喜欢待在室外,这样训练出来的模型显然不够好,因为可能只是在学室内室外而不是猫和狗的信息。我们要克服这个问题,最简单的办法就是用数据增强,画一些室内的狗和室外的猫出来。可是仅仅这样还是不够,因为还有可能有在游泳的狗或者哪天猫上了太空怎么办。于是,一个策略就是想办法让模型无视掉所有的背景。就想上面那张图,我们输入一对数据,然后让模型找到这一对数据中的共性,无视掉所有类似于背景的东西。
图 3. 与数据增强可以无缝衔接的正则化。这张图来自于我的另一个工作【7】。比如我们拿猫狗分类器来举例子,我们要做一个模型来分类猫和狗,但是通常我们发现猫多数时候待在室内,而狗更喜欢待在室外,这样训练出来的模型显然不够好,因为可能只是在学室内室外而不是猫和狗的信息。我们要克服这个问题,最简单的办法就是用数据增强,画一些室内的狗和室外的猫出来。可是仅仅这样还是不够,因为还有可能有在游泳的狗或者哪天猫上了太空怎么办。于是,一个策略就是想办法让模型无视掉所有的背景。就想上面那张图,我们输入一对数据,然后让模型找到这一对数据中的共性,无视掉所有类似于背景的东西。大概意味着我们现在可以用一个正则化来要求模型把一组数据只学习其中一致的部分。
这种正则化和增强的组合也是浩如烟海,毕竟任意定义一个距离度量(distance metric)就可以创造一个方法。我们在去年的一个工作中【7】尝试为这一类的工作做出了一个概述。我非常喜欢当时我做的 related work 部分,里面说虽然有一些方法现在还没有,将来反正也会被发明出来,不如索性现在一起讨论了。只不过我们讨论完了之后发现,额,这些方法可能也没有必要被发明出来了。
另外,我提出这一套 idea 的时候经常收到一个问题 “这和对比学习(contrastive learning)是不是很像呢?”“是吧,只是多了监督损失(supervision loss)”。“那不就是把对比学习搬过来了吗?” “这么理解倒也行,不过这些工作远远早于对比学习。”
3.3. 样本重加权方法
这一系列方法的家族较前两个家族相对小巧一些,不过也已经非常多了。
方法直观理解起来比较简单,在很多鲁棒性和公平性的任务中,有一些数据点因为本身在某些意义上属于少数群体,模型很容易忽视这些数据,让模型更加重视这些数据最直观的方法就是为这些方法添加权重。那么怎么去找到这些样本,怎么增加这些权重就是创新的空间。
我们把这三个家族的方法整理在下图中了。
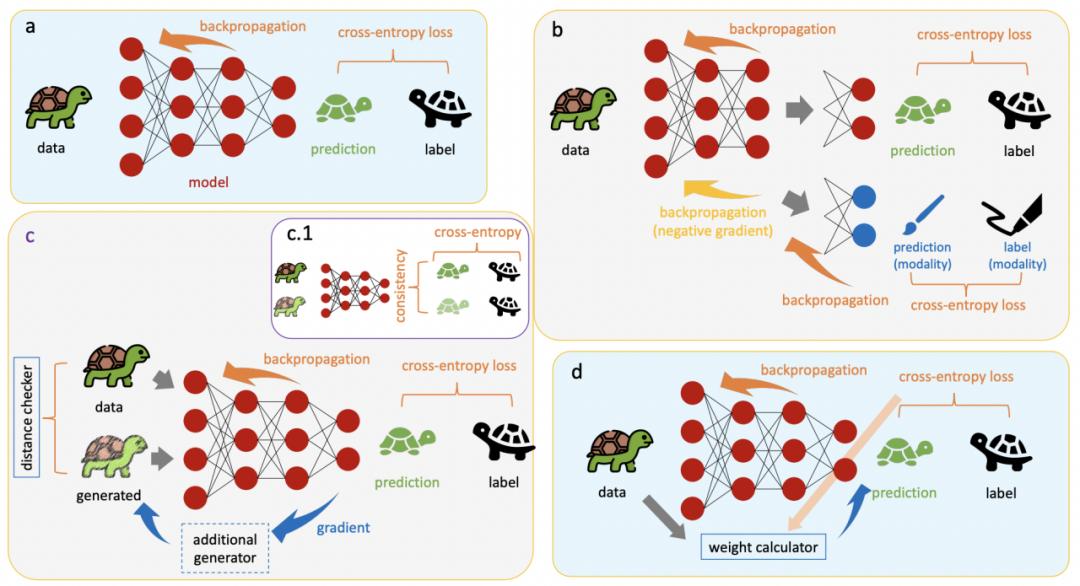 图 4. 我们的 survey 整理的可信机器学习的三大框架(范式),数百甚至数千篇文章都遵循这个基本的框架,无论是鲁棒性、公平性、对抗性,甚至可解释性。(a)基本的 ERM baseline。(b)向 DANN 范式的延伸。(c)向数据增强范式的延伸,其中 c.1 是增加了正则化之后的效果。(d)是向样本重加权角度的延伸。
图 4. 我们的 survey 整理的可信机器学习的三大框架(范式),数百甚至数千篇文章都遵循这个基本的框架,无论是鲁棒性、公平性、对抗性,甚至可解释性。(a)基本的 ERM baseline。(b)向 DANN 范式的延伸。(c)向数据增强范式的延伸,其中 c.1 是增加了正则化之后的效果。(d)是向样本重加权角度的延伸。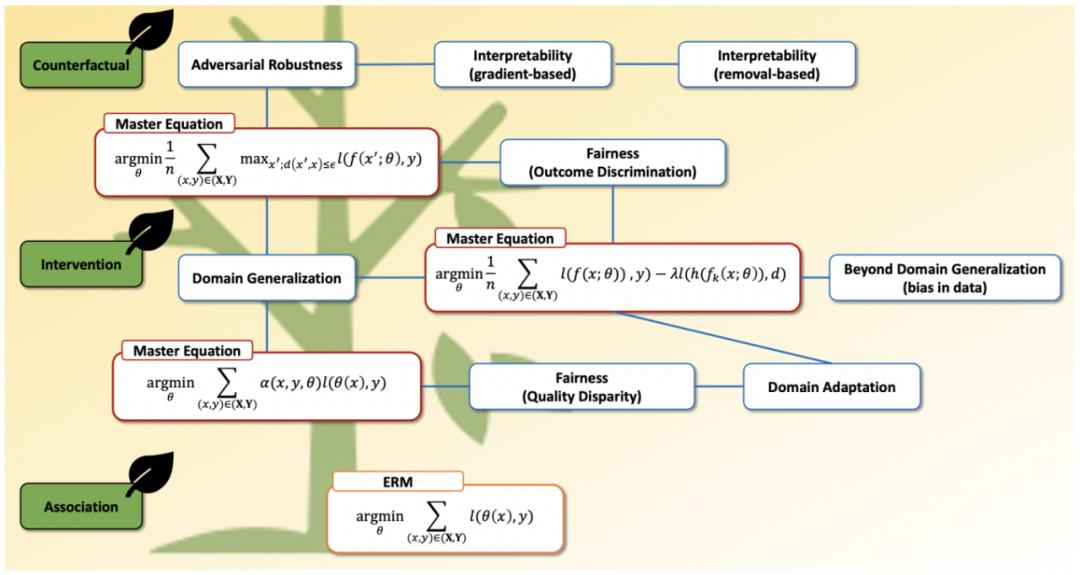 图 5. 这三个范式(红色)与 ERM baseline(橙色)和各个领域(蓝色)在数学上的联系。这篇文章恐怕只能简单的概括一下各个方法,对于更深层次的数学联系,还请阅读我们的 survey。
图 5. 这三个范式(红色)与 ERM baseline(橙色)和各个领域(蓝色)在数学上的联系。这篇文章恐怕只能简单的概括一下各个方法,对于更深层次的数学联系,还请阅读我们的 survey。我们也尝试过把第二个和第三个家族的方法放到一起【8】,做出来的方法其实我个人非常喜欢,而且我曾经让同学把这个方法在药物测试的 OOD 数据集上尝试了一下,瞬间性能就提升到了怀疑代码有 bug 的程度。
我个人一直在追求统计视角下这三个范式的大一统理论,也有一点尝试【2】,不过这篇文章也经常被诟病过于晦涩,我也在考虑为这篇文章写一个 blog 解释一下。
III. 回到标题 - 1000 个创新点
先回答几个问题:
真的有 1000 个么?--- 我认为差不多,不过重要的从来都不是数字,而是原理。其实我认为如果谁真的可以像我自己这么熟悉我们的 survey 的话,1000 个实在是太过于谦虚了,不过我也确实不太可能有精力把整个 survey 在这里解释一遍。
都能用来发顶会么?--- 不好说,但是每年顶会里肯定都能看见类似的文章发表,只不过不知道投的有多少。
你为什么不自己留着发 paper 呢?--- 这些 idea 不足以反映我对学术的追求,而且甚至更有追求的 idea 我现在都有点溢出了,根本用不完。
终于开始进入正文了,为了更好的介绍,先说清楚下文的介绍讲分为如下四个板块。
还是得先用最传统的 ERM 结构介绍一些每一类可信机器学习方法的,从我跟学生的交流看来,这些方法似乎是最符合一个年轻同学对 “创新” 这两个字的理解的。
然后追随一波潮流,证明一下重要的从来都是方法的本质,而 ERM 结构或者大模型都只是这些方法本质具象化的媒介。所以同样的范式在大模型下基本都适用。
然后更进一步的,这几个方法可以互相借鉴,带来更好的效果。
最后实在不行,做做应用。很多应用问题都天然的要求模型必须要至少鲁棒,毕竟既然是应用,就得要模型真的有用。
4.1 从 ERM 的展开
4.1.1 从 ERM 展开 - DANN 及其延伸
前面也说过了,作为最经典的方法之一,DANN 已经被重复利用太多次了,比如最简单,直接把 domain-invariant 对标到 sensitive-covariate-inviariant 就是新的方法,直接把两个 domain 的 invariant 变成多个 domain 的 invariant(从 domain adaptation 到 domain generalization)又是一个方法,不过这两个在我印象里已经被大同小异地发表过太多次了。
下面说说(我感觉)没有被怎么发表过的。首先 DANN 最突出的特色就是那个用来做 domain invariant 的分类器。那既然有这么一个分类器,其实非常自然的人们就可以思考:是不是如果这个分类器变得更好,那么 DANN 本身及其架构下的方法都会变得更好。然后最简单的想法就是把这个分类器(现行的一般就是个普通的 MLP)武装起来,从基本的 dropout,到稍复杂点的归一化(normalization)体系(batchnorm,layernorm 以及后来的各种变形),到更体系化的注意力(attention)家族,甚至还可以搞一套对抗训练(adversarial training)让这个小的分类器对小型扰动(perturbation)更加鲁棒。各种技巧不胜枚举。然而很有意思的是,这个角度如此的系统和规矩,却似乎从未被人仔细的探索过。
相比较之下,大家似乎更加执着于一些更加具体,随性的方法。尽管其本质也是让这个小的分类器变得更好,但是更多的技巧都是 case-by-case 地设计出来的。比如我们 survey 里提到过的一些方法,这里不再赘述了。这种方法的设计需要一些对于问题本身的理解,更好的一些直觉,所以想体系化的一下产生 100 个 idea 可能还比较难。不过如果有人想批量试试,很简单的思路就是去看看领域自适应或者领域泛化这些里的在更大规模的实验中证明过自己的方法时候可以在 公平性相关的问题中有所作为。当然反过来也是一样,只不过领域自适应和领域泛化发展的比较早,反过来能有效的几率小了一点。
4.1.2. 从 ERM 展开 - 数据增强的延伸
数据增强整个家族的方法通常给人一种很简单的感觉,在这上面的创新其实也不难。
在这里,我们就不说如何增强了,无论是旋转,翻转,还是在频域搞点什么事情,稍加思考,总是能找到一些能用的数据增强的方法的。这里我们主要说说当我们有了数据增强之后,或者说当我们观察到简单的增强可以帮助我们之后,改怎么进一步提高性能。
直接转为 worst-case 的方法。当我们知道了什么增强能够帮助我们提高性能之后,最简单直接的方法就是直接把原来的 IID 增强(对每一个样本随机抽样一种增强的方法)直接改为 worst-case 的增强(对每一个样本选择那个让训练损失变得最高的增强方法)。这个方法最差也不过是和原来的那种增强效果相同,而且几乎 100% 保证提高效率,即在更少的 epoch 数下提高性能。不过这么简单的东西也有弊端,毕竟选择那种增强可以称之为 worst-case 需要更多的计算量,如果增强本身是梯度的一部分还好一些,如果不是,反复的前向传播(forward pass)来计算损失不仅量大,而且显得很臃肿。这些计算带来的收益未必比得过更少的 epoch 带来的收益。另外,这种方法也非常适配 dropout 之类的数据扰动(data perturbation)类的方法,我们曾经做过一个效果非常好的方法叫 RSC【6】。
数据增强 + 正则化。另一个几乎 100% 带来收益的方法是加一个正则化。尤其是在鲁棒性相关的评估 上。几乎任何一个距离度量都会带来一个新的方法,我们在曾经的文章【7】里也说过(数据增强的方法 X 各种距离度量 X 应用)就会带来近乎无限的收益。只不过有一点,根据我的经验,这个收益往往来自于鲁棒性相关的评估上,而不是 iid 上的准确率评估。另外,这个角度和上一个角度互相是兼容的,只要有一个增强似乎有可能有效,几乎可以马上升级成此类方法。
那如果找不到哪个数据增强的方法能来用怎么办呢?一个最简单直观的方法就是直接在模型上绑个 GAN 一类的生成模型,然后用这个模型来一边生成数据,一边拿去给模型训练。这一类的方法一个很天然的好处就是把 GAN 之类的模型绑上去的时候,梯度往往已经连接到了一起,这样天然就可以把普通的数据增强升级成 worst-case 的版本的。当然,有任何一个增强,就可以直接升级成带正则化版本的。最后,这一套方法还有一个好处就是可以随着生成模型的升级无限升级,从 GAN 到 VAE 再到 diffusion,只要有更好的生成模型,这一套 idea 可以一直发展下去。
4.1.3 从 ERM 展开 - 样本重加权的延伸
同数据增强一样,这一套方法其实在机器学习的世界里早已是硕果累累。即使是现在,在基础的机器学习课程中,加权最小二乘法(weighted least square)也经常作为线性回归(linear regression)的自然延伸讲授。只不过可能深度学习最开始出来的时候大家认为这种方法非常自然,即使这类方法可以提高准确率,大家似乎也没有把它当做真正的方法拿来考虑的必要。后来深度学习的现实意义越来越多,大家意识到 under-represented 的问题比比皆是,然后再次意识到给样本加个权重这种自然的方法有很大的意义。
最早期的方法就是损失越大,权重就越大,这样这个模型就会更关注这个样本。后来衍生出各种估计权重的方法。我猜测这一类方法的一个终极形态就是用另一个深度学习模型来估计权重。如果这一天真的出现了,大概也是为了提高性能无所不用其极的典型了。我认为一个方法如果走到了这一步,现实意义就很小了,所以只适合那些需要发发 paper 的同学。
4.2 大模型的时代
我们做这个 survey 的时候,最让人激动的地方就是这里面很多系统性的思维,都可以直接衔接在大模型这个时代的方法中。为了做到这个衔接,我们首先把大模型时代的典型 prompt 结构翻译成更常见的形态。
首先,在大模型时代之前,几乎所有的模型都是在 ERM 的架构上建立出来的,也就是说,几乎所有的模型都是下面这个公式的某种延伸,如我们在图 5 中展示的那样。
可是到了大模型时代,很多方法都不能是 ERM 的延伸了,毕竟重新训练一个模型变得不现实了,于是有了各种利用已经训练好的参数的方法诞生了。首先是最简单的 微调(fine-tuning),然后又有了 prompt 和 adaptor。我们认为这些方法都可以同样的写到 ERM 体系下。
比如微调最简单,其实就是把训练好的模型看做一种初始化(initialization)。
由于公式中没有注明初始化来自于何方,所有这两者看起来是一样的。
Adaptor 其实也好处理,就是插入一部分新的权重,然后只训练这一部分权重。
我们这里主要关注的是自动生成的 prompt,而不是那种手动设计的,这样的话,生成 prompt 的部分可以看做是一个模型,那整个模型合到一起就是一个编码器-解码器的结构。
这样看下来,事情就变得很简单了,在大模型的世界里,想要追求可信的性质,无非就是把曾经的 ERM 里好用的方法再拿来试一下。尤其是那些经典的方法,如果有必要的话,必将占据一席之地。
在我们整理这个 survey 的时候,我们发现了很多的例子,更多的内容可以见我们的 survey,下面这两个是我经常放在相关的 presentation 里的例子,大家可以感受一下,这两个方法放到我们的范式之中之后是多么的规矩。
例子 1 来自于这篇 paper《Adversarial soft prompt tuning for cross-domain sentiment analysis》, 我认为这图,尤其是领域对抗训练足以说明问题了。
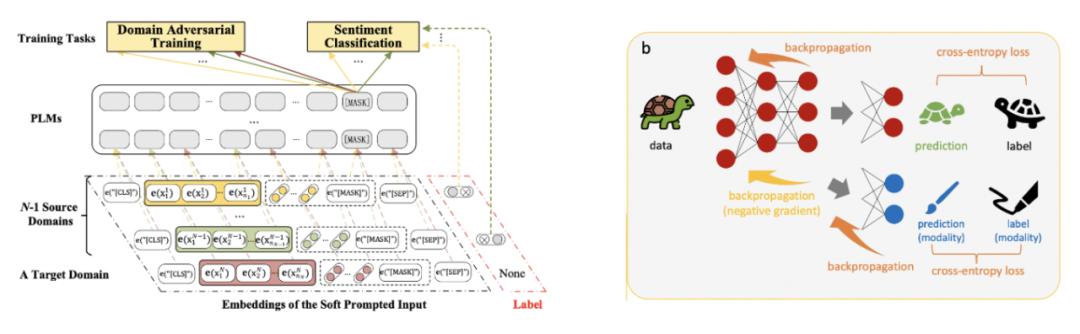 图 6. 左图来自于《Adversarial soft prompt tuning for cross-domain sentiment analysis》,相当于是来在 DANN 范式在大模型下的应用。
图 6. 左图来自于《Adversarial soft prompt tuning for cross-domain sentiment analysis》,相当于是来在 DANN 范式在大模型下的应用。例子 2 来自于这篇 paper《Auto-debias: Debiasing masked language models with automated biased prompts》,其实主要也可以从图上看出来方法的核心在于去找到有偏见的 prompt,进而用某种一致性损失去除他们。
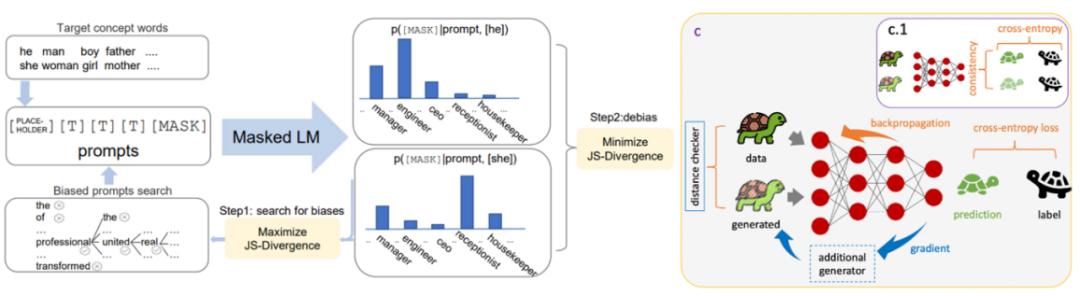 图 7. 左图来自于《Auto-debias: Debiasing masked language models with automated biased prompts》,相当于是数据增强和正则化范式在大模型下的应用。
图 7. 左图来自于《Auto-debias: Debiasing masked language models with automated biased prompts》,相当于是数据增强和正则化范式在大模型下的应用。当然,这两个例子并不是在贬低这两篇 paper,每篇 paper 都有自己的独到之处,需要仔细读才看的出来。这里只是借用这两篇宏观的方法来证实一下这种可信机器学习范式的力量。
4.3 方法的混搭
再从另一个角度出发,其实一个特别有效的思路就是这些方法的混搭。
比如我们这里介绍了三种最核心的范式,然后每个范式下面都有数十种方法。一个很简单的思路就是,不同范式下的不同的方法能否组合在一起呢?
我们在自己提出理论核心的 paper 里【2】做过一点简单的尝试,比如把最简单的 “领域分类器” 和最简单的 “数据增强” 放到一起,提出了一个方法,也提高了一点性能。不过由于这个 paper 的重点是理论的部分,这个方法我们没有太细致的打磨,可能潜力比较小。不过这些也应该证实了一点:两个范式下各自最简单的方法一组合变有效果,那么两个范式下各自更复杂的方法的组合岂不是一定好使?
在另一个我非常喜欢的工作中,我们尝试了把两钟 worst-case 的概念结合起来,一种在特征的维度上去 drop 预测性最强的特征,这其实也就是相当于一种数据增强,另一种是在样本的维度上,其实就是重加权的范式下面。这个结合带来了两个维度下的 worst-case,因此被我命名为 W2D。我认为这个方法及其的自然,精巧,非常好理解,而且效果拔群(具体的可以见下文)。然后这个角度很自然的思路就是,我们其实依然只是用了两个范式里比较简单的方法,重加权的范式里就是最简单的损失转换为权重,增强里面的稍微复杂一点,因为我们直接基于了自己的 RSC 的工作来做的增强。不过这里面的空间依然很大,其实我当时做这个 paper 的一个遗憾就是没有直接用当时效果最好的重加权的方法,这个效果最好的方法也是一个非常小巧和优雅的方法,很契合我们做事的理念。
当然,沿着这两个思路下来,很自然的角度就是各个范式下各种方法的结合,这里就不必赘述了。
4.4 最后,还有新鲜的应用
如果开发新的方法对于某些同学来讲让人头大,那就没必要使劲琢磨了,在新的应用上对这些方法做一些小规模的创新一样能吃饱饭。
这也是另一个我特别喜欢 W2D 方法的理由。经常对那些不太想真正在技术前沿拼杀的同学,我通常建议他们在某些数据集上尝试一下 W2D 方法,通常一次尝试就直接提高 SOTA。目前我们尝试的几个跟 drug 相关的数据集都是这种效果。我认为这个跟两个原因有关。一个是说 W2D 本身的力量几乎全部来自于纯粹的统计,而不是主观的正则化,这大大提高了这个方法的适配度。另一个愿意就是 W2D 对于模型没有任何要求,几乎只要是交叉熵损失(cross-entropy loss)就能用,所以可以直接 plug-in 到几乎任何 SOTA 模型上然后送它们再进一步。
但是我们也在细胞图像分割(cellular image segmentation)上尝试过,结果似乎很挣扎,可能是因为 W2D 毕竟还是比较适合传统一点的交叉熵损失,分割的损失函数不太适配。
另一个我认为特别简单的性能助推器是我们的 AlignReg,一般有高中生找我合作我就会让他们把玩一下这个,几乎也是注定提高性能。然后他们就来跟我说,“原来机器学习这么简单”,那是因为你不知道我当时花了多久才把事情简化到这种程度。
当然,以上只是两个例子,方法五花八门,应用更是千姿百态,随便组合也许就是新的机会。但是其实方法和问题适配非常的重要,随便拼凑着试恐怕不行。比如上面两个例子,W2D 的那些应用上的成绩都是因为数据本身也是一个跨领域的问题,无论是领域自适应还是领域泛化,还是什么新的 setting。AlignReg 那个例子也是,方法虽然简单,但是确定方法和问题是一致的一般不是那些高中生能自己做到的。
IV. 最后一部分
写到这里,我希望我兑现了这 1000 个创新点的承诺,如果你一路读下来,每句话都有道理,你恐怕会感受到其实远远不止 1000 个。如果你没有这种感觉,也建议去看看我们完整的 survey,那里的内容要丰富的多。
顺便也借此回答一下有些朋友可能有的问题:“你这样把 idea 写出来你自己的 paper 不就少了吗?” 按我现在的浅见,重要的从来不是 paper 数量,而是这些 paper 后面承载的内力,没有这种修养,paper 再多不过是些花拳绣腿,一碰就散架。不过我现在还太年轻,这些理解未来也许会随着年龄的增长而改变。
最后的最后,既然写了这么长,顺便介绍一下自己。
我现在在伊利诺伊大学厄巴纳-香槟分校(UIUC)的信息科学学院当助理教授,主要研究可信机器学习(trustworthy machine learning)和计算生物学(computational biology)。目前将 lab 命名为 DREAM (Developing Reliable and Efficient Algorithms for Medicine)。我的 lab 刚刚建立一年多,非常需要各种志同道合的小伙伴,欢迎大家来和我一起玩,无论是正式的申请,还是作为 intern 或 visiting scholar。今年的 phd 申请,我要尽量在自己的 intern 中录取。我个人非常非常非常喜欢和优秀的人一起玩,因为我认为这是一个互相进步的过程。而且这种优秀其实不局限于简历上的优秀,更多是修养和追求上的优秀。
提到的论文:
[1].Liu, H., Chaudhary, M. and Wang, H., 2023. Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives. arXiv preprint arXiv:2307.16851.
[2].Wang, H., Huang, Z., Zhang, H., Lee, Y.J. and Xing, E.P., 2022, August. Toward learning human-aligned cross-domain robust models by countering misaligned features. In Uncertainty in Artificial Intelligence (pp. 2075-2084). PMLR.
[3].Wang, H., Wu, X., Huang, Z. and Xing, E.P., 2020. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8684-8694).
[4].Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., Marchand, M. and Lempitsky, V., 2016. Domain-adversarial training of neural networks. The journal of machine learning research, 17 (1), pp.2096-2030.
[5].Madry, A., Makelov, A., Schmidt, L., Tsipras, D. and Vladu, A., 2017. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083.
[6].Huang, Z., Wang, H., Xing, E.P. and Huang, D., 2020. Self-challenging improves cross-domain generalization. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16 (pp. 124-140). Springer International Publishing.
[7].Wang, H., Huang, Z., Wu, X. and Xing, E., 2022, August. Toward learning robust and invariant representations with alignment regularization and data augmentation. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp. 1846-1856).
[8].Huang, Z., Wang, H., Huang, D., Lee, Y.J. and Xing, E.P., 2022. The two dimensions of worst-case training and their integrated effect for out-of-domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9631-9641).© THE END
原标题:《研究没思路的看过来,这是可信机器学习的1000个创新idea》