未来城市思辨|大型语言模型,规模就是一切吗?
语言模型的产生
近日举办的神经信息处理系统大会(NeurIPS 2022)上,来自DeepMind的研究人员发表了一个人工智能模型,用以从持不同观点的参与者所给出的表述中,形成一个较有可能达成的共识。研究者声称,通过这一模型生成出的文本表述,较人工所作的总结更受参与者青睐。
相比之下,更多的将多样自然文本建模成计算机能理解并可计算的方案——一般被称为语言模型——已经进入到人们的日常生活中。从手机上各种“智能助手”看似简单的口令,到客服机器人,乃至于各种“AI绘画”中输入的提示词,都需要经过复杂程度不同的语言模型处理。

2022年10月,上海。澎湃新闻记者 周平浪 图
对语言模型的追寻,可上溯到上世纪中叶。1947年3月4日,数学家沃伦·韦弗(Warren Weaver)写信给维纳(Nobert Wiener):“我想知道,设计一台可以翻译的计算机是否是不可想象的。即使它只能翻译科学材料(显著降低语义困难),即使它会产生不优雅的结果,但对我来说,只要尚可理解,就值得尝试。”“翻译问题是否可以想象为密码学中的一个问题?……你想过这个问题吗?作为一名语言学家和计算机专家,你认为这值得思考吗?”
维纳在同年4月30日作出的答复中并不看好机械翻译。在他看来,谈论机械翻译为时尚早——不仅“不同语言中的词汇界限太模糊,情感和国际内涵太广泛”,而且即便是“基本英语”(Basic)这样从日常英语中有所筛选、人为设计的“机械化语言”,也很难摆脱复杂的语义负担,从而使之能够机械性地转换为另一种语言。
不过,韦弗似乎并没有来得及等到维纳迟来的回复。在寄出致维纳的信件后不过两天,他就从英国的计算机技术先驱者布斯(Andrew Booth)那里了解到美国计算机发展的情况,认定将计算机用于非数字运算的应用,将更容易获得资金支持,并将机器翻译列为一个可选方向。至于维纳所提到的语义负担,他认为,可以将相邻单词视作一个词来加以解决。
韦弗的提议在香农(Claude Shannon)撰写的《通信的数学理论》(A Mathematical Theory of Communication)一文中被推广为考察多个相邻词的N元组(N-gram),在此基础上,香农还讨论了将马尔科夫链(Markov Chain)这种严格的概率统计方法用于语言文本分析的可能性。可以说,这是最早在数学意义上提出的自然语言模型,也是一个基于概率和统计的语言模型。
但是,语言学家乔姆斯基(Noam Chomsky)并不认可这一路径。他指出,有限状态(如N元组)不足以描述自然语言,而应代之以一种生成语法,即面向有限长字符构成的有限词汇,规定的一组能够生成所有可能句子的规则。乔姆斯基的思想,代表了这一时期以规则和实例为导向,对语言现象进行计算机处理并试图从中研发出机器翻译和聊天机器人等应用的进路。
时至今日,乔姆斯基和他所代表的这一进路,虽然仍具有学术意义和历史价值,但在人工智能技术中已不再有影响力。取而代之的是基于人工神经网络的语言模型:2001年,约书亚·本吉奥(Yoshua Bengio)等人撰写了《一种神经概率语言模型》(“A neural probabilistic language model”),开启了语言模型的新篇章。他们的工作可以被视为N-grams的某种延续和扩展:用可认为连续的方式表征单词,并用结构多变的神经网络来代替简单的马尔科夫链形式。
大型语言模型的繁荣与隐忧
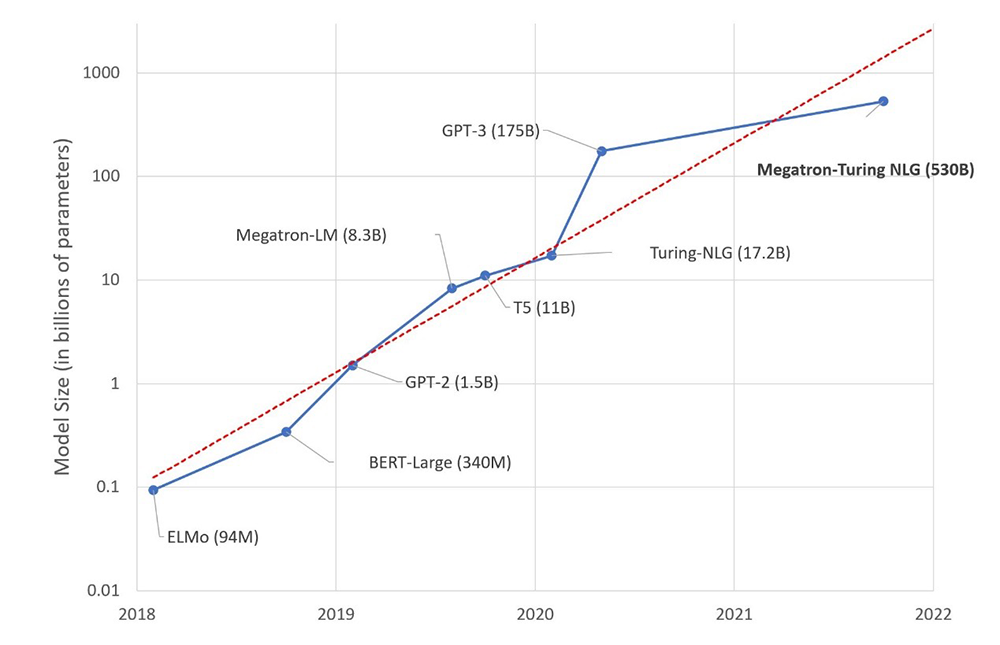
随着研究者发现更为复杂的建模能够更为贴近人们的语言日常,今天人工智能领域热议的“语言模型”,指的已不再是这些较为原始的模型,而是2018年以来陆续发展的一系列参数规模上亿的大型语言模型(large language model,LLM)。在短短4年时间里,大型语言模型的参数数量保持着指数增长势头。据预测,OpenAI开发中的最新大型语言模型GPT-4将包含约100万亿的参数,与人脑的突触在同一数量级。由此,出现了一个新的人工智能口号:“规模就是一切”。
图片来源:https://huggingface.co/blog/large-language-models
更大的模型带来了更高的训练成本。这既包括智力支出和经济成本,也有不可忽视的环境影响。马萨诸塞大学阿姆赫斯特分校的一项研究指出,仅是训练参数数量不到最新模型1%的BERT模型,就会造成652千克的碳排放,可与跨越美国东西海岸的一次航班所造成的碳排放相比拟。
与此同时,越来越大的模型所提升的效用正在缩小。人们发现,模型参数规模增长10倍,得到的性能提升往往不到10个百分点。相比之下,倒是那些同等(乃至更小)参数规模的新模型,会带来真正质的提升。还有一些研究者尝试把大模型拆分成更多小模型并集之所长,但由于其模型参数不会全部加入计算,“这是否会是参数量狂热之下的一种数字泡沫”的质疑也随之而来。
而且,随着大型语言模型的广泛应用,一些负面的社会效应也开始显现。据预测,到2023年,约有5%的大学生会使用大型语言模型生成的文本来代替本应由他们自己撰写的作业,而与之对抗的检测手段则很难真正发挥作用。
就在上月,Meta公司发布了一个名为Galactica的大型语言模型,宣称它“可以总结学术论文,解决数学问题,生成维基百科文章,编写科学代码,标记分子和蛋白质,以及更多功能。”但上线仅3天,该模型就在巨大争议中撤回:它虽然能生成一些貌似通顺的学术文本,但文本中的信息是完全错误的——貌似合理的化学方程,描述的是实际上并不会发生的化学反应;格式合规的引文参考的是子虚乌有的文献;甚而种族主义、性别歧视的观点,也能通过模型生成的文本而被包装成“科学研究”。批评者质疑,这样的模型会使学术造假变得更为隐蔽,也将使科学谣言的散播变得更加便利。

2022年10月,上海人民广场。澎湃新闻记者 周平浪 图
一般的观点认为,尽管人工智能系统能在诸多特定任务中显现出看似智能的行为,但它们并不像人那样理解它们所处理的数据。譬如,Character.ai、ChatGPT这样的模型应用虽然已能流畅地与人进行“对话”,而且相当程度上顾及到上下文,然而,人工智能系统中无法预测的错误、对于一般情况推广能力的欠缺等都被视为它们无法“理解”的证据。这样的大型语言模型并未真正“理解”语言所描述的现实世界。
大型语言模型的局限性逐渐暴露在公众面前,单纯追求模型尺度的增加,不仅面临经济、环保等因素的限制,而且也遭受技术群体内部的质疑。这是一种“为科学而科学”的精神,还是只是一种对单一尺度的盲信?《麻省理工技术评论》作者哈文(Will Douglas Heaven)写道:“Meta的失误和它的傲慢再次表明,大科技公司对大型语言模型的严重局限性视而不见。”
“镜像假说”与大型语言模型的社会内涵
但是,知名的复杂性科学研究机构圣塔菲研究所(Santa Fe Institute)研究人员在2022年10月发表的一篇预印本论文中指出,这项关于人工智能的基本共识正被打破。
一项面向自然语言处理领域活跃研究者的调查显示,51%的受访者相信,提供充分的数据和计算资源,仅凭文本训练的语言模型能够在某种非平凡的意义上理解自然语言。随着模型越来越能输出类似人类写作的文本,文本的真诚性成为一个日益严峻的问题。对于大型语言模型如何工作,科学家实际和外行人一样不知情。这些神经网络的内在工作模式,很大程度上仍是一个谜团。神经科学家特伦斯·塞诺夫斯基(Terrence Sejnowski)如此描述大型语言模型的出现:“就好像突然达到了一个门槛,出现了一个外星人,却可以用一种特别接近人类的方式与我们交流。只有一件事是清楚的——它们不是人类......它们行为的某些方面似乎是智能的,但如果不是人类的智能,它们的智能的本质是什么?”
塞诺夫斯基并未为“外星人”般的“智能”所阻吓。他另辟蹊径,提出“反向图灵测试”的观点:语言模型所给出的“看似体现智能的东西”,成为了“反映面试者智能的镜子”,而研究人与机器的“对话”,我们可能更多了解到的是人类用户的智能和信念。毕竟,相较于难以确定的“语言模型的智能”,人类用户在与这样的计算机系统的交互中所表达的内容是可以确定的。他发现,人们输入给语言模型的提示词或问题,越是精心设计,模型给出的结果就越是反过来让人信服它的“智能”。这就好像人们在与高手对弈时也能促使自己提升棋艺一般,从人工智能的“回应”中可以看出人们深层意愿的镜像。这被他称为“镜像假说”。
赛诺夫斯基援引人类学家罗宾·邓巴在20世纪80年代末提出的观点,认为智能并不是从在一个荒凉的世界中生存的智力需求中产生的,毕竟很多其他动物依靠它们的小脑袋也能存活下去。相反,智能的“大爆炸”开始于同其他人的合作与竞争。从这个角度看,所谓的“智能”并不是单个行动体(agent)具有的某种“属性”,而是始终在与他者的交互中呈现出的一种集体状态,即(虽然只是假设性地)“进入”别人的大脑,“了解”他们的感知、思考和感受,与他人产生共鸣,从而预测他们的行为、影响他们的行动。将同样的能力应用于自身,可以使我们进行反省,使我们的行为合理化,并对未来进行规划。在这种观点中,意识不是从天而降的神秘幽灵,而只是我们用来描述这种“设身处地”与“躬身自省”的语汇。
“镜像假说”的提出,为大型语言模型重新赋予了社会性的内涵。与语言模型的交互并不是一种真正的知识生产(如Meta公司宣称Galactica要做到的那样),而是通过一种机制来反映人们自身的诉求和意图,为理解这些抽象的“概念”提供了具体的“事实”。从这个视角来看,人工智能的发展,所需要的不仅是具体计算技术的发展和对智能模型的“唯象”考察,而是仍旧需要某种理论的提炼乃至想象,不断吸收和接纳对人自身更深层的理解。这些,无疑都超出了“规模就是一切”所宣称的范畴。
(作者朱恬骅系上海社会科学院文学研究所助理研究员;陈涵洋系独立开发者)