“GPT-N”一定更强吗?专家警告:当人类数据用完,AI大模型或将越来越笨

原创 学术头条 学
1966年,在由Michael Keaton主演的科幻喜剧电影《丈夫一箩筐》(Multiplicity)中,剧中主角 Doug Kinney 在 Leeds 博士的帮助下成功克隆了自己,随后又制作了“克隆人的克隆人”,其结果是,后代克隆人的智力水平均呈现出了指数级下降,愚蠢程度不断增加。

图|《丈夫一箩筐》海报
放眼当下,以 ChatGPT 为代表的大型语言模型(LLMs),在一定程度上也成为了人类智力的克隆产物。而数据作为模型性能和泛化能力的重要基础之一,会直接影响这些“克隆人”的智能水平。
如我们所知,用于训练 LLMs 和其他支撑 ChatGPT、Stable Diffusion 和 Midjourney 等产品的 Transformer 模型的数据,最初都来自于人类的资源,如书籍、文章、照片等。而这些都是在没有人工智能(AI)帮助的情况下创造出来的。
未来,随着 AI 生成的数据越来越多,大模型训练又将如何展开?当 AI 只能用自己生成的数据来训练自己时,又会怎样?
近日,牛津大学、剑桥大学的研究人员及其合作者对这一问题进行了研究,并将研究成果论文发表在了预印本网站 arXiv 上。

论文链接:https://arxiv.org/abs/2305.17493v2
他们通过研究文本到文本和图像到图像 AI 生成模型的概率分布,得出了这样一个结论:
“模型在训练中使用(其他)模型生成的内容,会出现不可逆转的缺陷。”
即“模型崩溃”(Model Collapse)。
什么是模型崩溃?
本质上,当 AI 大模型生成的数据最终污染了后续模型的训练集时,就会发生“模型崩溃”。
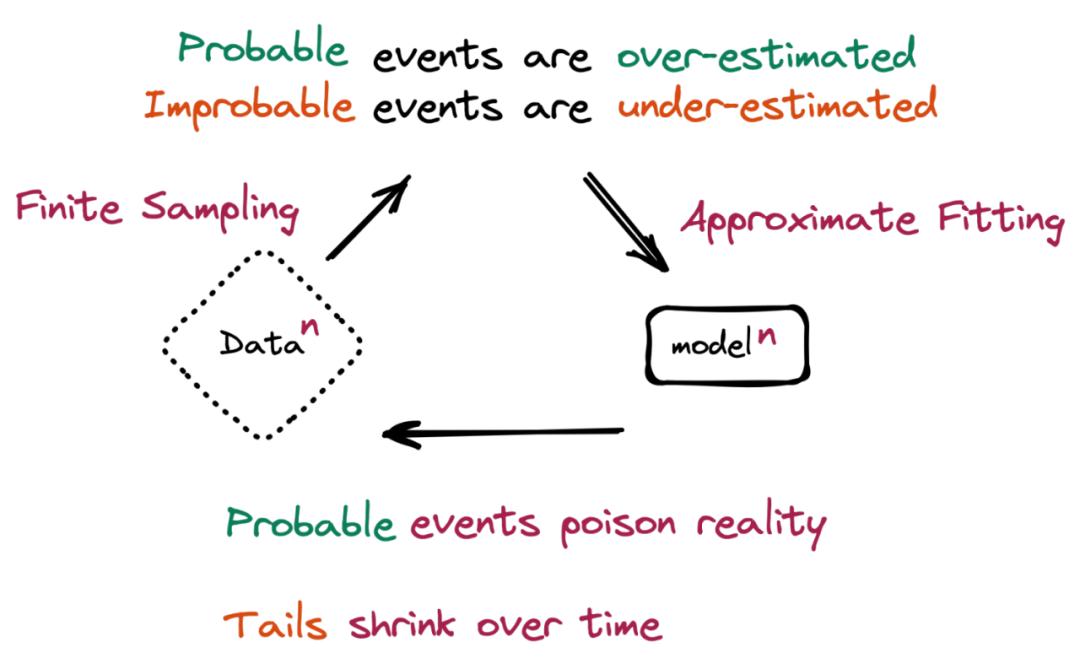
论文中写道,“模型崩溃指的是一个退化的学习过程,在这个过程中,随着时间的推移,模型开始遗忘不可能发生的事件,因为模型被它自己对现实的投射所毒化。”
一个假设的场景更有助于理解这一问题。机器学习(ML)模型在包含 100 只猫的图片的数据集上进行训练——其中 10 只猫的毛色为蓝色,90 只猫的毛色为黄色。该模型了解到黄猫更普遍,但也表示蓝猫比实际情况偏黄一点,当被要求生成新数据时,会返回一些代表“绿毛色的猫”的结果。随着时间的推移,蓝色毛色的初始特征会在连续的训练周期中逐渐消失,从逐渐变成绿色,最后变成黄色。这种渐进的扭曲和少数数据特征的最终丢失,就是“模型崩溃”。

论文中还强调,还有许多其他方面会导致更严重的影响,比如基于性别、种族或其他敏感属性的歧视,特别是如果生成式 AI 随着时间的推移学会在其反应中产生一个种族,而“忘记”他人的存在。
重要的是要注意,这种现象不同于“灾难性遗忘”(catastrophic forgetting),模型只是丢失以前学到的信息,相比之下,“模型崩溃”涉及模型根据它们强化的信念误解现实。
此外,研究人员表示,即使在训练后代模型时使用的人类自身创作数据占比依然有 10%,“模型崩溃也还会发生,只是不会那么快。”
可以避免吗?
幸运的是,有一些方法可以避免模型崩溃,即使是对于当前的 Transformers 和 LLMs 而言。
在论文中,为避免响应质量下降,并减少 AI 模型中不需要的错误或重复,研究人员给出了两种具体方式。
第一种方法是,保留原始的完全或名义上由人类生成的数据集的副本,并避免与 AI 生成的数据相混淆。然后,模型可以根据这些数据定期重新训练,或者从头开始进行一次“完全刷新”。
第二种方法,将新的、清洗过的、人类生成的数据集重新引入到模型训练中。
然而,正如研究人员指出的那样,这需要内容制作者或 AI 公司采用某种大规模的标签机制,或由内容生产商、AI 公司使用更好的方法来区分 AI 和人类生成的内容。“这会增加训练成本,但至少在某种程度上会帮助你抵消模型崩溃。”
另外,研究人员也给出了提示:“为了阻止模型崩溃,我们需要确保原始数据中的少数群体在后续数据集中得到公平的代表。”
但在实践中,这是十分困难的。例如,数据需要被仔细备份,并涵盖所有可能的少数情况。在评估模型的性能时,应该使用模型预期要处理的数据,即使是那些最不可能的数据案例。(请注意,这并不意味着应该对不可能的数据进行过采样,而是应该适当地表示它们。)
未来,人类创造的内容将更有价值?
尽管这一警示似乎对当前的生成式 AI 技术以及寻求通过它获利的公司来说都是令人担忧的,但是从中长期来看,或许能让人类内容创作者看到更多希望。
研究人员表示,在充满 AI 工具及其生成内容的未来世界,人类创造的内容将比今天更有价值——如果只是作为人工智能原始训练数据的来源。

这一发现,对 AI 领域有着重要的意义。研究人员强调,我们通过改进方法来保持生成模型的完整性,以及未经检查的生成过程的风险,并可能指导未来的研究,防止或管理模型崩溃。
“很明显,模型崩溃是 ML 的一个问题,必须采取一些措施来确保生成式 AI 继续得到改进。”
参考链接:
https://arxiv.org/abs/2305.17493v2
https://venturebeat.com/ai/the-ai-feedback-loop-researchers-warn-of-model-collapse-as-ai-trains-on-ai-generated-content/
原标题:《“GPT-N”一定更强吗?专家警告:当人类数据用完,AI大模型或将越来越笨》