拐点将至:生成式人工智能带来营销技术化的一次飞跃
·对营销业来说,生成式人工智能带来的最大问题是批量生产不精确内容,从而影响信息的媒体属性。而从创意和策略的供给来说,这反倒是个福音。
·媒体和营销策略均面临分化。用户的媒体使用策略将被重塑;数据集的拥有者和生成式人工智能模型拥有者之间的博弈开始复杂化;搜索逻辑的风险首当其冲;小公司将有望抢得先机,大公司有点尾大不掉。
今年2月,微软宣布ChatGPT接入必应(Bing),同时CEO萨提亚·纳德拉(Satya Nadella)抛下一句话:“搜索引擎迎来了新时代!”时至今日,微软的市值还在因此上涨,累计涨幅已经超过27%[1]。5月11日,谷歌宣布将聊天机器人引入搜索引擎,正面迎战微软的挑战。
产生这种对抗局面的原因当然是生成式人工智能(Generative AI)已经在短期内对传统搜索的市场格局产生了实质影响。路透社的数据表明:在宣布接入AI的两周内,必应的PV(页面浏览量)增长了15.8%,而谷歌搜索引擎的PV下降约1%[2]。
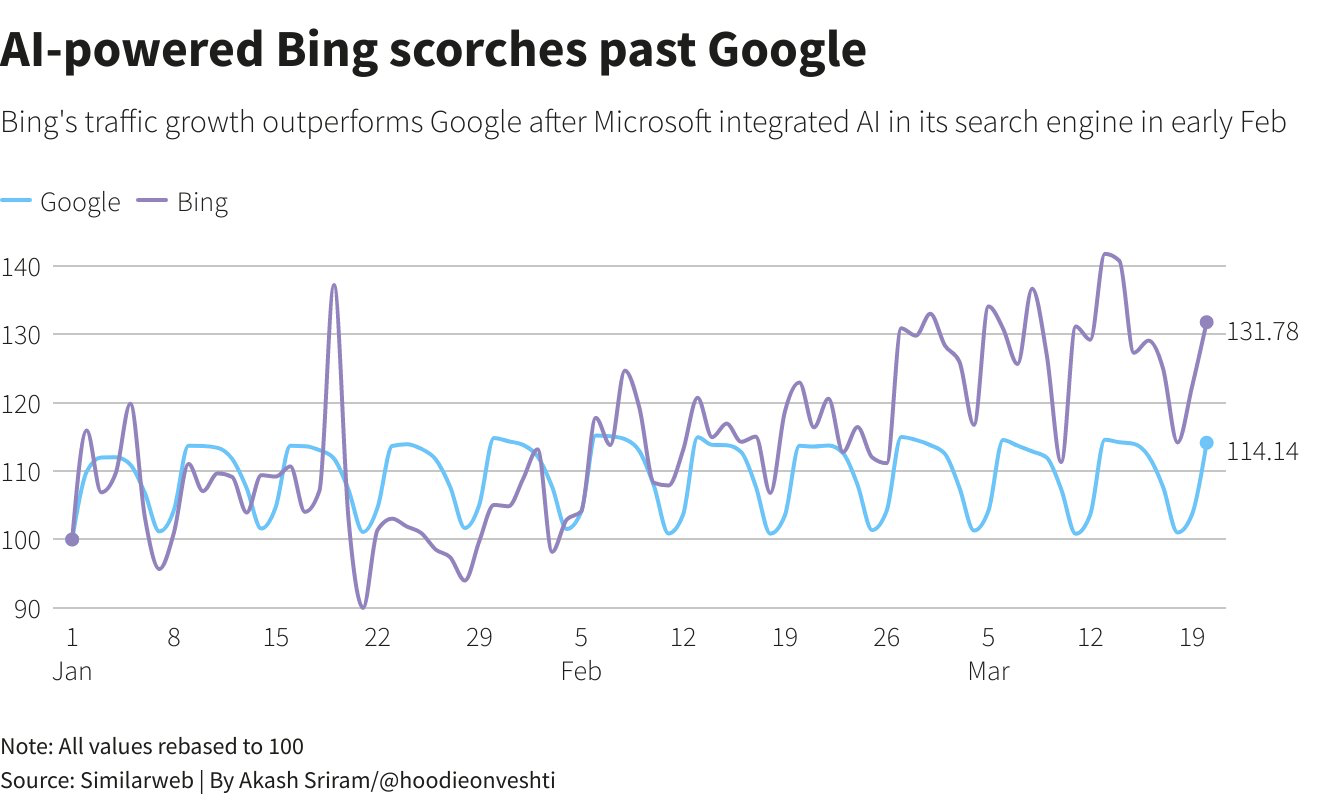
在2月9日微软宣布必应(紫线)接入ChatGPT后日活度(指数,基线均为100)明显超越谷歌搜索(蓝线)。[3]
但事实上,谷歌搜索的隐忧并不完全来自于同行内卷。Alphabet公司公布的2022年年报显示,谷歌的核心广告业务同比下降0.2%,到4月公布的2023年一季度季报仍未止住下滑势头;与此同时,在中国,百度的广告收入在所有媒体类型中的占比在过去5年中跌了40%。其背后原因是,传统的搜索体验越来越不吸引用户了。eMarketer最近预测:自2023年起全球搜索广告的增长贡献将不再来自于传统搜索引擎,而是来自于更靠近售卖端的零售媒体搜索。
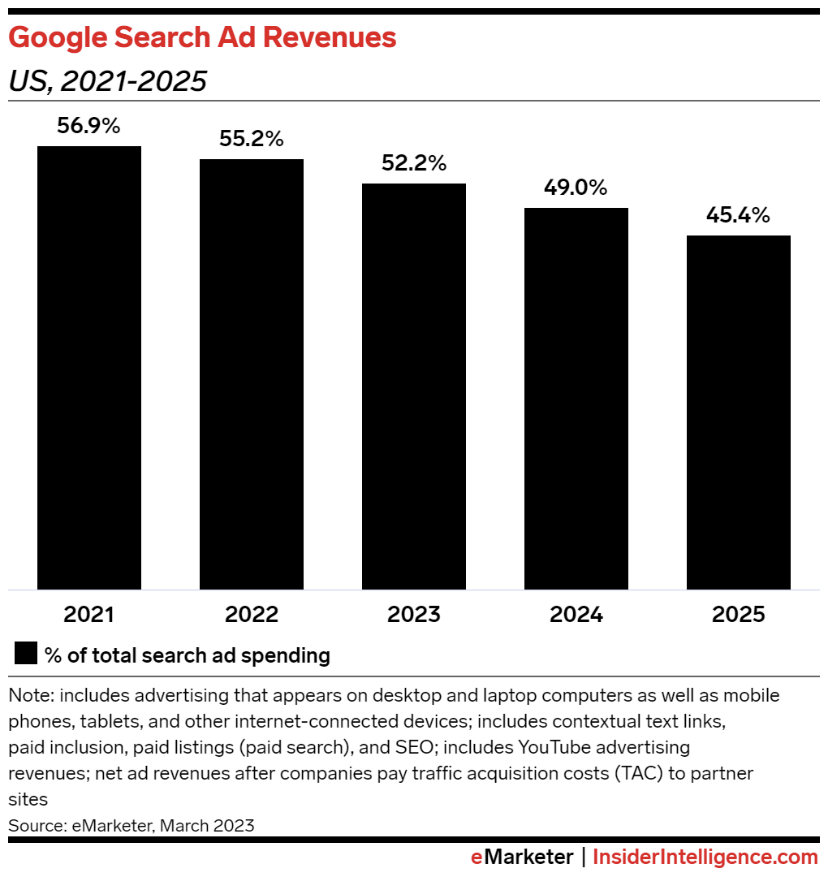
eMarketer预测以传统搜索引擎为核心的谷歌在全球搜索广告整体大盘中占比将逐年下降。
传统搜索引擎是否能藉由生成式人工智能而重拾用户的青睐呢?谷歌在互联网广告界的霸主地位会被改写吗?更重要的是,假如真像纳德拉所说,生成式人工智能将重塑所有软件,变革会冲击整个媒体行业和数字营销业的根基吗?ChatGPT面市半年后的今天,有一些迹象已经十分明朗——信息内容与受众之间的关系正在面临重构。
正在寻求内容可信代理人的消费者
不要以为一浪高过一浪的讨论、快速过亿的用户规模展现的是人类对于生成式人工智能的拥抱。恰恰相反,社会主流对它的态度是警惕而审视的。澎湃新闻曾报道美国新闻可信度评估与研究机构NewsGuard对ChatGPT的测试结果——“这是一个充斥着阴谋论和误导性叙述的平台”,在GPT-4上市后他们又测了一次,这回它因假消息喂养而炮制误导性信息的概率甚至上升了20个百分点。而著名科技新闻网站CNET被爆使用AIGC(人工智能生成内容)发布了数十篇文章,引起广泛恐慌:全球读者在了解到文章是由ChatGPT撰写的之后,声称不会再相信这些文章是由人类制作的了,他们痛斥这些文章错误百出并且抄袭严重,CNET最终对一半以上由AI生成的已发表文章进行了更正。
而民意调查结果也直指这一点:根据益普索(Ipsos)的调查,56%的美国成年人赞同“AI生成的写作内容存在偏差或不准确”,这个比例大大高于不赞同的人(20%);中国网友的态度虽然尚未有市场调研数据做注脚,但全网围观Midjourney(AI绘画工具)绘制名人假新闻图片和假情侣照的劲头说明了大家的站位。
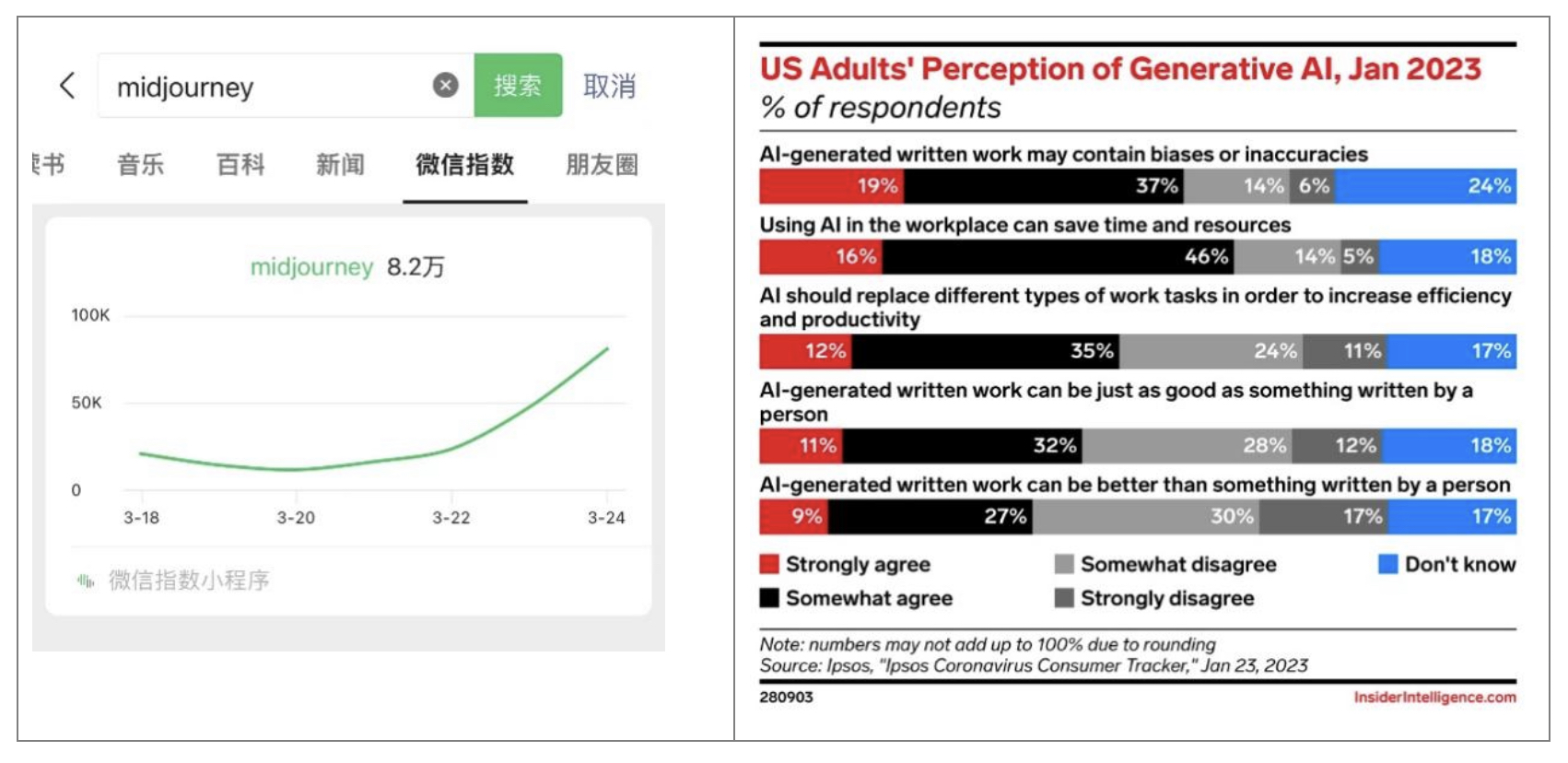
左图:3月21日Midjourney公布爆火情侣照片前后的微信热度指数曲线。右图:2023年1月cc美国成年人对生成式人工智能的看法。
很难实现C端商业化
这一切对AIGC来说算不上好消息,没有明确的预期,消费者就不会把它作为一种价值增量,因而也就很难实现C端商业化。
如果回顾AI发展史,我们会发现它其实很早就存在于我们身边,只不过消费者并没有对它另眼相待。还记得2017年,腾讯高调公开了Dreamwriter,它在1秒钟内就将台上主讲人长达十几分钟的演讲写成新闻稿,开创了写稿机器人“抢占”人类工分的历史,并在2019年达到其“职业”高峰——全年写稿50多万篇,涉及各个领域,然后快速地在一年后被关停。究其原因,其一是“内容太少引发互动而很难进入推荐池”,其二是“洗稿、编造”。前者只能说明用户体验不佳,后者则在用户不信任的基础上还可能带来法律风险。

2017年11月,腾讯在会场现场演示Dreamwriter一秒钟完成写稿。
所以,即使ChatGPT已经部分解决了用户互动体验问题,但还是在一些需要信息可信度支持的营销场景上折戟,例如搜索。谷歌、亚马逊、Meta等公司都已经决定,在解决用户信任和法律风险前要谨慎使用它。
在能提供内容可信认证之前,消费者应该会十分谨慎地采用生成式人工智能产品。但谁有能力提供内容可信认证?认证的过程是否有悖于互联网开放的基本架构,目前尚不得而知。
B端:对自动化的促进还是遏制?
生成式人工智能首先是蚕食流量的可信度,其实才是影响营销行为本身。任何革新性的信息技术都有工具属性和媒体属性两部分。对营销业来说,它带来的最大问题是批量生产不精确内容,从而影响信息的媒体属性。这种“不精确”不一定是“假(根本不存在)”或者“伪(移植或套用真相的主体)”,而是“达不到可确信的程度”。举例来说:对特征的描述之宽泛——例如我们最近越来越能从某个国产交互机器人身上感受到的“打官腔”,或者内容分类边界的模糊——例如诱导性商业信息与硬资讯之间的分界。这些都会引起用户不信任,而对整个媒介环境产生质疑。如果连营销的“宿主”都不牢靠的话,那么用户将更难受建筑其上的劝服行为影响。从这一点上看,UGC(用户生产内容)容易成为重灾区,但事实上OGC(职业生产内容)和PGC(专业生产内容)也不能幸免。上文提到过的CNET的母公司Red Ventures,为了保证替广告主导流的机制不被谷歌AI切断,竟然任由“什么是信用卡?”之类的劣质AIGC充斥于自家平台,并被各平台的内容抓取机制分发到全网。
这一问题的根本解决办法目前仍然是在AIGC后方加一层人工校验,或者提供内容溯源算法——如果营销甲方坚持要求内容安全的话。但谁应该为“内容安全”环节买单?国内品牌方极少设置CIO(首席信息官)之类的职位,信息安全和内容安全也较少进入CMO(首席营销官)的工作范畴。
而从创意和策略的供给来说,这反倒是个福音。营销作业链存在“策略-创意-交付”分工,其中“策略-创意”两环节的割裂眼下被生成式人工智能打破了,平台大规模地取代中间代理,品牌完全可以直接使用平台提供的工具来完成营销campaign(活动)和线上内容的输出;生成式人工智能虽然不能提供可信内容,但可以提供“脚手架”或者“发射器”。
我们看到Adobe就是这么干的。3月23日,Adobe Firefly被推出。值得一提的是,它从里到外透露出一种“俯首甘为小助手”的气息。首先,它被包含在企业用户专用的Adobe Experience Cloud的生成式人工智能方案——Sensei GenAI中推出,尚未向个人用户开放;其次,Adobe公开强调这款产品将专注于商业用途。此次推出的功能有两种,一种是利用文字生成图像,另一种是字体效果编辑。在这两种功能中,Adobe强调了它是“无原罪人工智能”,即由Firefly模型创建的作品将包含元数据,以证明它是部分或全部由人工智能生成的,而这样做的原因主要是为了维护艺术家的版权问题。
这背后是Adobe对AIGC的高度警觉,为此CEO尚塔努·纳拉扬(Shantanu Narayen)甚至专门上过《福布斯》专访。2019年,Adobe曾发起了有700家设计公司参与的“内容真实计划”(Content Authenticity Initiative[4]),通过全球性活动来推动对“数字内容源头”进行确认。通过该计划,内容的设计者和消费者可以选择创建并跟踪一个数字线索,以此来显示谁将对给定的视频或图像负责,包括他们对内容做出的任何更改,原因就在于Adobe大概是最早领受Deepfake(深度造假)问题的数字公司。
不过这也深刻反映出:从专业内容生产商的作业流程来说,生成式人工智能带来的生产率提升不容小觑。
在无内容追溯保障下的AI技术应用平台当前如履薄冰。中国国内智能化厂商,例如腾讯的腾讯云智媒体AI中台、百度开放平台旗下的AI媒体·策采编审、讯飞开放平台旗下的A.I.智慧媒体解决方案和亚马逊AWS带入中国的AI云服务-社交媒体行业解决方案,以及我国国家级的AI媒体平台——新华智云智媒体融合平台,均强调多模态内容分析、内容个性化、智能审核、智能直播等编辑运营功能,而没有突出内容生成技术。
新华智云的“智媒体融合平台”基于媒体大脑30余款机器人,为内容工作者提供“策、采、编、发、审”全流程产品。
而国外的媒体探索好像已经有了一些进展。BBC新闻实验室、BuzzFeed等大型媒体机构均开始尝试与GPT等模型合作,进行生成式AI应用探索。值得一提的是,BBC的半自动化工具取得了AI效率和可信度之间的可喜平衡,在一款数据可视化工具中,可以实现句子分析以对文本中的数字、比例进行可视化显示,允许记者干预编辑界面、审核自动生成的初稿,并从该工具提供的变体中进行选择,最后生成手机大小的文本块屏幕图像。这些“豆腐块”被投入到BBC的Facebook账户内容中,年轻用户们对此颇为欣赏,有86%的被调查者表示愿意将其与朋友分享。

BBC半自动化AI可视化工具产出的图片。
拐点到来,媒体和营销策略均面临分化
一旦用户和信息内容之间的关系达成某种新的平衡,某些媒体或者营销手段就会被分化。首先是用户的媒体使用策略将被重塑。用户是不在会把鸡蛋放在同一个篮子里的。同类型媒体的使用,可能一家变多家,从而互相佐证;各个细分赛道中的垄断格局可能会被打破。这也就是为什么百度会这么着急推出自己的生成式人工智能的原因。
其次,数据集的拥有者和生成式人工智能模型拥有者之间的博弈开始复杂化。说来可笑,新闻机构竟然有一天可能成为AI发展的拦路虎。新闻集团已经开始和OpenAI讨论补偿条款,原因就是他们发现ChatGPT在其应答中会使用《华尔街日报》的内容。
搜索逻辑的风险首当其冲。由于生成式人工智能为内容发布者建立了全新的用户通路,搜索广告经济将被重塑。生成式人工智能队列响应、输出结果可能会打乱谷歌的市场。当前谷歌在全球数字广告业中一枝独秀:2023年实现全美广告营收738亿美元,甩开第二名Meta 224.6亿美元之巨;而在搜索领域里更是无出其右,2022年全美搜索广告收入580亿美元,是第二名亚马逊的2.4倍。而百度在中国整体广告市场的占比也达到将近10%。这背后还有基于关键词捕捉的媒体形态:包括摘要、合成、看板类媒体可能会式微,人机交互会以更多媒体、互动性更强的形态出现。更新的交互形式对用户具有巨大的吸引力。
小公司将有望抢得先机,大公司有点尾大不掉。初创企业Bestever之类的公司已经开始使用生成式人工智能来成规模地创制广告。结合兴趣电商和正兴起的零售媒体广告(Retail Media Ad)趋势,凭借“无内容不可广告”的一秒生成按钮,这家2021年才成立的10人企业已经赢得了包括Chewma、Neuro等品牌的青睐。而大企业就要考虑AI和原有人力如何融合的问题。更多的新生营销公司正在来的路上。
营销技术化的一次飞跃
2015年左右,当MarTech(营销技术)概念出现时,业界更多关注它的预测性,而没有人看好互动性会是下一个方向。这也难怪Morning Consult的调查显示,52%的消费者认为AI会无处不在,但仅有少数商家展现出了他们对于AI应用的理解。
对用户的行为意图作出判断、从而使得主动提供的内容更可能被选择,这是过去10年中大部分媒体或者电商提供给营销业者的一种道路,但值得注意的是,这种策略是一种“一过性诱导”;而与用户的生成式人工智能式交互,则为持续性地诱导与理解提供了空间。很多东西,让用户自己说出来,比猜测要来得更准确、转化链条也更靠后端。
某些技术和职能将被内化。AI承担了部分运营的功能,例如A/B TEST——生成式人工智能通过无限降低内容成本来真正意义上实现了“一对一运营”,所以,从概率或者分布角度出发的统计式运营被取代了。这些操作,未来将从专门的营销步骤中跳过。Convert、Virtuoso等全AI或半人工的测试平台早就已经开始接管这些步骤。
营销业者需要重新盘点有哪些数据资产和组织支援可供训练AI。组织要梳理一下有没有现成的数据、标签、信息资产来作为数据集应用,并且必须是清洗过的、可信的数据;以及密切关注自身的客户资源、数据与哪个媒体平台的模型最为适配。
所有的学习过程都是一条曲线
虽然AI看上去刚刚降临我们的生活,而事实上它已经在营销领域里存在好几年了,有品牌抱怨它其实并未产生预期中的行业影响——根据Source LXT的调查,41%的AI项目未能达到原定的训练目标,因而也就没有合适的AI训练数据可供组织使用。但这只能说明你该尽早启动。
[1]根据微软2023年2月7日及6月2日收盘价,纳斯达克
[2]路透社,2023年3月23日,https://www.reuters.com/technology/openai-tech-gives-microsofts-bing-boost-search-battle-with-google-2023-03-22/
[3]SimilarWeb, 20230323, https://www.similarweb.com/website/google.com/#overview
[4]https://36kr.com/p/1807317271767557
(作者邓丽,系前国内权威媒体资深记者、现品牌营销公司上海扶乐荷文化传播创始人,她还曾获得英国《卫报》中国最佳环境报道奖。曹维斯,系复旦大学社会学硕士、卫士通(上海)网络安全技术有限公司市场总监。)
