矩阵乘法无需相乘,速度提升100倍:一个神经元顶5到8层神经网络

机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周论文包括 MIT 计算机科学博士生 Davis Blalock 及其导师 John Guttag 教授发表的研究,即矩阵乘法无需相乘,运行速度是精确矩阵乘积的 100 倍,是当前近似方法的 10 倍;耶路撒冷希伯来大学的研究者对单个神经元的计算复杂度进行了研究,发现一个神经元顶 5 到 8 层神经网络。
目录:
Graph Self-Supervised Learning: A Survey
Online Multi-Granularity Distillation for GAN Compression
Multiplying Matrices Without Multiplying
Dirty Road Can Attack: Security of Deep Learning based Automated Lane Centering under Physical-World Attack
Single Cortical Neurons as Deep Artificial Neural Networks
Mutual gaze with a robot affects human neural activity and delays decision-making processes
EYES TELL ALL: IRREGULAR PUPIL SHAPES REVEAL GAN-GENERATED FACES
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Graph Self-Supervised Learning: A Survey
作者:Yixin Liu、Shirui Pan、Ming Jin 等
论文链接:https://arxiv.org/pdf/2103.00111.pdf
摘要:近年来,自监督学习逐渐广泛应用于计算机视觉、自然语言处理等领域。随着该技术的蓬勃发展,自监督学习在图机器学习和图神经网络上的应用也逐渐广泛起来,图自监督学习成为了图深度学习领域的新发展趋势。本文是来自澳大利亚蒙纳士大学(Monash University)图机器学习团队联合中科院、联邦大学,以及数据科学权威 Philip S. Yu 对图自监督学习领域的最新综述,从研究背景、学习框架、方法分类、研究资源、实际应用、未来的研究方向的方面,为图自监督学习领域描绘出一幅宏伟而全面的蓝图。
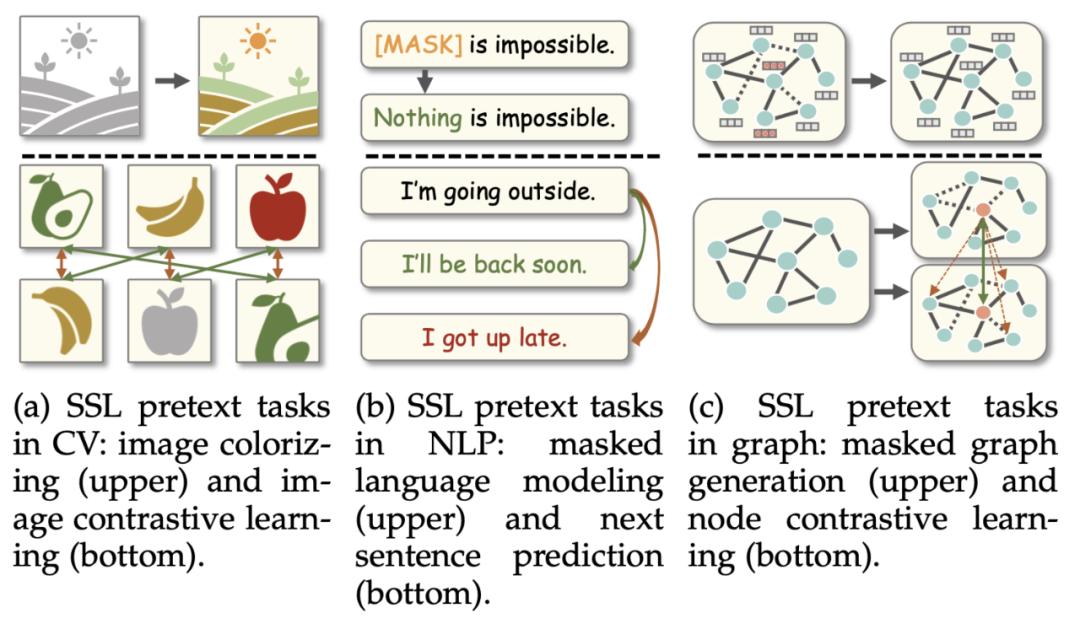
不同领域的自监督任务对比。
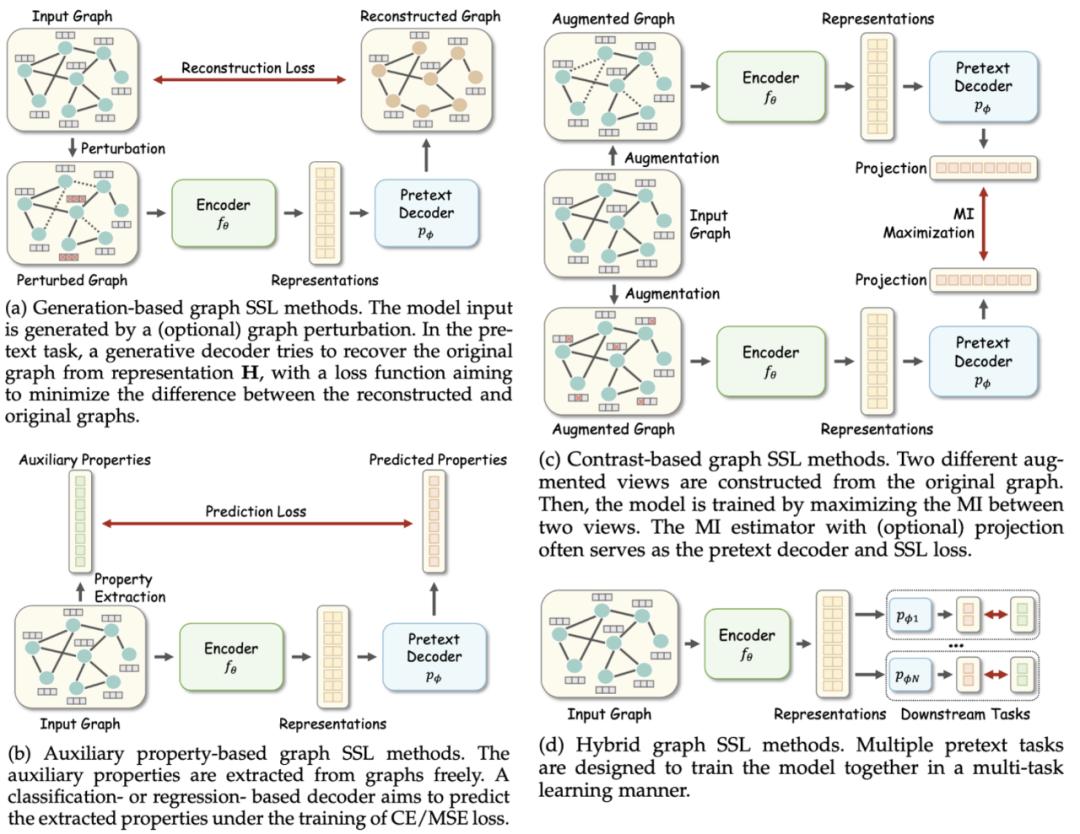
4 种图自监督学习方法分类。
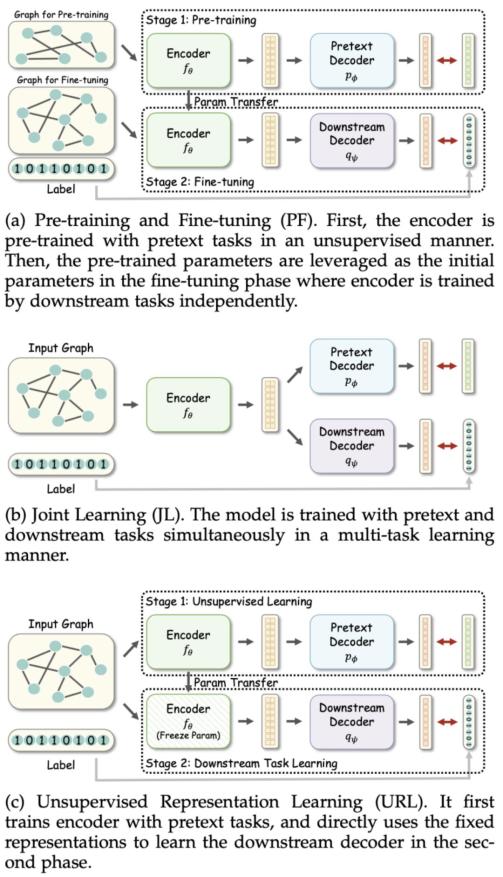
3 种自监督学习模式分类。
推荐:数据挖掘领域大师俞士纶团队新作:最新图自监督学习综述。
论文 2:Online Multi-Granularity Distillation for GAN Compression
作者:Yuxi Ren、Jie Wu、Xuefeng Xiao 等
论文链接:https://arxiv.org/abs/2108.06908
摘要:GAN 压缩方向已经成为业界的挑战之一,不少高校和科技公司对此投入研究力量。但当前的 GAN 压缩算法主要存在两个方面的问题:一方面,当前研究倾向于直接采用成熟的模型压缩技术来进行压缩,而这些技术不是面向 GAN 定制的,缺乏对 GAN 复杂特性和结构的探索;另一方面,GAN 压缩通常被规划为一个多阶段的任务,多阶段设置中对时间和计算资源的要求较高。
为了解决上述问题,字节跳动 - 智能创作团队提出了一种面向 GAN 压缩的在线多粒度蒸馏算法(Online Multi-Granularity Distillation, OMGD)。该算法能够把 GAN 模型的计算量减少到最低 1/46、参数量减少到最低 1/82 的程度,并保持原来的图像生成质量。这为在资源受限的设备上部署实时图像翻译的 GAN 模型提供了一个可行的解决方案。
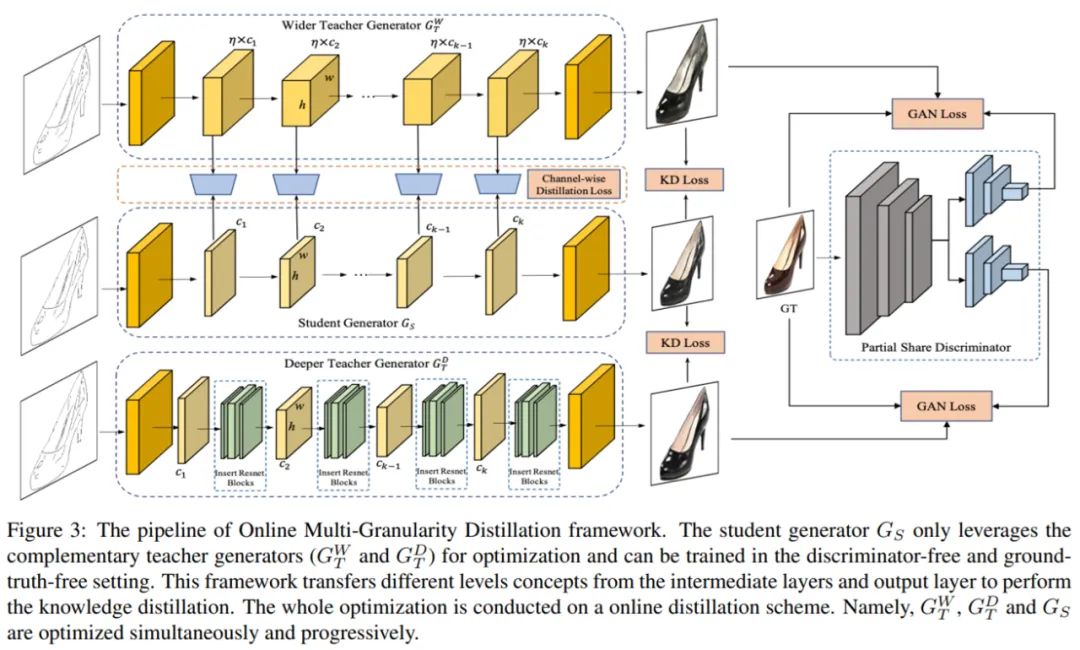
OMGD 框架图。
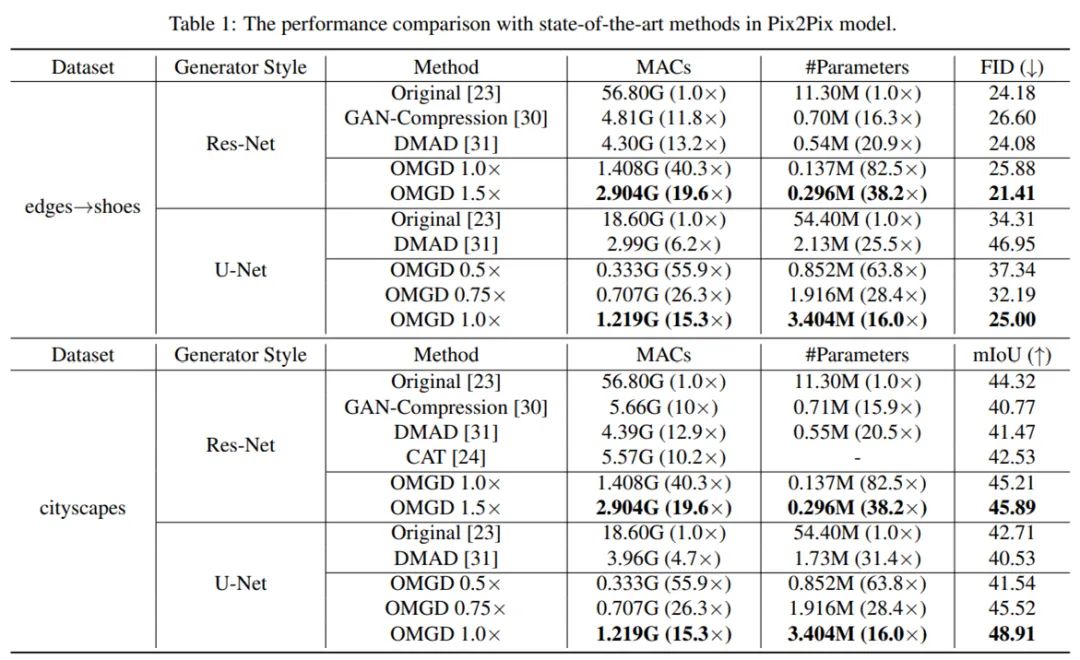
与 SOTA 方法的性能比较。

定性压缩结果比较。
推荐:字节跳动提出面向 GAN 压缩的在线多粒度蒸馏算法,算力降至 1/46。论文入选 ICCV 2021。
论文 3:Multiplying Matrices Without Multiplying
作者:Davis Blalock、John Guttag
论文链接:https://arxiv.org/abs/2106.10860
摘要:矩阵乘法是机器学习中最基础和计算密集型的操作之一。因此,研究社区在高效逼近矩阵乘法方面已经做了大量工作,比如实现高速矩阵乘法库、设计自定义硬件加速特定矩阵的乘法运算、计算分布式矩阵乘法以及在各种假设下设计高效逼近矩阵乘法(AMM)等。
在 MIT 计算机科学博士生 Davis Blalock 及其导师 John Guttag 教授发表的论文中,他们为逼近矩阵乘法任务引入了一种基于学习的算法,结果显示该算法显著优于现有方法。在来自不同领域的数百个矩阵的实验中,这种学习算法的运行速度是精确矩阵乘积的 100 倍,是当前近似方法的 10 倍。这篇论文入选了机器学习顶会 ICML 2021。此外,在一个矩阵提前已知的常见情况下,研究者提出的方法还具有一个有趣的特性——需要的乘加运算(multiply-adds)为零。这些结果表明,相较于最近重点进行了大量研究与硬件投入的稀疏化、因式分解和 / 或标量量化矩阵乘积而言,研究者所提方法中的核心操作——哈希、求平均值和 byte shuffling 结合可能是更有前途的机器学习构建块。
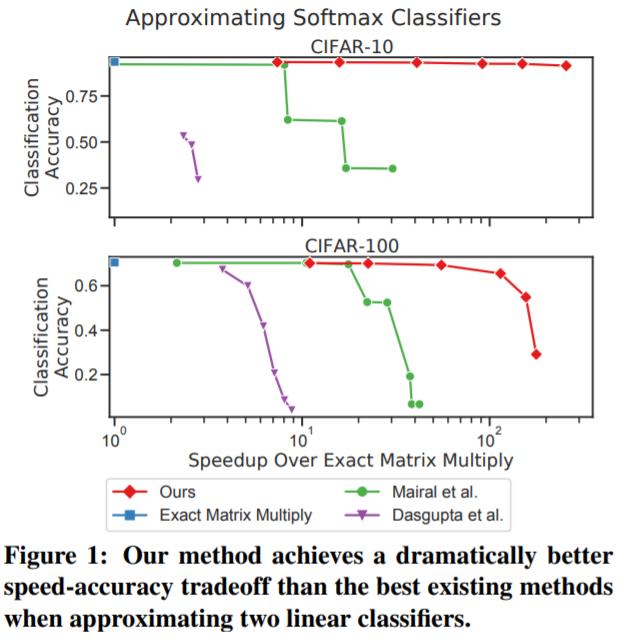
在 CIFAR-10 和 CIFAR-100 数据集上,使用该研究的方法及其最佳性能竞争对手的方法近似 AB 的结果。
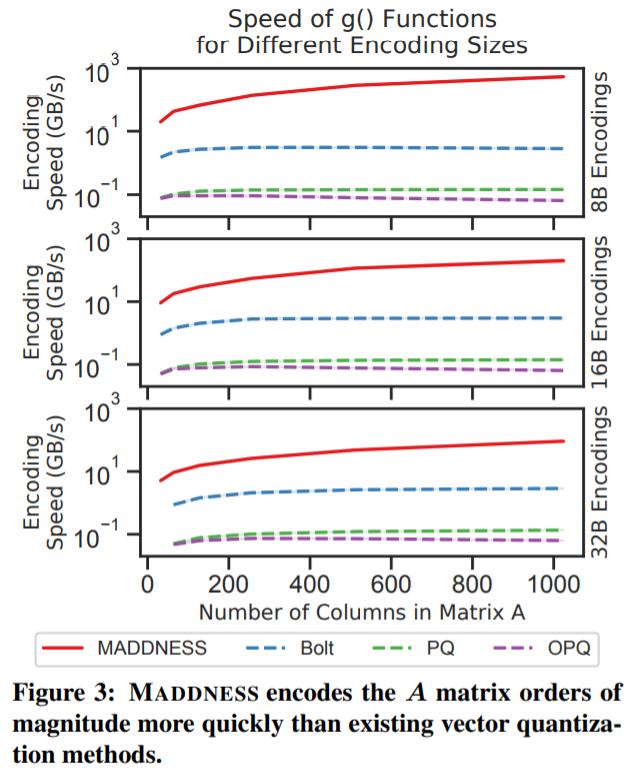
MADDNESS 比现有方法快两个数量级,其吞吐量随行的长度而增加。
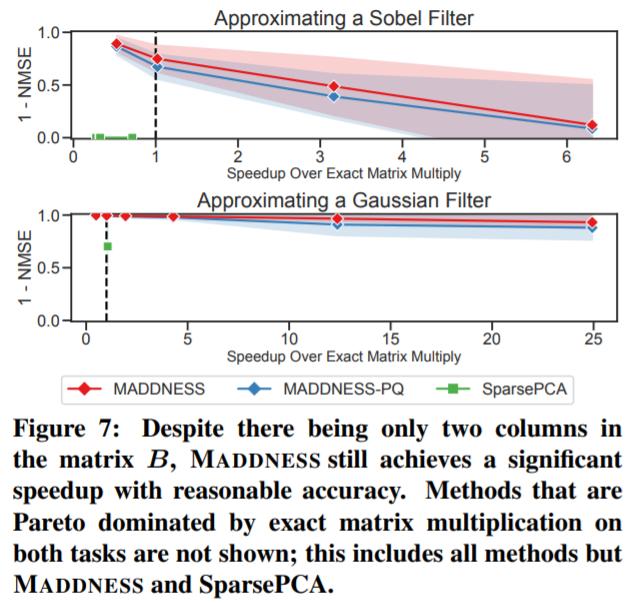
只有 MADDNESS 比精确矩阵乘积更有优势。
推荐:矩阵乘法无需相乘,速度提升 100 倍:MIT 大佬的新研究引发热议
论文 4:Dirty Road Can Attack: Security of Deep Learning based Automated Lane Centering under Physical-World Attack
作者:Takami Sato、 Junjie Shen、 Ningfei Wang 等
论文链接:https://arxiv.org/pdf/2009.06701.pdf
摘要:来自加州大学尔湾分校、字节跳动和美国东北大学的研究者,首次在物理世界对抗性攻击下对最先进的基于 DNN 的 ALC 系统在其「运行设计域(即具有完整车道线的道路)」中进行了安全分析。这项研究正式发表在 USENIX Security 2021 上。这项工作研究了「产品级 L2 自动驾驶系统中的自动车道居中辅助系统(ALC,Automated Lane Centering)」的安全。L2 自动驾驶车通常利用深度神经网络(DNN)的车道检测来实现 ALC。由于 DNN 模型对对抗性样本攻击的脆弱性已被广泛报道,该研究首次在物理世界对抗性样本攻击下对最先进的基于 DNN 的 ALC 系统在其「运行设计域(即具有完整车道线的道路)」中进行了安全分析。研究发现,DNN 模型层面的漏洞可以导致整个 ALC 系统层面的攻击效果。研究人员设计了脏路补丁(DRP)攻击,即通过在车道上部署「添加了对抗样本攻击生成的路面污渍图案的道路补丁」便可误导 OpenPilot (开源的产品级驾驶员辅助系统) ALC 系统,并使车辆在 1 秒内就偏离其行驶车道,远低于驾驶员的平均接管反应时间(2.5 秒),造成严重交通危害。
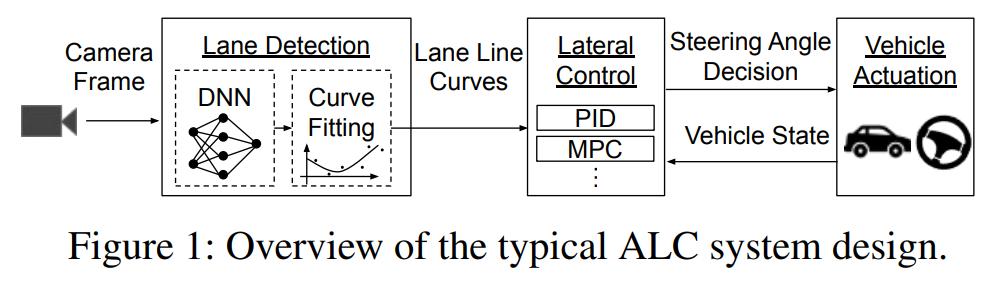
典型 ALC 系统设计概览。

本研究提出的脏路补丁(DRP)攻击。
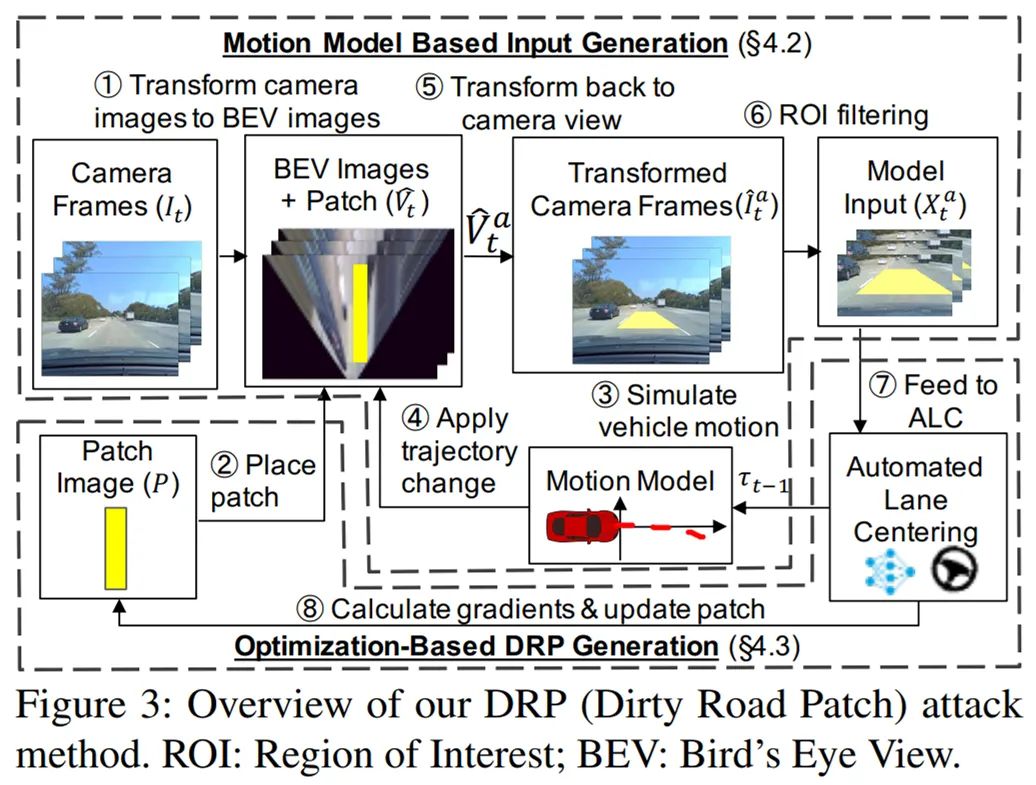
DRP 攻击方法示意图。
推荐:路面污渍也能用来攻击 L2 自动驾驶,基于 DNN 的 ALC 系统在物理世界攻击下的安全研究。
论文 5:Single Cortical Neurons as Deep Artificial Neural Networks
作者:DavidBeniaguev、IdanSegev、MichaelLondon
论文链接:https://www.sciencedirect.com/science/article/abs/pii/S0896627321005018
摘要:耶路撒冷希伯来大学的计算神经科学博士生 David Beniaguev、神经科学教授 Idan Segev 和副教授 Michael London 训练了一个人工深度神经网络来模拟生物神经元的计算。他们表示,一个深度神经网络需要 5 至 8 层互连神经元才能表征(或达到)单个生物神经元的复杂度。
人工神经元和生物神经元之间最基本的比较是它们如何处理传入的信息。这两种神经元都接收传入信号,并根据输入信息决定是否将信号发送给其他神经元。虽然人工神经元依赖简单的计算做出决定,但数十年的研究表明,生物神经元的这个过程要复杂得多。计算神经科学家使用输入 - 输出函数来模拟生物神经元树突接收到的输入与神经元发出信号之间的关系。
研究者让一个人工深度神经网络模仿输入 - 输出函数(生物神经元树突接收到的输入与神经元发出信号之间的关系),以确定其复杂性。他们首先对一种神经元的输入 - 输出函数进行了大规模模拟,这种神经元的顶部和底部有不同的树突分支,称为锥体神经元 ,来自大鼠的皮层。然后,他们将模拟结果输入到一个深度神经网络中,该神经网络每层最多有 256 个人工神经元。
接着,他们不断的增加层数,直到在模拟神经元的输入和输出之间达到毫秒级别 99% 的准确率。深度神经网络成功地预测了神经元的输入 - 输出函数的行为,所使用的层数至少有 5 层,但不超过 8 层。在大多数网络中,这相当于 1000 个人工神经元对应一个生物神经元。
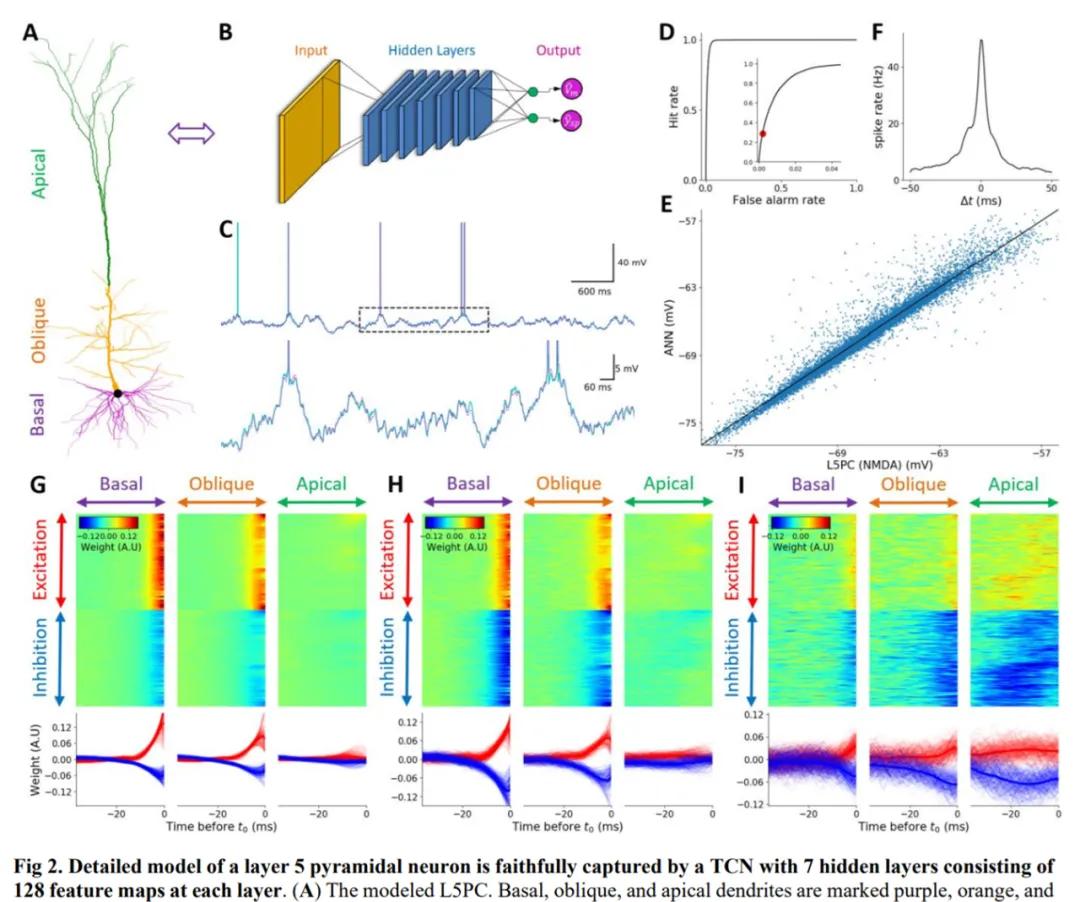
具有 7 个隐藏层、每层包含 128 个特征图的时间卷积网络(TCN)忠实地捕获了一个 L5PC (layer 5 pyramidal neuron)模型
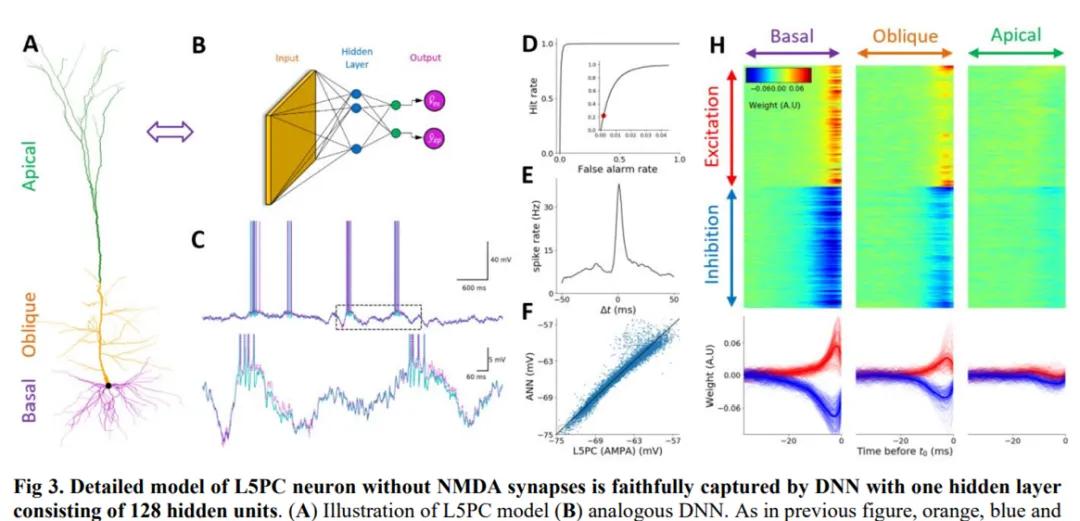
研究者展示了没有 N - 甲基天冬氨酸(NMDA)突触的 L5PC 神经元,它能够被具有单个隐藏层(包含 128 个隐藏单元)的深度神经网络忠实地捕获。其中 A 为 L5PC 模型示意图、B 为类比的深度神经网络。
推荐:研究发现一个神经元顶 5 到 8 层神经网络。
论文 6:Mutual gaze with a robot affects human neural activity and delays decision-making processes
作者:Marwen Belkaid、Kyveli Kompatsiari、Davide de Tommaso、Ingrid Zablith 和 Agnieszka Wykowska
论文链接:https://www.science.org/doi/10.1126/scirobotics.abc5044
摘要:在大多数日常情况下,人脑不仅需要参与决策,还需要参与预测他人的行为。凝视可以提供有关他人意图、目标和未来决定的信息。人类会注意别人的眼睛,当有人注视他们或注视环境中的特定事件或地点时,大脑的反应是非常强烈的。现在,研究人员注意到了人与机器人的此类互动。
该研究团队让 40 名参与者与机器人 iCub 玩一种策略游戏,以测量参与者的行为和神经活动,后者使用脑电图(EEG)。该游戏模拟两名驾驶员在汽车碰撞过程中相互接近,其结果取决于玩家是偏离还是继续直行。在这个游戏的实验中,两位玩家(即参与者和机器人)之间的桌子上有一个操纵游戏的机器。游戏中每个玩家各操纵一辆汽车。汽车相互靠近,在即将相撞时,游戏黑屏 5 秒,双方玩家都必须选择直行或偏离。
实验中最关键的一点是参与者被要求注视着机器人,而机器人 iCub 的视线则包括以下两种情况:直视参与者,即两位玩家相互凝视;iCub 向旁边看来避免眼神接触,即回避凝视。
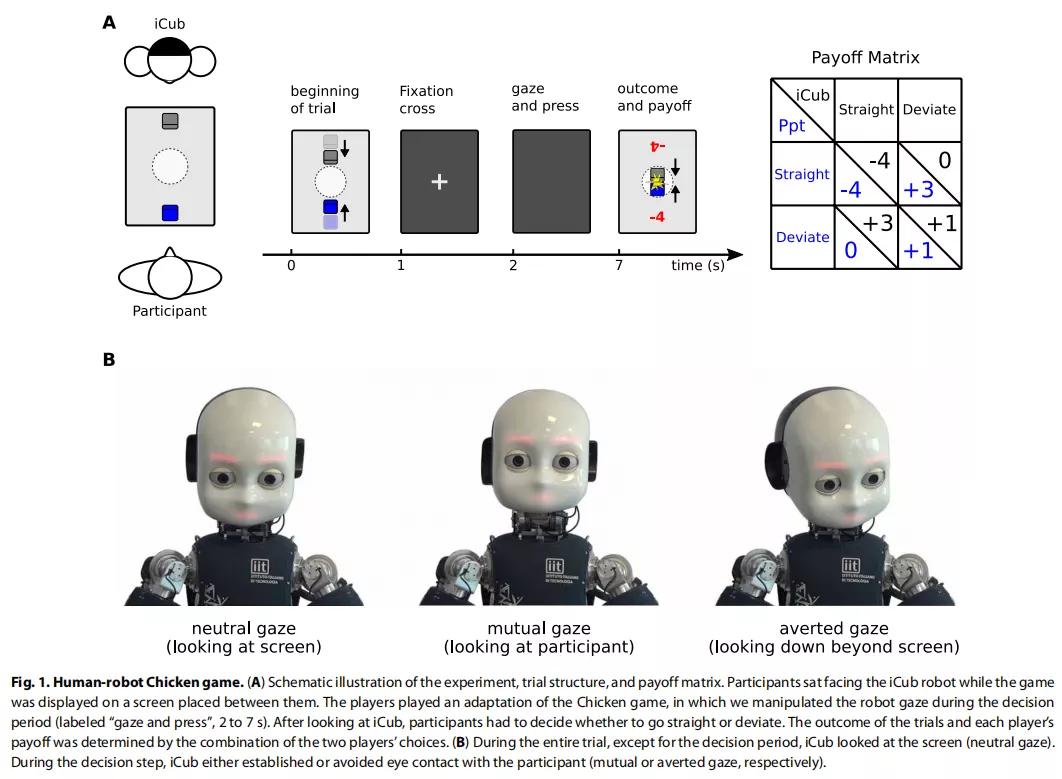
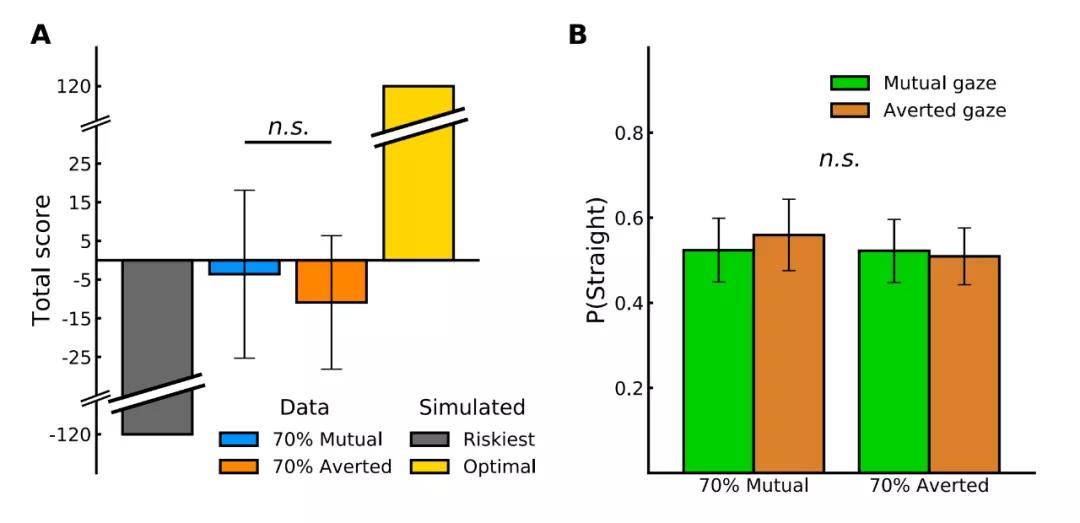
参加者的表现及回应时间。
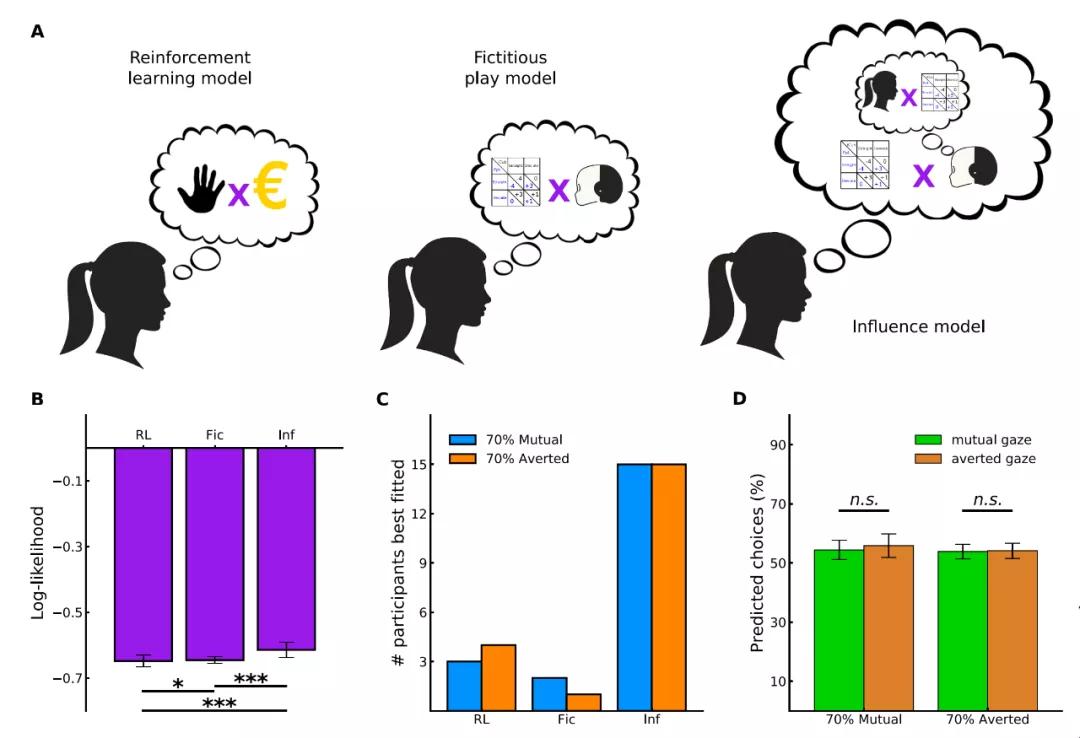
参与者对 iCub 行为推理的计算模型。
推荐:人与机器人对视导致决策变慢,研究登上 Science 子刊。
论文 7:EYES TELL ALL: IRREGULAR PUPIL SHAPES REVEAL GAN-GENERATED FACES
作者:Hui Guo、 Shu Hu、Xin Wang、Ming-Ching Chang、 Siwei Lyu
论文链接:https://arxiv.org/pdf/2109.00162.pdf
摘要:生成对抗网络 (GAN) 生成的高度逼真的人脸已被用作虚假社交媒体帐户的个人资料图像,并且在视觉上难以区分真实的人脸。在这项工作中,研究者展示了 GAN 生成的人脸可以通过不规则的瞳孔形状暴露出来。这种现象是由于 GAN 模型中缺乏生理学约束造成的。他们证明这种伪影广泛存在于高质量 GAN 生成的人脸中,并进一步描述了一种从两只眼睛中提取瞳孔并分析其形状以暴露 GAN 生成的人脸的自动方法。
结果表明,从两只眼睛中提取瞳孔并分析它们的形状,可以有效区分 GAN 生成的人脸和真实的人像照片。
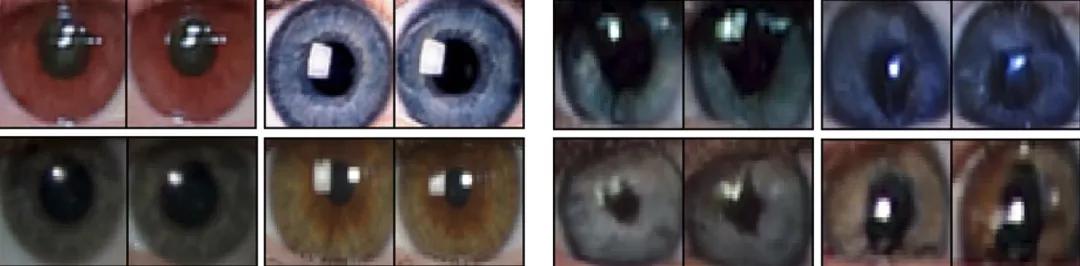
真实的人眼(左 4),GAN 生成的人眼(右 4)
推荐:瞳孔形状判断真假人脸。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. A Search Engine for Discovery of Biomedical Challenges and Directions. (from Eric Horvitz, Daniel S. Weld)
2. Few-Shot Table-to-Text Generation with Prototype Memory. (from Simon Baker)
3. Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization. (from Harry Jiannan Wang)
4. Fine-Grained Chemical Entity Typing with Multimodal Knowledge Representation. (from ChengXiang Zhai)
5. Boosting Search Engines with Interactive Agents. (from Thomas Hofmann)
6. Self-training Improves Pre-training for Few-shot Learning in Task-oriented Dialog Systems. (from Minlie Huang, Boi Faltings)
7. LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation. (from Minlie Huang)
8. RetroGAN: A Cyclic Post-Specialization System for Improving Out-of-Knowledge and Rare Word Representations. (from Cynthia Breazeal)
9. Analyzing and Mitigating Interference in Neural Architecture Search. (from Tie-Yan Liu)
10. ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding. (from Deng Cai)
本周 10 篇 CV 精选论文是:
1. On-target Adaptation. (from Evan Shelhamer, Trevor Darrell)
2. Transfer of Pretrained Model Weights Substantially Improves Semi-Supervised Image Classification. (from Eibe Frank, Bernhard Pfahringer)
3. Better Self-training for Image Classification through Self-supervision. (from Eibe Frank, Bernhard Pfahringer)
4. What You Can Learn by Staring at a Blank Wall. (from Antonio Torralba, William T. Freeman, Fredo Durand)
5. Stagewise Unsupervised Domain Adaptation with Adversarial Self-Training for Road Segmentation of Remote Sensing Images. (from Dacheng Tao)
6. AP-10K: A Benchmark for Animal Pose Estimation in the Wild. (from Dacheng Tao)
7. The Power of Points for Modeling Humans in Clothing. (from Michael J. Black)
8. Efficient Visual Recognition with Deep Neural Networks: A Survey on Recent Advances and New Directions. (from Jianbo Shi)
9. MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving. (from Kai Chen)
10. FOVEA: Foveated Image Magnification for Autonomous Navigation. (from Deva Ramanan)
本周 10 篇 ML 精选论文是:
1. Auto-Split: A General Framework of Collaborative Edge-Cloud AI. (from Jian Pei)
2. Semi-Supervised Learning using Siamese Networks. (from Eibe Frank, Bernhard Pfahringer)
3. Finite-time System Identification and Adaptive Control in Autoregressive Exogenous Systems. (from Babak Hassibi)
4. Representation Memorization for Fast Learning New Knowledge without Forgetting. (from Boi Faltings)
5. Excess Capacity and Backdoor Poisoning. (from Avrim Blum)
6. APS: Active Pretraining with Successor Features. (from Pieter Abbeel)
7. Parallel Machine Learning for Forecasting the Dynamics of Complex Networks. (from Michelle Girvan)
8. Designing Rotationally Invariant Neural Networks from PDEs and Variational Methods. (from Joachim Weickert)
9. Disrupting Adversarial Transferability in Deep Neural Networks. (from Ge Wang)
10. CrypTen: Secure Multi-Party Computation Meets Machine Learning. (from Laurens van der Maaten)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《7 Papers & Radios | 矩阵乘法无需相乘,速度提升100倍;一个神经元顶5到8层神经网络》