OpenAI教GPT-3学会上网;爱因斯坦广义相对论通过严格检验

机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周论文包括 OpenAI 教会了 WebGPT 上网;爱因斯坦广义相对论通过了一场历时 16 年的严格检验。
目录:
WebGPT: Browser-assisted question-answering with human feedback
Multi-caption Text-to-Face Synthesis: Dataset and Algorithm
Strong-Field Gravity Tests with the Double Pulsar
PTR: A Benchmark for Part-based Conceptual, Relational, and Physical Reasoning
A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING
Learning to Compose Visual Relations
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:WebGPT: Browser-assisted question-answering with human feedback
作者:Reiichiro Nakano 、 Jacob Hilton 等
论文地址:https://cdn.openai.com/WebGPT.pdf
摘要:如果 AI 学会上网,那么它就拥有了无限获取知识的方式,之后会发生什么就不太好预测了。于是著名 AI 研究机构 OpenAI 教那个开启了通用人工智能大门、体量巨大的人工智能模型 GPT-3 学会了上网。
现在,这个模型能正确地处理一些棘手的问题:比如,有人询问了一个错误的问题:「莎士比亚什么时候写的《哈利 · 波特》系列小说?」该模型回答:莎士比亚没有写《哈利 · 波特》小说。这些小说是由 J.K. 罗琳完成的……
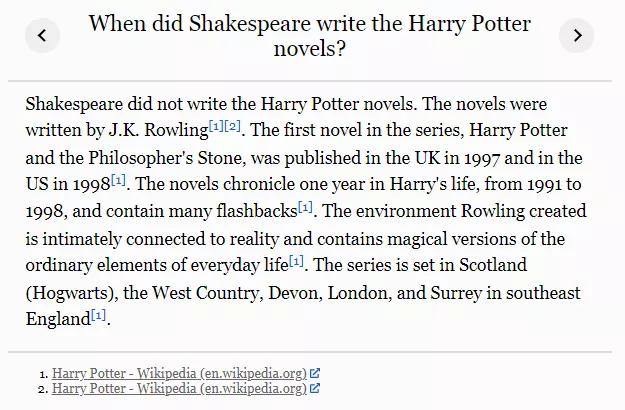 从回答的内容来看,这个模型完全正确,此外,该模型还给读者提供了引用文献,如蓝体数字所示,答案的最后还给出了相关链接,点击每个链接,还能链接到相应的网页。
从回答的内容来看,这个模型完全正确,此外,该模型还给读者提供了引用文献,如蓝体数字所示,答案的最后还给出了相关链接,点击每个链接,还能链接到相应的网页。OpenAI 对 GPT-3 进行了微调,以使用基于文本的网络浏览器更准确地回答开放式问题,这允许模型搜索和浏览网页。该模型原型复制了人类在线研究问题答案的方式,涉及提交搜索查询,跟踪链接,以及向上和向下滚动网页。模型经过训练后,它会引用信息源,这使得模型提供反馈更容易,从而提高事实的准确性。
此外,该模型还提供了一个开放式问题和浏览器状态摘要,并且必须具有诸如「Search……」、「Find in page:……」或「Quote:……」之类的命令。通过这种方式,模型从网页中收集段落,然后使用这些段落来撰写答案。通过设置任务,OpenAI 能够使用模仿学习(imitation learning)在不同任务上训练模型,然后根据人类反馈优化答案质量。OpenAI 在 ELI5 上对模型进行了训练和评估,其中 ELI5 是一个由 Reddit 用户提问的问题集。
总体而言,OpenAI 对 GPT-3 模型家族的模型进行了微调,重点研究了具有 760M、13B 和 175B 参数的模型。从这些模型出发,OpenAI 使用了四种主要的训练方法:
行为克隆(Behavior cloning,BC):OpenAI 使用监督学习对演示进行了微调,并将人类演示者发出的命令作为标签;
建模奖励(Reward modeling,RM):从去掉 unembedding 层的 BC 模型开始,OpenAI 训练的模型可以接受带有引用的问题和答案,并输出标量奖励,奖励模型使用交叉熵损失进行训练;
强化学习(RL):OpenAI 使用 Schulman 等人提出的 PPO 微调 BC 模型。对于环境奖励,OpenAI 在 episode 结束时获取奖励模型分数,并将其添加到每个 token 的 BC 模型的 KL 惩罚中,以减轻奖励模型的过度优化;
剔除抽样(best-of-n):OpenAI 从 BC 模型或 RL 模型(如果未指定,则使用 BC 模型)中抽取固定数量的答案(4、16 或 64),并选择奖励模型排名最高的答案。
推荐:OpenAI 教 GPT-3 学会上网,「全知全能」的 AI 模型上线了。
论文 2:Multi-caption Text-to-Face Synthesis: Dataset and Algorithm
作者:孙建新等
论文地址:https://zhaoj9014.github.io/pub/MM21.pdf
摘要:文本人脸合成指的是基于一个或多个文本描述,生成真实自然的人脸图像,并尽可能保证生成的图像符合对应文本描述,可以用于人机交互,艺术图像生成,以及根据受害者描述生成犯罪嫌疑人画像等。针对这个问题,中科院自动化所联合北方电子设备研究所提出了一种基于多输入的文本人脸合成方法(SEA-T2F),并建立了第一个手工标注的大规模人脸文本描述数据集(CelebAText-HQ)。该方法首次实现多个文本输入的人脸合成,与单输入的算法相比生成的图像更加接近真实人脸。相关成果论文《Multi-caption Text-to-Face Synthesis: Dataset and Algorithm》已被 ACM MM 2021 录用。
相较于文本到自然图像的生成,文本到人脸生成是一个更具挑战性的任务,一方面,人脸具有更加细密的纹理和模糊的特征,难以建立人脸图像与自然语言的映射,另一方面,相关数据集要么是规模太小,要么直接基于属性标签用网络生成,目前为止,还没有大规模手工标注的人脸文本描述数据集,极大地限制了该领域的发展。此外,目前基于文本的人脸生成方法 [1,2,3,4] 都是基于一个文本输入,但一个文本不足以描述复杂的人脸特征,更重要的是,由于文本描述的主观性,不同人对于同一张图片的描述可能会相互冲突,因此基于多个文本描述的人脸生成具有很重大的研究意义。
针对该问题,团队提出了一个基于多输入的文本人脸生成算法。算法采用三阶段的生成对抗网络框架,以随机采样的高斯噪声作为输入,来自不同文本的句子特征通过 SFIM 模块嵌入到网络当中,在网络的第二第三阶段分别引入了 AMC 模块,将不同文本描述的单词特征与中间图像特征通过注意力机制进行融合,以生成更加细密度的特征。为了更好地在文本中学习属性信息,团队设计了一个属性分类器,并引入属性分类损失来优化网络参数。
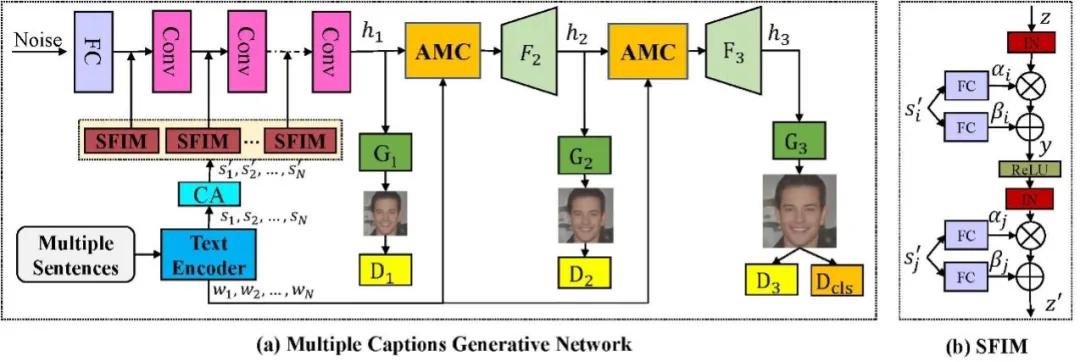 图 2 模型框架示意图
图 2 模型框架示意图推荐:中科院自动化所联合北方电子设备研究所提出多输入文本人脸合成方法,数据代码已开源。
论文 3:Strong-Field Gravity Tests with the Double Pulsar
作者:M. Kramer 等人
论文地址:https://journals.aps.org/prx/abstract/10.1103/PhysRevX.11.041050
摘要:广义相对论是爱因斯坦在 1915 年完成、1916 年正式发表的重要引力理论。该理论在天体物理学中有着非常重要的应用:它直接推导出某些大质量 恒星会终结为一个黑洞。从 1916 年正式发表以来,物理学界对于这一理论的实验验证就从未停止。其中,东英吉利大学(UEA)和曼彻斯特大学的研究人员联合进行了一项长达 16 年的实验。这个国际研究团队通过遍布全球的七台射电望远镜观察一对脉冲星,以此来进行一些迄今为止最严格的广义相对论测试。结果证明,广义相对论经受住了考验。
 该研究于 12 月 13 日发表在《Physical Review X》杂志上。「过去 16 年里,我们对双脉冲星的观测被证明与爱因斯坦的广义相对论惊人地一致,精确程度在 99.99% 以内。」论文作者表示。
该研究于 12 月 13 日发表在《Physical Review X》杂志上。「过去 16 年里,我们对双脉冲星的观测被证明与爱因斯坦的广义相对论惊人地一致,精确程度在 99.99% 以内。」论文作者表示。在马克斯普朗克射电天文研究所 Michael Kramer 的带领下,来自十个国家的国际研究团队对爱因斯坦的理论进行了迄今为止最严格的测试。
该研究基于由团队成员在 2003 年发现的双脉冲星进行实验,它是目前用来测试爱因斯坦理论最精确的实验室。尽管广义相对论是在这类极端恒星以及用于研究它们的技术都未知的时候构思出来的。
研究团队发现的双脉冲星由两颗脉冲星组成,它们在短短 147 分钟内以大约 100 万公里 / 小时的速度相互环绕。其中一颗脉冲星(主星)旋转得非常快,大约每秒 44 次,而另一颗脉冲星(伴星)的自转周期约为 2.8 秒。它们围绕彼此的运动几乎可以用作完美的引力实验室,可以在存在非常强的引力场的情况下测试引力理论。该研究测试了爱因斯坦理论的基石,即引力波携带的能量。其精度是诺贝尔奖得主发现的 Hulse-Taylor 脉冲星的 25 倍,是目前使用的引力波探测器的精度的 1000 倍。
推荐:爱因斯坦广义相对论刚刚通过了一场历时 16 年的严格检验。
论文 4:PTR: A Benchmark for Part-based Conceptual, Relational, and Physical Reasoning
作者:Yining Hong 、 Li Yi 等
论文地址:http://ptr.csail.mit.edu/assets/ptr.pdf
摘要:本文引入了一个新的名为 PTR 的大规模诊断型视觉推理数据集。PTR 包含大约七万 RGBD 合成图像,带有关于语义实例分割、颜色属性、空间和几何关系以及某些物理属性(例如稳定性)的物体和局部标注。这些图像配有五种类型的问题:概念型推理,关系型推理,类比型推理,数学推理和物理推理。这些类型均来自于人类认知推理的重要方面,但在以往的工作中并没有被充分探索过。本文在这个数据集上检验了几个最先进的视觉推理模型。研究者观察到它们的表现远远不及人类表现,特别是在一些较新的推理类型(例如几何,物理问题)任务上。该研究期待这个数据集能够促进机器推理向更复杂的人类认知推理推进。
PTR 数据集有七万的 RGBD 图片和 70 万基于这些图片的问题。本文作者提供了详细的图片标注,包括语义实例分割、几何、物理状态的标注。数据集的生成采取了精细的偏差和噪声控制。下图总结了 PTR 数据集涵盖的概念。
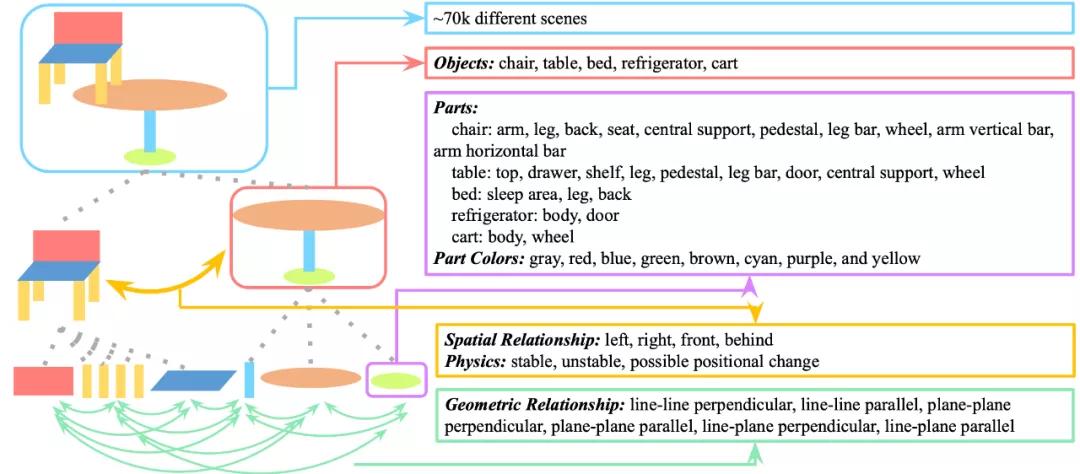 图三:PTR 数据集中的概念
图三:PTR 数据集中的概念可以看出,PTR 数据集具有丰富的认知层面的概念和关系。在物体整体方面,具有空间关系、物理状态等概念,在局部方面,有几何关系等概念。整体 - 部分的加入大大增加了视觉推理的层次性和丰富性。PTR 数据集包含了五类问题:概念型推理,关系型推理,类比型推理,数学推理和物理推理。
推荐:MIT、UCLA、斯坦福联合提出新一代视觉推理数据集。
论文 5:A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING
作者:Robert Kirk 、 Amy Zhang 等
论文地址:https://arxiv.org/pdf/2111.09794v1.pdf
摘要:强化学习 (RL) 可用于自动驾驶汽车、机器人等一系列应用,其在现实世界中表现如何呢?现实世界是动态、开放并且总是在变化的,强化学习算法需要对环境的变化保持稳健性,并在部署期间能够进行迁移和适应没见过的(但相似的)环境。
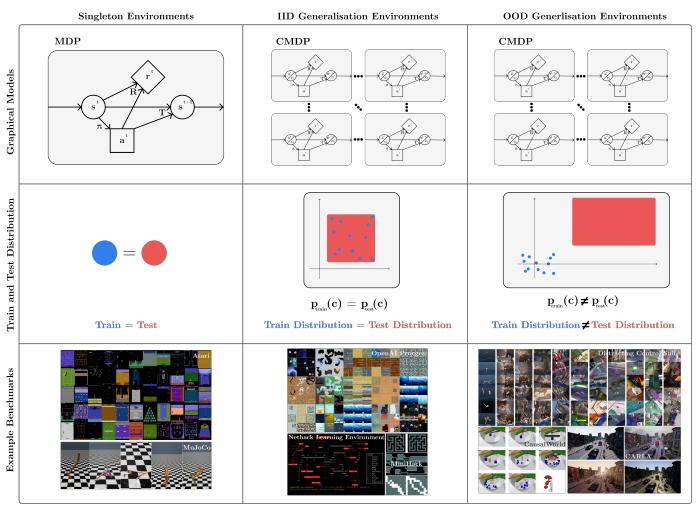 图 1:强化学习泛化
图 1:强化学习泛化然而,当前许多强化学习研究都是在 Atari 和 MuJoCo 等基准上进行的,其具有以下缺点:它们的评估策略环境和训练环境完全相同;这种环境相同的评估策略不适合真实环境。
目前,许多研究者已经意识到这个问题,开始专注于改进 RL 中的泛化。来自伦敦大学学院、UC 伯克利机构的研究者撰文《 A SURVEY OF GENERALISATION IN DEEP REINFORCEMENT LEARNING 》,对深度强化学习中的泛化进行了研究。
该研究提出了一种形式和术语,以用于讨论泛化问题,这一工作是建立在之前研究 [12, 13, 14, 15, 16] 的基础上进行的。本文将先前的工作统一成一个清晰的形式描述,这类问题在 RL 中被称为泛化。
该研究提出了对现有基准的分类方法,可用于测试泛化。该研究的形式使我们能够清楚地描述泛化基准测试和环境设计的纯 PCG(Procedural Content Generation) 方法的弱点:完整的 PCG 环境会限制研究精度。该研究建议未来的环境应该使用 PCG 和可控变异因素的组合。
该研究建议对现有方法进行分类以解决各种泛化问题,其动机是希望让从业者能够轻松地选择给定具体问题的方法,并使研究人员能够轻松了解使用该方法的前景以及可以做出新颖和有用贡献的地方。该研究对许多尚未探索的方法进行进一步研究,包括快速在线适应、解决特定的 RL 泛化问题、新颖的架构、基于模型的 RL 和环境生成。
该研究批判性地讨论了 RL 研究中泛化的现状,推荐了未来的研究方向。特别指出,通过构建基准会促进离线 RL 泛化和奖励函数进步,这两者都是 RL 中重要的设置。此外,该研究指出了几个值得探索的设置和评估指标:调查上下文效率和在持续的 RL 设置中的研究都是未来工作必不可少的领域。
推荐:伦敦大学学院、UC 伯克利学者联手,撰文综述深度强化学习泛化研究。
论文 6:Learning to Compose Visual Relations
作者:Nan Liu, Shuang Li, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba
论文地址:https://arxiv.org/abs/2111.09297
摘要:在一篇 NeurIPS 2021 Spotlight 论文中,来自 MIT 的研究者开发了一种可以理解场景中对象之间潜在关系的模型。该模型一次表征一种个体关系,然后结合这些表征来描述整个场景,使得模型能够从文本描述中生成更准确的图像。
该研究提出使用 Energy-Based 模型将个体关系表征和分解为非规一化密度。关系场景描述被表征为关系中的独立概率分布,每个个体关系指定一个单独的图像上的概率分布。这样的组合方法可以建模多个关系之间的交互。
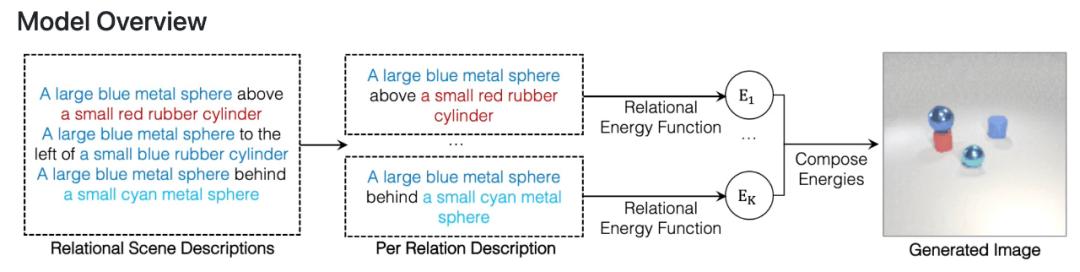 该研究表明所提框架能够可靠地捕获和生成带有多个组合关系的图像,并且能够推断潜在的关系场景描述,并且能够稳健地理解语义上等效的关系场景描述。
该研究表明所提框架能够可靠地捕获和生成带有多个组合关系的图像,并且能够推断潜在的关系场景描述,并且能够稳健地理解语义上等效的关系场景描述。在泛化方面,该方法可以推广到以前未见过的关系描述上,包括对象和描述来自训练期间未见过的数据集。这种泛化对于通用人工智能系统适应周围世界的无限变化至关重要。
此外,该系统还可以反向工作——给定一张图像,它可以找到与场景中对象之间的关系相匹配的文本描述。该模型还可通过重新排列场景中的对象来编辑图像,使它们与新的描述相匹配。
 推荐:MIT 新研究让 AI 像人一样「看」世界。
推荐:MIT 新研究让 AI 像人一样「看」世界。论文 7:PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
作者:Xiaoyi Dong 、 Jianmin Bao 、 Ting Zhang 等
论文地址:https://arxiv.org/pdf/2111.12710v1.pdf
摘要:来自中国科学技术大学、微软亚研等机构的研究者提出了学习感知 codebook( perceptual codebook ,PeCo),用于视觉 transformer 的 BERT 预训练。目前,BEiT 成功地将 BERT 预训练从 NLP 领域迁移到了视觉领域。BEiT 模型直接采用简单的离散 VAE 作为视觉 tokenizer,但没有考虑视觉 token 语义层面。相比之下,NLP 领域中的离散 token 是高度语义化的。这种差异促使研究者开始学习感知 codebook,他们发现了一个简单而有效的方法,即在 dVAE 训练期间强制执行感知相似性。
该研究证明 PeCo 生成的视觉 token 能够表现出更好的语义,帮助预训练模型在各种下游任务中实现较好的迁移性能。例如,该研究使用 ViT-B 主干在 ImageNet-1K 上实现了 84.5% 的 Top-1 准确率,在相同的预训练 epoch 下比 BEiT 高 1.3。此外,该方法还可以将 COCO val 上的目标检测和分割任务性能分别提高 +1.3 box AP 和 +1.0 mask AP,并且将 ADE20k 上的语义分割任务提高 +1.0 mIoU。
该研究提出,在不包含像素损失的情况下,对模型强制执行原始图像和重构图像之间的感知相似性。感知相似性不是基于像素之间的差异得到的,而是基于从预训练深度神经网络中提取的高级图像特征表示之间的差异而得到。该研究希望这种基于 feature-wise 的损失能够更好地捕捉感知差异并提供对低级变化的不变性。下图从图像重构的角度展示了模型使用不同损失的比较,结果表明图像在较低的 pixel-wise 损失下可能不会出现感知相似:
 图 1. 不同损失下的图像重构比较。每个示例包含三个图像,输入(左)、使用 pixel-wise 损失重构图像(中)、使用 pixel-wise 损失和 feature-wise 损失重构图像(右)。与中间图像相比,右侧图像在感知上与输入更相似。
图 1. 不同损失下的图像重构比较。每个示例包含三个图像,输入(左)、使用 pixel-wise 损失重构图像(中)、使用 pixel-wise 损失和 feature-wise 损失重构图像(右)。与中间图像相比,右侧图像在感知上与输入更相似。推荐:视觉 Transformer BERT 预训练新方式:中科大、MSRA 等提出 PeCo,优于 MAE、BEiT。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. You Only Need One Model for Open-domain Question Answering. (from Christopher D. Manning)
2. Am I Me or You? State-of-the-Art Dialogue Models Cannot Maintain an Identity. (from Jason Weston)
3. Adapting Document-Grounded Dialog Systems to Spoken Conversations using Data Augmentation and a Noisy Channel Model. (from Hermann Ney)
4. Pay More Attention to History: A Context Modeling Strategy for Conversational Text-to-SQL. (from Yan Zhang)
5. Amortized Noisy Channel Neural Machine Translation. (from Kyunghyun Cho)
6. Event Linking: Grounding Event Mentions to Wikipedia. (from Dan Roth)
7. Design Challenges for a Multi-Perspective Search Engine. (from Dan Roth)
8. DocAMR: Multi-Sentence AMR Representation and Evaluation. (from Salim Roukos)
9. Learning to Transpile AMR into SPARQL. (from Salim Roukos)
10. Maximum Bayes Smatch Ensemble Distillation for AMR Parsing. (from Salim Roukos)
本周 10 篇 CV 精选论文是:
1. Label, Verify, Correct: A Simple Few Shot Object Detection Method. (from Andrew Zisserman)
2. Mining Minority-class Examples With Uncertainty Estimates. (from Jian Pei, Qi Tian)
3. More Control for Free! Image Synthesis with Semantic Diffusion Guidance. (from Trevor Darrell)
4. Twitter-COMMs: Detecting Climate, COVID, and Military Multimodal Misinformation. (from Trevor Darrell)
5. Interpolated Joint Space Adversarial Training for Robust and Generalizable Defenses. (from Rama Chellappa)
6. IFR-Explore: Learning Inter-object Functional Relationships in 3D Indoor Scenes. (from Qi Li, Leonidas Guibas)
7. PartGlot: Learning Shape Part Segmentation from Language Reference Games. (from Leonidas Guibas)
8. Object Pursuit: Building a Space of Objects via Discriminative Weight Generation. (from Leonidas Guibas)
9. Efficient Geometry-aware 3D Generative Adversarial Networks. (from Leonidas Guibas)
10. TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning. (from Shuicheng Yan, Ling Shao)
本周 10 篇 ML 精选论文是:
1. ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning. (from Michael I. Jordan)
2. Learning soft interventions in complex equilibrium systems. (from Bernhard Schölkopf)
3. Graph Structure Learning with Variational Information Bottleneck. (from Philip S. Yu)
4. A Self-supervised Mixed-curvature Graph Neural Network. (from Philip S. Yu)
5. GEO-BLEU: Similarity Measure for Geospatial Sequences. (from Toru Shimizu)
6. Measuring Complexity of Learning Schemes Using Hessian-Schatten Total-Variation. (from Michael Unser)
7. Spatial-Temporal-Fusion BNN: Variational Bayesian Feature Layer. (from Leszek Rutkowski, Dacheng Tao)
8. Deep Q-Network with Proximal Iteration. (from Michael L. Littman)
9. Characterizing and addressing the issue of oversmoothing in neural autoregressive sequence modeling. (from Kyunghyun Cho)
10. M3E2: Multi-gate Mixture-of-experts for Multi-treatment Effect Estimation. (from Martin Ester)
 © THE END
© THE END转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com:,。视频小程序赞,轻点两下取消赞在看,轻点两下取消在看
原标题:《7 Papers & Radios | OpenAI教GPT-3学会上网;爱因斯坦广义相对论通过严格检验》