真正让ChatGPT发挥作用的是什么
人类语言,及其生成所涉及的思维过程,一直被视为复杂性的巅峰。人类大脑“仅”有约1000亿个神经元(及约100万亿个连接),却能够做到这一切,确实令人惊叹。人们可能会认为,大脑中不只有神经元网络,还有某种具有尚未发现的物理特性的新层。但是有了ChatGPT之后,我们得到了一条重要的新信息:一个连接数与大脑神经元数量相当的纯粹的人工神经网络,就能够出色地生成人类语言。

这仍然是一个庞大而复杂的系统,其中的神经网络权重几乎与当前世界上可用文本中的词一样多。但在某种程度上,似乎仍然很难相信语言的所有丰富性和它能谈论的事物都可以被封装在这样一个有限的系统中。这里面的部分原理无疑反映了一个普遍现象(这个现象最早在规则30[1]的例子中变得显而易见):即使基础规则很简单,计算过程也可以极大地放大系统的表面复杂性。但是,正如上面讨论的那样,ChatGPT使用的这种神经网络实际上往往是特别构建的,以限制这种现象(以及与之相关的计算不可约性)的影响,从而使它们更易于训练。
那么,ChatGPT是如何在语言方面获得如此巨大成功的呢?我认为基本答案是,语言在根本上比它看起来更简单。这意味着,即使是具有简单的神经网络结构的ChatGPT,也能够成功地捕捉人类语言的“本质”和背后的思维方式。此外,在训练过程中,ChatGPT 已经通过某种方式“隐含地发现”了使这一切成为可能的语言(和思维)规律。
我认为,ChatGPT的成功为一个基础而重要的科学事实向我们提供了证据:它表明我们仍然可以期待能够发现重大的新“语言法则”,实际上是“思维法则”。在ChatGPT中,由于它是一个神经网络,这些法则最多只是隐含的。但是,如果我们能够通过某种方式使这些法则变得明确,那么就有可能以更直接、更高效和更透明的方式做出ChatGPT所做的那些事情。
这些法则可能是什么样子的呢?最终,它们必须为我们提供某种关于如何组织语言及其表达方式的指导。我们稍后将讨论“在ChatGPT内部”可能如何找到一些线索,并根据构建计算语言的经验探索前进的道路。但首先,让我们讨论两个早已知晓的“语言法则”的例子,以及它们与ChatGPT的运作有何关系。
第一个是语言的语法。语言不仅仅是把一些词随机拼凑在一起。相反,不同类型的词之间有相当明确的语法规则。例如,在英语中,名词的前面可以有形容词、后面可以有动词,但是两个名词通常不能挨在一起。这样的语法结构可以通过一组规则来(至少大致地)捕捉,这些规则定义了如何组织所谓的“解析树”。
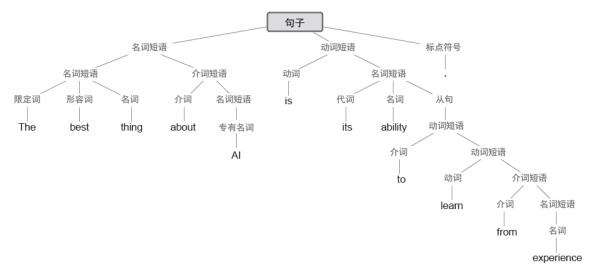
ChatGPT并不明确地“了解”这些规则。但在训练过程中,它隐含地发现了这些规则,并且似乎擅长遵守它们。这里的原理是什么呢?在“宏观”上还不清楚。但是为了获得一些见解,也许可以看看一个更简单的例子。
考虑一种由“(”和“)”的序列组成的“语言”,其语法规定括号应始终保持平衡,就像下面的解析树一样。
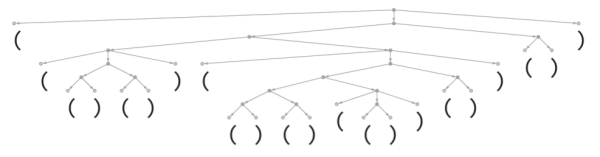
我们能训练神经网络来生成“语法正确”的括号序列吗?在神经网络中,有各种处理序列的方法,但是这里像ChatGPT一样使用Transformer网络。给定一个简单的Transformer网络,我们可以首先向它馈送语法正确的括号序列作为训练样例。一个微妙之处(实际上也出现在ChatGPT的人类语言生成中)是,除了我们的“内容标记”[这里是“(”和“)”]之外,还必须包括一个“End”标记,表示输出不应继续下去了(即对于ChatGPT来说,已经到达了“故事的结尾”)。
如果只使用一个有8个头的注意力块和长度为128的特征向量来设置Transformer网络(ChatGPT也使用长度为128的特征向量,但有96个注意力块,每个块有96个头),似乎不可能让它学会括号语言。但是使用2个注意力块,学习过程似乎会收敛——至少在给出1000万个样例之后(并且,与Transformer网络一样,展示更多的样例似乎只会降低其性能)。
通过这个网络,我们可以做类似于ChatGPT所做的事情,询问括号序列中下一个符号是什么的概率。
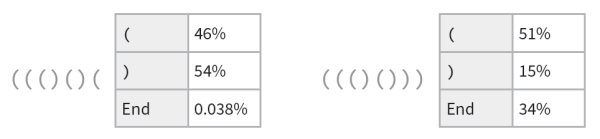
在第一种情况下,网络“非常确定”序列不能在此结束——这很好,因为如果在此结束,括号将不平衡。在第二种情况下,网络“正确地识别出”序列可以在此结束,尽管它也“指出”可以“重新开始”:下一个标记是“(”,后面可能紧接着一个“)”。但糟糕的是,即使有大约400000个经过繁重训练的权重,它仍然说下一个标记是“)”的概率是15%——这是不正确的,因为这必然会导致括号不平衡。
如果要求网络以最高概率补全逐渐变长的“(”序列,结果将如下所示。

在一定长度内,网络是可以正常工作的。但是一旦超出这个长度,它就开始出错。这是在神经网络(或广义的机器学习)等“精确”情况下经常出现的典型问题。对于人类“一眼就能解决”的问题,神经网络也可以解决。但对于需要执行“更算法式”操作的问题(例如明确计算括号是否闭合),神经网络往往会“计算过浅”,难以可靠地解决。顺便说一句,即使是当前完整的ChatGPT在长序列中也很难正确地匹配括号。
对于像ChatGPT这样的程序和英语等语言的语法来说,这意味着什么呢?括号语言是“严谨”的,而且是“算法式”的。而在英语中,根据局部选词和其他提示“猜测”语法上合适的内容更为现实。是的,神经网络在这方面做得要好得多——尽管它可能会错过某些“形式上正确”的情况,但这也是人类可能会错过的。重点是,语言存在整体的句法结构,而且它蕴含着规律性。从某种意义上说,这限制了神经网络需要学习的内容“多少”。一个关键的“类自然科学”观察结果是,神经网络的Transformer架构,就像ChatGPT中的这个,好像成功地学会了似乎在所有人类语言中都存在(至少在某种程度上是近似的)的嵌套树状的句法结构。
语法为语言提供了一种约束,但显然还有更多限制。像“Inquisitive electrons eat blue theories for fish”(好奇的电子为了鱼吃蓝色的理论)这样的句子虽然在语法上是正确的,但不是人们通常会说的话。ChatGPT即使生成了它,也不会被认为是成功的——因为用其中的词的正常含义解读的话,它基本上是毫无意义的。
有没有一种通用的方法来判断一个句子是否有意义呢?这方面没有传统的总体理论。但是可以认为,在用来自互联网等处的数十亿个(应该有意义的)句子对ChatGPT进行训练后,它已经隐含地“发展出”了一个这样的“理论”。
这个理论会是什么样的呢?它的冰山一角基本上已经为人所知了2000多年,那就是逻辑。在亚里士多德发现的三段论(syllogistic)形式中,逻辑基本上用来说明遵循一定模式的句子是合理的,而其他句子则不合理。例如,说“所有X都是Y。这不是Y,所以它不是X”(比如“所有的鱼都是蓝色的。这不是蓝色的,所以它不是鱼”)是合理的。就像可以异想天开地想象亚里士多德是通过(“机器学习式”地)研究大量修辞学例子来发现三段论逻辑一样,也可以想象ChatGPT在训练中通过查看来自互联网等的大量文本能够“发现三段论逻辑”。(虽然可以预期ChatGPT会基于三段论逻辑等产生包含“正确推理”的文本,但是当涉及更复杂的形式逻辑时,情况就完全不同了。我认为可以预期它在这里失败,原因与它在括号匹配上失败的原因相同。)
除了逻辑的例子之外,关于如何系统地构建(或识别)有合理意义的文本,还有什么其他可说的吗?有,比如像Mad Libs®这样使用非常具体的“短语模板”的东西。但是,ChatGPT似乎有一种更一般的方法来做到这一点。也许除了“当你拥有1750亿个神经网络权重时就会这样”,就没有什么别的可以说了。但是我强烈怀疑有一个更简单、更有力的故事。
注释
1.规则30是一个由本书作者在1983年提出的单维二进制元胞自动机规则。这个简单、已知的规则能够产生复杂且看上去随机的模式。——编者注
本文摘自《这就是ChatGPT》,澎湃新闻经出版方授权刊载。

《这就是ChatGPT》,【美】斯蒂芬·沃尔弗拉姆/著 WOLFRAM传媒汉化小组/译,人民邮电出版社,2023年7月版