AI专用领域之一:声音、相机陷阱用于野生动物研究和保护

原创 Synced 机器之心
机器之心分析师网络
作者:Jiying
编辑:Joni
在这篇文章中以两篇文章为基础,分别讨论了声音、相机陷阱(camera traps)是如何实现野生动物监测的。此外,最后一篇文章还讨论了如何利用人工智能技术辅助解决野生动物偷猎(wildlife poaching)的问题,即对偷猎者轨迹的预测问题。
0 引言
近年来,生物多样性危机,即世界范围内的物种损失和生态系统的破坏问题,正在全球范围内持续加速,生物多样性正在迅速减少。例如,许多物种如老虎和犀牛,由于非法采伐(即偷猎)而面临灭绝的危险。研究动物的分布、运动和行为对解决环境挑战至关重要,如疾病的传播、入侵物种、气候和土地使用的变化等等。因此,迫切需要部署可扩展和具有成本效益的监测技术,以更好地模拟和了解野生动物及其居住的环境。
随着人工智能的快速发展,人工智能技术也被引入到野生动物研究和保护中。哈佛大学、谷歌、英特尔、DeepMind,以及国内的快手、阿里等等众多研究机构、企业,甚至包括一些政府机构,都已经投入到了这项工作中,且研发和部署了相应的产品。我们在这篇文章中以两篇文章为基础,分别讨论了声音、相机陷阱(camera traps)是如何实现野生动物监测的。此外,最后一篇文章还讨论了如何利用人工智能技术辅助解决野生动物偷猎(wildlife poaching)的问题,即对偷猎者轨迹的预测问题。
1 利用深度信息进行野生动物监测 [8]

相机陷阱(Camera traps)是生物学特别是生物多样性研究中的一个成熟工具。不过,尽管相机陷阱能够提供关于场景的丰富的信息,同时促进了传统人工生态学方法的自动化,但是包含深度估计信息(Depth estimation)的相机陷阱并没有得到广泛的部署和应用。本文提出了一种基于深度相机陷阱的自动方法,利用深度估计来探测和识别动物。为了检测和识别单个动物,作者提出了一种新的方法 D-Mask R-CNN 用于实例分割。D-Mask R-CNN 是一种基于深度学习的技术,用于检测和划分图像或视频片段中出现的每个不同的兴趣对象。
1.1 关于 Camera traps 的背景知识
相机陷阱是一项连续监测动物的技术。具体指使用动作传感器、红外探测器或其他光束作为触发机关的遥控相机。它常被用来拍摄摄影师不容易直接拍得的画面。相机陷阱能够提供可用于探测动物的线索信息(参见图 1(顶部)),以实现在动物群中区分单个动物(参见图 1(底部)),在观察环境中定位动物以及促进生态学研究的自动化发展,如估计种群密度等。不过 Camera traps 并没有在野外广泛部署[1]。
在计算机视觉中,距离测量由图像或视频片段中的深度通道来表示。给定一个灰度图像作为相机陷阱的视觉输出,例如,在夜间或黄昏使用红外摄像机监测野生动物(参见图 1(左上)),深度通道捕获距离信息(参见图 1(右上))。深度通道通常以热图的形式呈现,其中蓝色表征的距离最高,红色表征的距离最低。带有深度通道的彩色图像被称为 RGB-D 图像,其中图像的颜色成分由红、绿、蓝三条通道编码,而第四条通道显示深度信息(参见图 1(底部))。

图 1. 深度信息支持对动物进行更可靠的检测,也支持区分成群结队的单个动物。深度信息使用热图进行编码,其中表征距离最高的是蓝色,最低的是红色
立体视觉是获取深度信息的主要方法之一。给定两台相机,在水平方向上相互移动,观察到的场景的两个不同的视角被用来生成观察到的场景物体的深度,其方式类似于人类的立体视觉。本文提出了一种基于深度相机陷阱的自动动物探测方法,利用深度估计来探测和识别动物。为了检测和识别单个动物,作者提出了一种新的方法即所谓的实例分割,这是一种基于深度学习的技术,用于检测和划分图像或视频片段中出现的兴趣对象。
1.2 方法介绍
从人工智能的角度分析,本文是使用的方法是一个基于 Mask R-CNN 的架构[2],将实例分割应用于 RGB-D 图像,作者称之为深度掩码 R-CNN(Depth Mask R-CNN)或简称 D-Mask R-CNN,它利用额外的深度信息来改进边界框和分割掩码的预测,以检测和定位物体实例以及识别它们。D-Mask R-CNN 的具体架构见图 2。
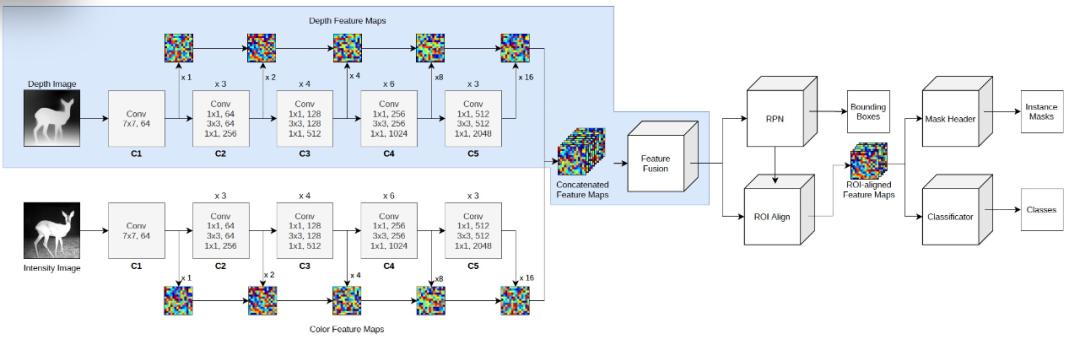
图 2. D-Mask R-CNN 的具体架构
深度骨干网(Depth backbone)。本文所使用的完整的架构是建立在 detectron2 框架中的 Mask R-CNN 实现之上的 [3]。除了传统的彩色图像骨干网(color image backbone),即在 ImageNet[4] 上预训练的 ResNet-50 模型 [5] 之外,作者还采用了几乎相同的 backbone 来处理深度通道,即一个深度骨干网。
初始化深度骨干网(Initialization of depth backbone)。深度骨干网的初始化参数与彩色骨干网相同,即网络权重,但第一层除外。在这一层中,权重预计是三通道的 RGB 彩色图像,而深度通道只是一维的。作者在图像骨干网的第一个权重维度上取平均值,以获得深度骨干网第一层的初始权重。在训练过程中,深度骨干网的权重一定会出现与彩色骨干网的权重相背离的现象,也就是说,在两个骨干网之间不采用权重共享的处理方式。另外,也可以随机地初始化深度骨干网的权重。
彩色和深度特征融合(Fusion of color and depth features)。当输入通过两个骨干网传播时,在不同的尺度上提取深度为 256 的中间特征图,与在标准 Mask R-CNN 的单一骨干网的情况下一样。然后,将两个骨干网的特征图在每个层次(深度 512)上串联起来,并通过一个内核大小为 33 的单一卷积层(每层有一个专门的卷积层),将串联的特征图的深度从 512 降到 256。作者称这种操作为特征融合(feature fusion),因为它融合了所有三个彩色通道和深度通道的特征信息。虽然本文使用的 D-Mask R-CNN 架构与 [6] 中的方法类似,都是采用两个独立的骨干来处理彩色和深度通道,但作者在选择从两个骨干网获得特征的处理过程并没有对网络架构施加事先的限制。
综合彩色和深度特征的处理(Processing of consolidated color and depth features)。将上一步融合处理后得到的特征图输入区域建议网络(region proposal network,RPN),以得到可能的实例边界。然后,通过兴趣区域(ROI)对齐,将特征图与每个边界对齐。然后将这些对齐的特征图交给掩码头和分类器,分别计算出实例掩码和类别预测。
1.3 所使用的数据情况
正如在前文中提到的,由于 Camera traps 并没有广泛部署,作者使用一个合成数据库评估了本文提出的 D-Mask R-CNN。该数据库包括了通过渲染合成野生动物场景产生的 RGB-D 视频片段。为了提供一个概念验证的应用,作者在一个动物园里安装了一个 RGB-D Camera traps,并在捕获的 RGB-D 视频片段上评估了 D-Mask R-CNN。
1.3.1 合成数据
在实验数据生成过程中,每只动物都有一个相关的运行动画,使用该运行动画并在时间上随机化,以从所有可能的运动状态中取样。作者还对摄像机和照明的角度、高度和视野进行随机化处理,同时保持两者大致指向同一方向和同一地点。然后使用 Blender 软件包 [7] 渲染灰度、深度、类和实例图像。作者渲染灰度图像而不是彩色图像,以模拟夜间或黎明时分红外传感器产生灰度图像的 Camera traps 结果。作者最终生成了描述四个动物类别的 RGB-D 视频片段:鹿、野猪、野兔和狐狸。图 3 给出了合成数据库的视频片段中的两帧。表 1 给出了合成数据库的概况。

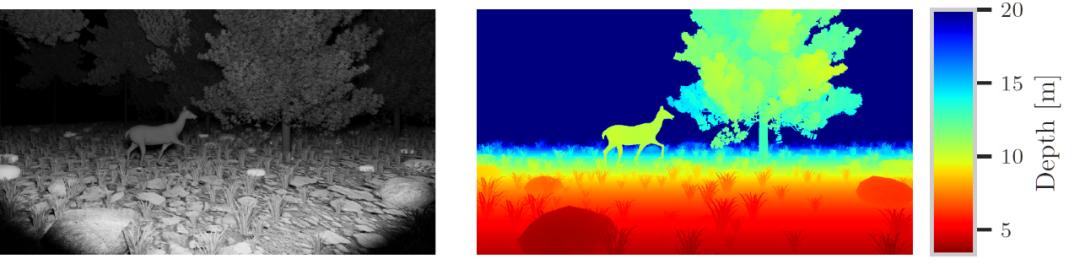
图 3. 合成数据库的视频片段的两帧。左:强度,右:深度

表 1. 合成数据库的统计数据
1.3.2 Camera traps 数据库
作者采用低成本、现成的组件设计并建造了一个 RGB-D Camera traps,特别强调了在不同照明条件下的多功能性,具体使用了 Intel® RealSense™ D435。作为一个主动红外立体相机(即两台相机与一个额外的照明源配对),它比纯结构光相机能在更广泛的照明条件下发挥作用,因为纯结构光相机在明亮的场景中往往无法找到对应的数据。图 4 给出了 RGB-D Camera traps 的示例。作者对 RGB-D Camera traps 的组件进行了详细介绍,我们在这里不再赘述。

图 4. 构建 RGB-D Camera traps。(A): Intel®RealSense™ D435, (B): NVIDIA® Jetson Nano™ Developer Kit, (C): 被动红外传感器(PIR,在此图片中不直接可见),(D): 用于控制的 L298N,(E): 红外线灯用于夜间照明,(F): tp-link Archer T4U 无线网络适配器
1.4 实验分析
作者使用合成数据库评估了 D-Mask R-CNN,该数据库包括了通过渲染合成野生动物场景产生的 RGB-D 视频片段。作者采用 COCO 评价指标的一个子集作为评估指标:10 IoU(intersection over union)水平的平均精度(Average Precision,AP),IoU 阈值为 50% 时的 AP(AP_50%),IoU 阈值为 75% 时的 AP(AP_75%)以及观察到的四个不同动物类别的 AP 得分。作者将 D-Mask R-CNN 的结果得分与文献 [2] 中的经典 Mask R-CNN 方法(即表 4 中使用和不使用深度信息的 Mask R-CNN)进行比较。D-Mask R-CNN 在所有指标上明显优于经典的 Mask R-CNN。
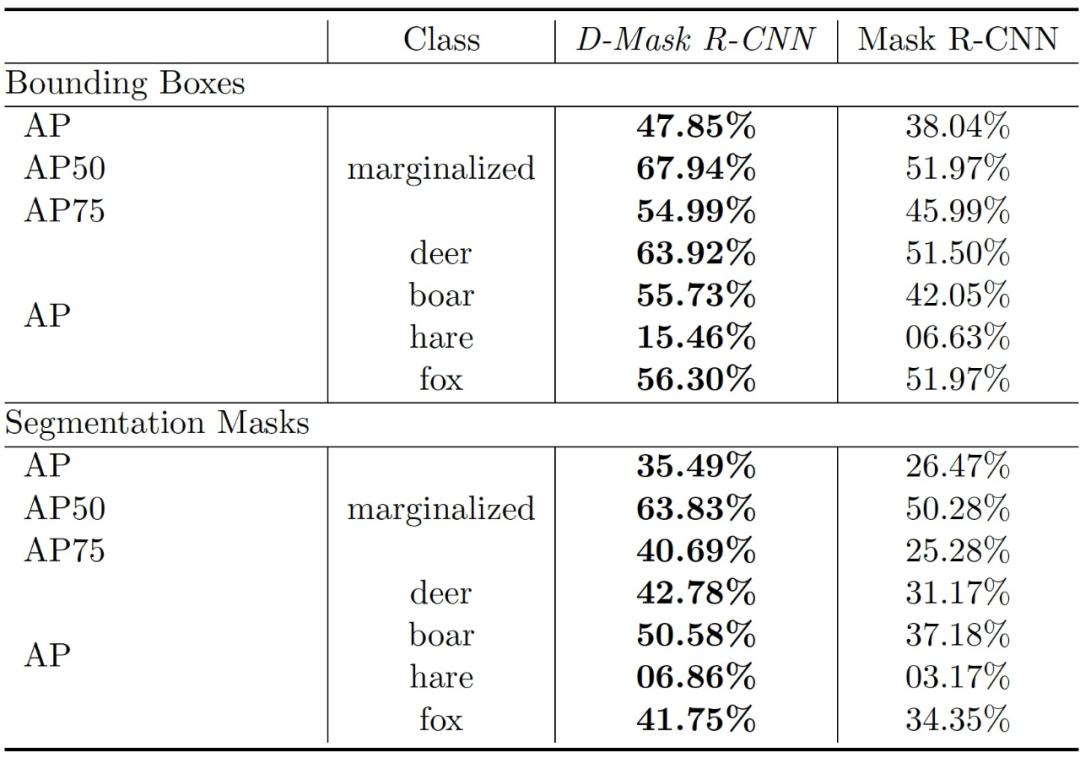
表 2. D-Mask R-CNN 在合成数据库上对 bounding box 预测和 segmentation mask 预测的动物检测任务的 AP 分数
为了提供一个概念验证的应用,作者还将 D-Mask R-CNN 应用于安装在 Lindenthal Zoo 的 RGB-D camera trap 所拍摄的 RGB-D 视频片段上,并对其进行了评估,评估只考虑到了观察到的鹿。图 5 给出了两个示范性结果。

图 5. RGB-D camera trap 数据库的两帧视频片段与边界框预测和 D-Mask R-CNN 的分割掩码预测相叠加。左:强度,右:深度
2 利用声学监测和深度学习建立动物生物多样性模型[9]

2.1 背景知识
在监测野生动物和栖息地健康时,声音讯号也被认为是一种重要的途径。声学传感器为野生动物保护主义者和研究人员提供了不受干扰地接触大自然的机会。这些传感器提供了重要的生态学数据,使生态系统内的丰富度、分布和动物行为信息能够被用于建立保护战略模型。典型的分析类型包括占用或分布模型、密度估计和数量趋势分析。我们在上一篇文章中提到的 camera traps 一直是此类分析的首选技术,不过,近年来声音监测已被用于扩展生物多样性研究。音频提供了一个与图像不同的感官维度,它还有一个额外的好处,那就是可以穿越更大的地理边界,并且在许多难以到达的环境中较少受到视野和植被限制的影响。
声学传感器的地理覆盖范围很大,对人口稠密环境的影响较小,因此,在生态学和保护中越来越多应用声学监测,现在已经认为它是了解动物对环境变化反应的一个关键组成部分。camera traps 对检测大型动物非常有用,当它们与被动声学监测相结合时,可以识别更广泛的动物物种,包括不容易被 camera traps 发现的非常小的动物。当单独使用声学传感器时,它们可以被长期部署(通常是几个月)以模拟一个特定的生态系统。
声学传感器产生连续的时间序列数据,通常包括与不同信号发生器有关的频率组合。不同的动物物种使用不同的声学特征和频率产生声音。因此,为了获得所需的信息,有必要将信号与噪音分开。最常见的提取频率特征的方法是快速傅里叶变换(FFT)。本文在声学监测管道中实施 FFT 以生成频谱图,这些频谱图以前被用来对动物叫声进行视觉分类和标记。探测包括在录音中定位感兴趣的特定声音,同时将每个声音归入一个特定的类别,如物种类型。这种形式的分析是劳动密集型的,而且往往会因保护者的经验而产生偏差。图 6 给出了本文所使用的数据库中的一个频谱图实例(家雀)。
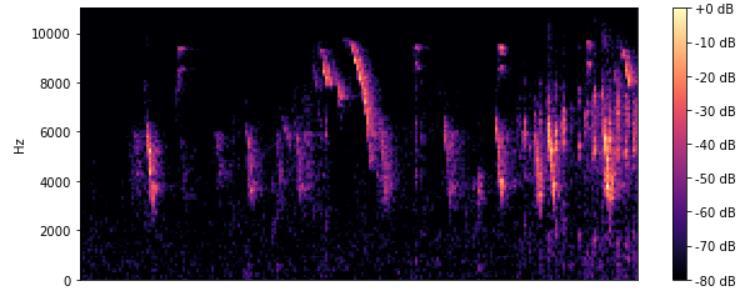
图 6. 一只家雀的频谱图
本文提出了一个自动声音分类方法,适用于大规模的声学调查和被动监测项目。在本文给出的分析和实验中,该方法能够对不同的鸟类声音进行分类,同时,作者提出在生成特定物种的声学分类模型后,也可以将其应用到其他类型的动物分类中。作者选择鸟类是因为鸟类被认为是评估栖息地健康和建立生物多样性模型时的重要物种。
2.2 数据分析和方法介绍
2.2.1 数据分析
本文使用的音频数据集包含了在英国发现的五种不同的鸟类(小斑啄木鸟、欧亚斑鸠、大山雀、家雀和普通木鸽),可以通过 Xeno-Canto 网站访问(https://www.xeno-canto.org/ )。音频文件的长度是可变的。为了使输入标准化,音频文件被修剪到重新编码的前 15 秒。图 7 给出了数据集的类别分布。其中,存在一个轻微的类别不平衡,但这并不会影响模型的整体性能。
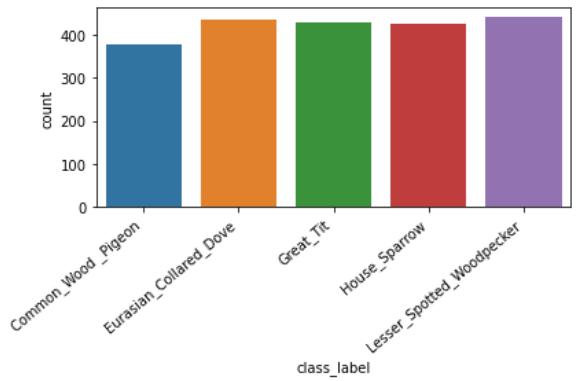
图 7. 鸟类物种的分类计数
数据集中的每个音频文件的采样频率为 44.1kHz。图 8 给出了数据集中每个类别的波形示例。
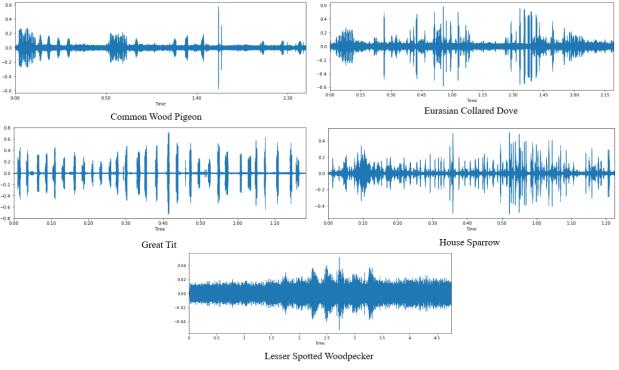
图 8. 波形示例
如图 7 所示,该数据集包含每个鸟类物种的有限数量的音频文件。此外,获得的数据由目标类别的前景和背景噪声组成,反映了真实世界的栖息地情况。所有获得的数据都是众包的(crowd source),并通过 Xeno-Canto 网站申请。
数据集拥有宽泛的比特深度(-24440 到 21707),作者使用 Librosa 负载函数对其进行了归一化处理。这是通过在给定的比特深度下取最小和最大的振幅值来实现的,最终得到一个在 - 1 和 1 之间的标准化范围(-0.7461247 到 0.66244507)。由于数据集包含以立体声和单声道录制的音频文件,作者将它们进行合并处理以使其统一,具体是通过对两个通道的数值进行平均来实现的。下图9给出了顶部的原始音频文件(立体声)和底部的转换(单声道)文件。
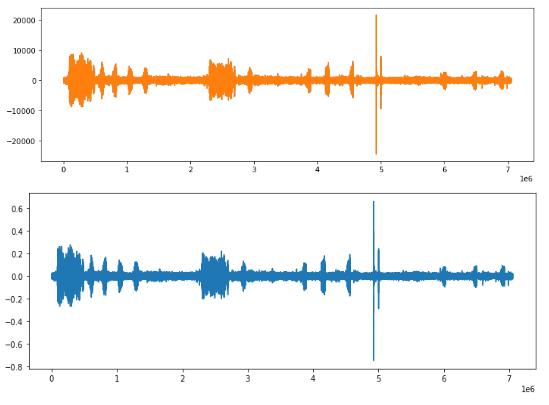
图 9. 立体声到单声道的转换
然后,作者使用 MFCC 从原始音频信号中提取特征。人类的听觉系统并不遵循线性尺度。因此,对于每一个实际频率为 f 的音,以赫兹为单位,主观的音调被映射到 Mel scale 上。该过程首先将音频样本分割成 40 毫秒的小帧,然后使用快速傅里叶变换(FFT)将 N 个样本从时域转换到频域,定义为下式(2.1):
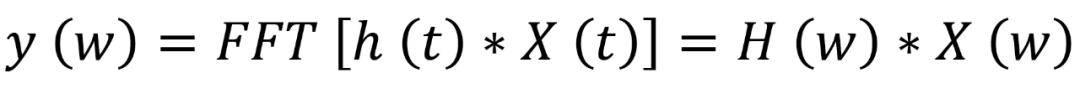
其中,X(w)、H(w)和 Y(w)分别是 X(t)、H(t)和 Y(t)的傅里叶变换。将输入信号分离成多个分量的 bank filters 以计算滤波器分量的加权和,从而确保输出接近于 Mel scale。每个滤波器的输出是其滤波后的谱成分的总和。Mel-frequency scale 定义由以下公式(2.2)给出,其中 f 是频率,单位为 Hz:
使用离散余弦变换(DCT)将对数 Mel 谱(log Mel spectrum)转换为时域。MFCC 窗口大小被设定为 80,以捕捉更多的频率和时间特征。一旦提取了 MFCC 特征,就可以继续使用 90/10 的比例对数据集进行分割(训练、测试)。
在这项研究中,作者使用多层感知器(MLP)来完成分类任务。该网络使用 ReLu 激活函数构建。MLP 的过滤器大小为 2,使用 Back propagation 作为学习算法,Adam 作为优化器。前三层 dropout 值为 50%,以提高概括性和减少过拟合。前三层由 256 个节点组成,而最后一层等于数据集中的类别的数量。模型概要见图 10。

图 10. 模型概要
MLP 训练超过 100 个 epochs,作者通过实验验证 100 个 epochs 可以令模型收敛而不过度拟合。本文使用敏感性、特异性、精确性和准确率来衡量模型质量。灵敏度描述的是真正的阳性率,而特异性描述的是真正的阴性率。精度用于显示正确分类的物种数量。训练好的模型使用 TensorFlow 2.2 托管,并通过作者开发的面向公众的网站提供服务(www.conservationai.co.uk )。作者使用 CUDA 11 和 cuDNN 7.6.5 提高学习速度。使用一台三星 S10 来记录花园鸟类,并使用 SMTP 将获取到的音频自动上传到平台进行分类。图 11 给出了整个工作过程,从传感器开始,最终展示在面向公众的动物保护人工智能网站中(如图 12 所示)。
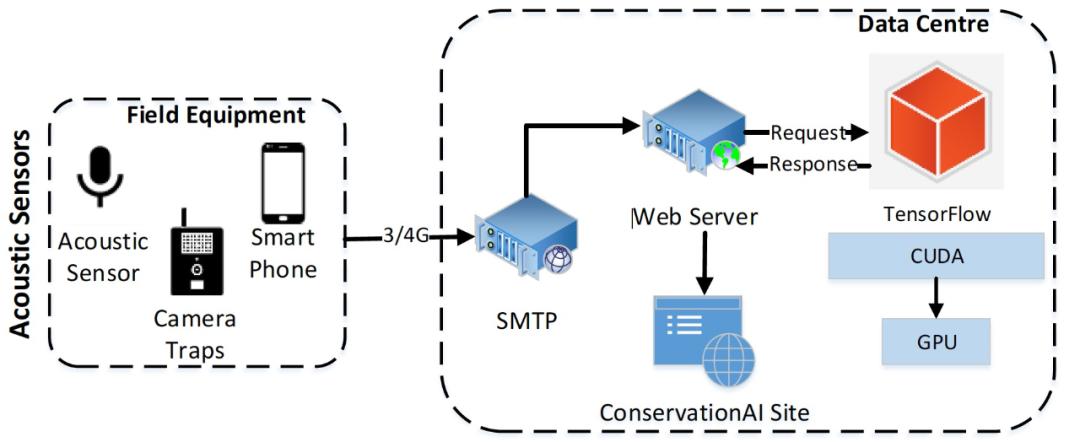
图 11. 端到端的工作过程
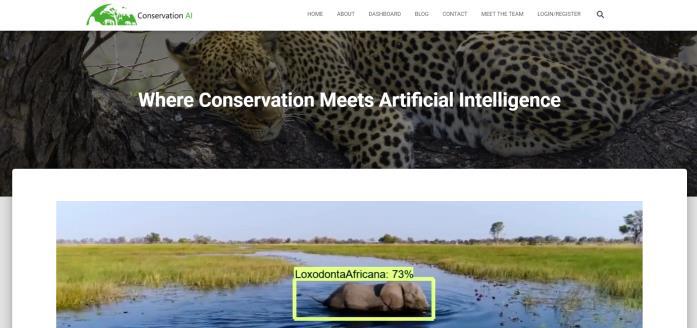
图 12. 动物保护人工智能网站
2.3 实验介绍
图 13 给出了模型训练期间使用测试和验证数据的损失。该图显示,在训练过程中没有出现过拟合现象,而且 dropout 有助于模型的正则化。尽管模型在训练的早期就实现了收敛,但在整个 100 个 epochs 过程中,损失显示出持续的下降趋势。
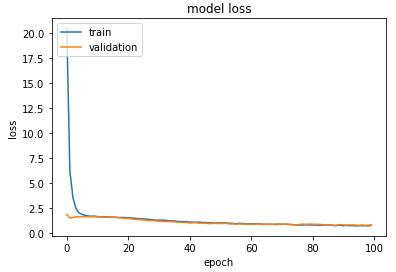
图 13. 训练和验证损失
该模型对训练数据的准确率达到 0.83,对测试数据的准确率为 0.74。图 14 给出了训练和验证数据在 100 个 epochs 中的准确性。结果表明,模型的准确性在训练结束时趋于平缓,并表明模型收敛所需的 epoch 数是足够的。通过增加 epoch 数量能够改进的准确度很小,并可能导致过度拟合。

图 14. 训练阶段的训练和验证准确度
此外,作者使用一台三星 S10 手机在一棵有筑巢的普通林鸽的树下记录现实环境中的鸟类音频。音频共记录了三分钟,并上传到平台进行分类。在部署过程中,作者最终检测到了 8 个单独的鸟鸣声。8 个分类中的每一个都返回了对普通林鸽的预测,平均置信值为 0.71。
2.4 关于引入声音信号的讨论
最后,作者对本文提出的方法进行了讨论,并强调了该方法的优势。首先,通过本文的方法减少了训练和推理模型所需的计算量,这使得动物保护者可以在低成本的前提下应用该方法,这就与传统的方法形成了鲜明的对比。经典的用于鸟类音频的分类的 CNN 方法,一般都对数据进行处理后才能应用,例如只包括前景噪声,这种音频不能够真实反映动物在其自然栖息地的情况。在本文方法中,使用 MFCC 可以在包含目标物种的背景和前景噪声的更现实的数据集上训练模型。这使得该方法能够利用更广泛的数据集。原文中给出的初步结果是非常好的,在此基础上,作者设想,如果能够收集更大的数据集,该方法可能会有更好的表现。
此外,通过对模型部署过程的分析我们可知,该系统可以以实用的方式用于对鸟类自然栖息地内声音的自动分类。在本文的部署过程中使用的是三星 S10,不过更广泛和普遍的声学传感器都可以被集成到系统中以达到同样的效果。
声学数据是量化生物多样性和物种密度的重要工具,也是对它们所处环境的整体声学健康状况的评估。直到近些年,获取数据、处理和对数据进行分类仍然主要依靠手工过程来实现。尽管在保护领域内的音频自动分类方面已经取得了一些进展,但仍然存在很多挑战,阻碍了其广泛采用。本文提出的解决方案克服了许多现有方法中存在的计算和数据集的限制。这有助于为自动声学分类提供一个可扩展的、具有较好成本效益的解决方案。
3 用于保护野生动物的反盗猎预测工具[10]

野生动物保护是一个全球性的问题。许多物种,如老虎和犀牛,由于非法采伐(即偷猎)正在面临灭绝的危险,已经威胁到自然生态系统的运作,损害了当地和国家的经济,甚至由于偷猎者的利润流向恐怖组织,演变成为一个国际安全问题。为了防止偷猎野生动物,保护组织试图用训练有素的护林员来保护野生动物园。在每个时间段(如一个月内),护林员在野生动物园范围内进行巡逻,通过抓捕偷猎者或清除偷猎者布置的陷阱的方式来防止偷猎者捕获动物。例如,可以利用护林员在巡逻过程中收集到的偷猎迹象信息和其他域特征来预测偷猎者的行为。学习偷猎者的行为以及预测偷猎者经常去的偷猎地点 / 位置,对于护林员完成有效的巡逻至关重要。
保护野生动物的安全机构非常需要能够分析、模拟和预测偷猎者行为的模型。这种模型能够帮助安全机构对形势进行判断,并制定巡逻计划。此外,研究机构还发现利用这种模型生成的巡逻规划工具也是非常有效的。受到 “防御者 - 攻击者 Stackelberg Security Game(SSG)” 在基础设施安全领域中的应用启发,前期已有工作将 SSG 引入野生动物保护中。在东南亚地区部署了一种基于 SSG 的巡逻决策辅助工具,称为 PAWS[11]。尽管 PAWS 的应用很成功,但众所周知它还存在几个局限性。首先,PAWS 依赖于现有的反面行为模型,即主观效用定量反应(Subjective Utility Quantal Response,SUQR)[8],它有几个限制性假设:(a) 所有偷猎的迹象都是护林员完全可以观察到的;(b) 偷猎者在一个时间段的活动与他们在以前或未来时间段的活动无关;(c)偷猎者的数量是已知的。其次,由于 SUQR 在建模时只依赖三或四个域的属性,它无法详细分析环境和地形特征对偷猎者行为的影响,因此文献中一直缺乏对真实世界数据的分析。第三,针对新的复杂攻击模型需要得到新的巡逻生成算法,以改进目前 PAWS 中使用的算法。
本文提出一种 CAPTURE 工具,目的是解决 PAWS 存在的上述问题。第一 ,CAPTURE 能够解决 SUQR 在模拟对手行为方面的局限性。具体来说,CAPTURE 引入了一个新的行为模型,该模型考虑了护林员对偷猎轨迹的检测存在不完美检测的情况。此外,作者将偷猎者的行为对其过去活动的依赖性纳入预测偷猎者行为的考虑范畴。然后,作者采用逻辑模型来制定新模型的两个组成部分。这使得我们能够捕捉到攻击者的总体行为,而不需要已知的偷猎者的数量。最后,CAPTURE 在分析偷猎者的行为时,除了 SUQR 中使用的三 / 四个特征外,还考虑了更丰富的域特征。第二,作者提供了两个新的启发式方法来降低 CAPTURE 中学习对手模型的计算成本,即参数分离和目标抽象。第一种启发式方法将模型参数集分成独立的子集,然后在固定其他子集的值的同时,迭代学习这些子集的参数。这种启发式方法将学习过程分解为不太复杂的学习组件,这有助于在不损失准确性的情况下加快学习过程。目标抽象的第二种启发式方法是利用野生动物领域的连续空间结构,从森林面积的粗离散化开始学习,逐渐使用更细的离散化而不是直接从最详细的表示开始,进而改善整体运行时间。CAPTURE 的第三个贡献是在新的行为模型下计算护林员的最佳巡逻计划。具体来说,作者为单步 / 多步巡逻计划提供了一种新的博弈论算法,实现在多个时间步骤中递归探索偷猎者的行动(遵循 CAPTURE 模型)。
3.1 行为学习方法
目前,世界各地的野生动物保护区域内设置的安全机构已经收集了大量与保卫者(巡逻者)和对手(偷猎者)之间的互动有关的数据。本文工作聚焦于 QENP[12],通过与野生动物保护协会(the Wildlife Conservation Society,WCS)和乌干达野生动物管理局(Uganda Wildlife Authority,UWA)合作,作者已经获得了 12 年间护林员收集的数据。在 CAPTURE 中,作者引入了一个新的分层行为模型来预测野生动物领域的偷猎者的行为,同时考虑到了护林员不完善的观察轨迹带来的挑战。总的来说,新模型由两层组成。一层是偷猎者攻击每个目标的概率模型,其中包括偷猎者行为的时间效应。另一层预测的是,在给定偷猎者攻击目标的情况下,护林员在该目标处检测到任何偷猎信号的条件概率。然后,将这两层整合起来以预测护林员的最终观察结果。在本文的模型中,作者还引入了护林员巡逻对这两层的影响,即偷猎者如何根据护林员的巡逻来调整他们的行为,以及护林员的巡逻如何决定护林员对偷猎迹象的可探测性。此外,在推理偷猎者的未来行动时考虑了偷猎者过去的活动,还引入不同的域特征来预测攻击概率或检测概率或两者。
令 T 表示时间步骤数目,N 为目标数量,K 为域特征数量。在每个时间步骤 t,每个目标 i 对应特征集合 x_t,i={(x_t,i)^k}。令 c_t,i 表示护林员在 (t,i) 的覆盖概率。当护林员在时间步骤 t 巡逻目标 i 时,他们的观察结果记为 o_t,i,取值范围为 {-1, 0, 1}。其中,o_t,i=1 表征有偷猎迹象,o_t,i=0 表征护林员没有观察到,o_t,i=-1 表征没有偷猎迹象。此外,定义 a_t,i 表征(t, i) 处的实际行动,而这一值是不为护林员所知的。其中,a_t,i=1 表征有偷猎,a_t,i=0 表征没有偷猎。此外,作者做了一个合理性假设,即不存在假阳性观察,也就是说,如果护林员在某个目标处发现了任何偷猎的迹象,那么偷猎者确实袭击了该目标,下式(3.1)、(3.2)。
图 15 给出了模型的图形化展示,其中的有向边表示模型中各元素之间的依赖关系。其中的灰色节点指的是护林员的已知要素,如域特征、护林员的覆盖范围和观察结果,而白色节点代表未知要素,如偷猎者的实际行动。(λ,w)为模型中的参数。
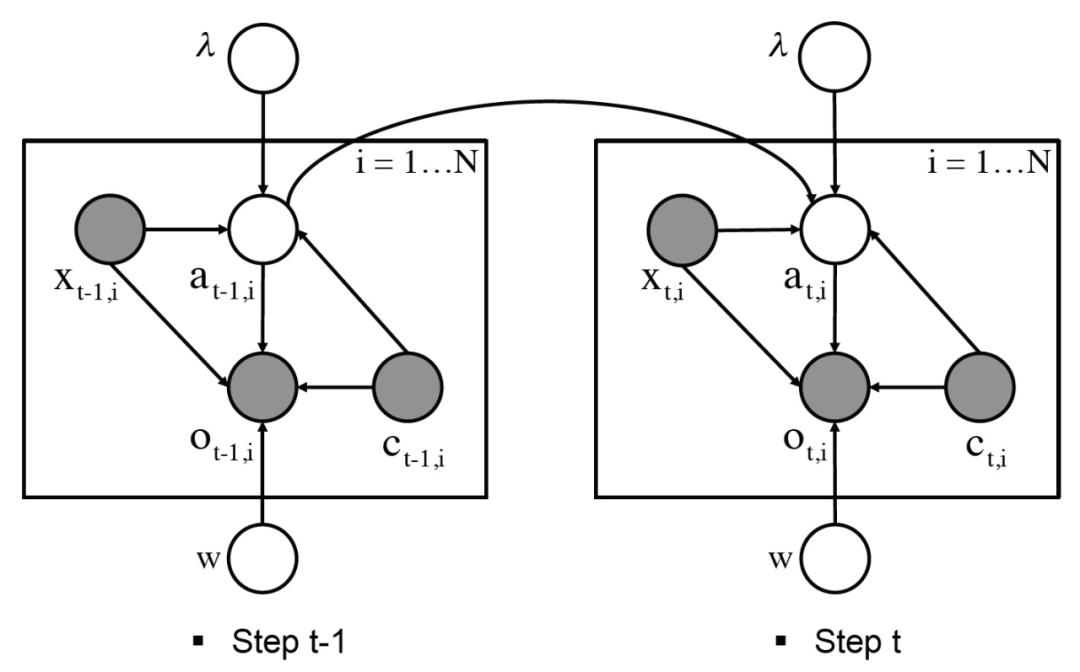
图 15.CAPTURE 建模元素之间的依赖关系
CAPTURE 图形化模型与以前的行为博弈理论模型(如 QR/SUQR)以及类似的保护生物学模型相比,都有很大的进步。首先,与 SUQR/QR 不同(SUQR/QR 认为偷猎者的行为在不同的时间步骤之间是独立的),本文假设偷猎者在 a_t,i 的行动取决于偷猎者在 a_t-1,i 的行动和护林员的巡逻策略 c_t,i。这是因为偷猎者可能倾向于回到他们以前偷袭过的地区。第二,CAPTURE 考虑了更丰富的域特征 x_t,i={(x_t,i)^k},这些特征在早期没有被考虑但在本文模型中与我们的域是相关的,例如,坡度和栖息地。第三,CAPTURE 对域的观测不确定性进行建模。最后,本文采用 logistic 模型来预测偷猎者的行为,与 SUQR/QR 相比,这个模型的一个优点是它不假设已知的攻击者数量,而是独立地模拟每个目标的攻击概率。给定时间步骤 (t-1,i) 的偷袭者的真实行动 a_t-1,i、护林员的覆盖概率 c_t,i、域特征 x_t,i,目标是预测偷袭者的攻击概率,式(3.3):
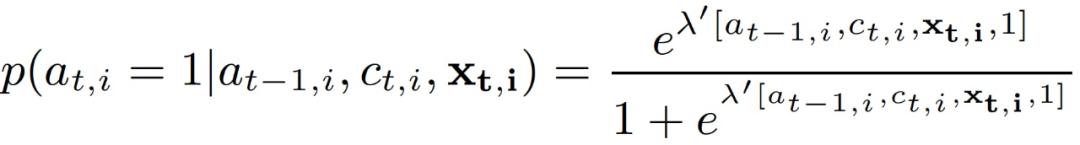
其中λ为(K+3)x1 的参数向量,其衡量所有因素对偷猎者决定影响的重要性。
如果攻击者在 (t,i) 进行攻击,我们预测护林员能发现任何偷猎迹象的概率如式(3.4):
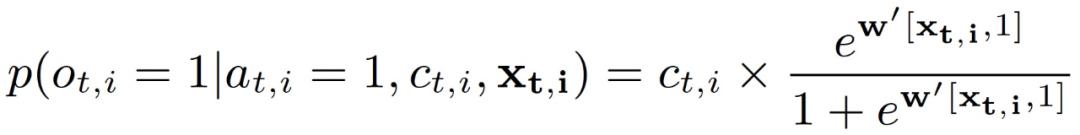
其中第一项是护林员在 (t, i) 出现的概率,第二项表示护林员在 (t,i) 巡逻时能发现偷猎迹象的概率。权重 w 表征域特征在影响护林员发现偷猎迹象的概率方面的重要性。后续讨论中为了便于介绍,作者在公式中省略了域特征 x_t,i。
考虑到未观察到的变量 a = {a_t,i},作者使用标准的期望最大化(EM)方法来估计(λ,w)。具体参数估计过程我们不再赘述,感兴趣的读者可以阅读原文。
3.2 巡逻计划
生成 (λ,w) 后,CAPTURE 的下一个任务是计算护林员在接下来的时间步骤中的最佳巡逻路径策略。作者考虑了两种情况:1)单步巡逻计划,在这种情况下,护林员只关注下一个时间段的巡逻计划。2)多步巡逻计划,考虑到护林员的巡逻和观察历史以及域特征,多步巡逻计划用于生成后续ΔT>1 时间步骤的巡逻计划。前者提供了一个具有即时性的短期效益的单步巡逻计划,而后者则生成了一个具有长期效益的多步策略。在使用过程中,由护林员来选择使用哪种计划方案。对于本文提出的 CAPTURE 模型来说,为护林员设计巡逻计划的关键挑战是,我们需要考虑到对手(偷猎者)的建模。这包括护林员的检测不确定性和偷猎者活动的时间依赖性。这一挑战导致了一个复杂的非凸优化问题,以计算护林员的最佳巡逻策略。本文作者提供了一种游戏理论算法来解决这一问题。
假定护林员的观测历史为 o={o_t’,i}。与标准 SSG 类似,作者假设如果偷猎者在 (t,i) 处成功攻击,护林员会得到一个惩罚 (P_t,i)^d。相对应的,如果偷猎者没有成功攻击,则护林员得到奖励(R_t,i)^d。因此,如果偷猎者在(t,i) 攻击,护林员在 (t,i) 的预期效用计算如下式(3.5):
其中,p 表示 (t,i) 处护林员的探测概率。
3.2.1 单步巡逻计划
给定护林员的观测历史 o、模型参数(λ,w),生成后续 T+1 个步骤的最优计划的公式如(3.6)-(3.8):

其中,B 为护林员资源总和,p 为偷猎者在 (T+1,i) 处偷猎者的攻击概率。由于偷猎者的行为取决于他们过去的活动(对陌生人来说是隐藏的),我们需要检查偷猎者在以前的时间步骤中所有可能的行动,以预测偷猎者在 (T+1,i) 的攻击概率。作者提出,通过下式计算偷猎者在 (T,i) 处的攻击概率如式(3.9):
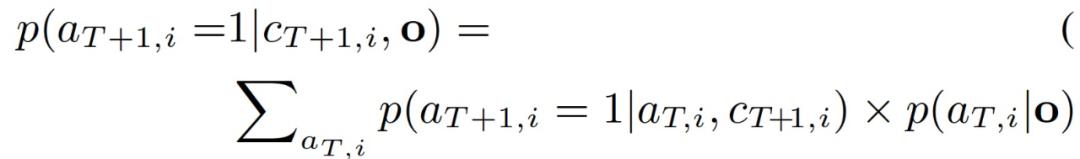
式 (3.6)-(3.8) 是一个护林员覆盖概率 {c_T+1,i} 的非凸优化问题。式 (3.6) 中护林员效用的每个加法项都是护林员在 (T+1,i) 的覆盖率 c_T+1,i 的单独子效用函数,下式为(3.10):
因此,我们可以对 f_i(c_T+1,i)进行分片线性近似,并将式 (3.6)-(3.8) 表示为混合整数规划(Mixed Integer Program),可以用 CPLEX 解决[13]。
3.2.2 多步巡逻计划
作者分析,在为护林员设计多步巡逻计划时,结合 CAPTURE 模型面临两个关键挑战:1)偷猎者行为的时间依赖性。2)偷猎者向护林员隐藏其实际行动(unobserved)。具体的,针对多步问题,后续ΔT 个时间步骤,即 T+1,...,T+ΔR 的最优巡逻计划可以表示为式(3.11)-(3.13):
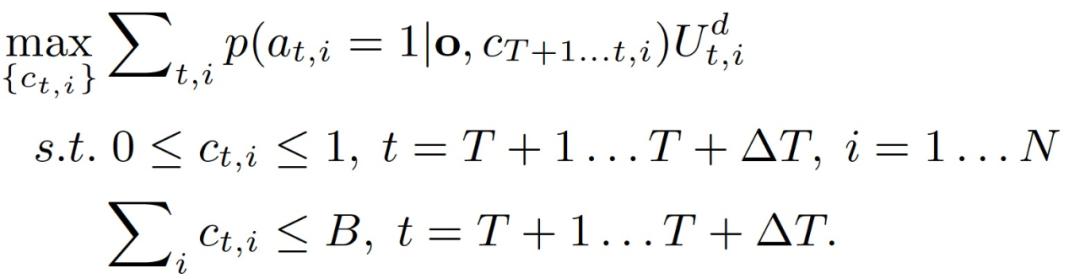
由于存在上述两个挑战,我们需要检查偷猎者在以前的时间步骤中所有可能的行动,以计算其在 (t,i) 的攻击概率。作者的想法是通过以前的时间步骤的攻击概率递归计算这个攻击概率,如下(3.14)-(3.16)所示:
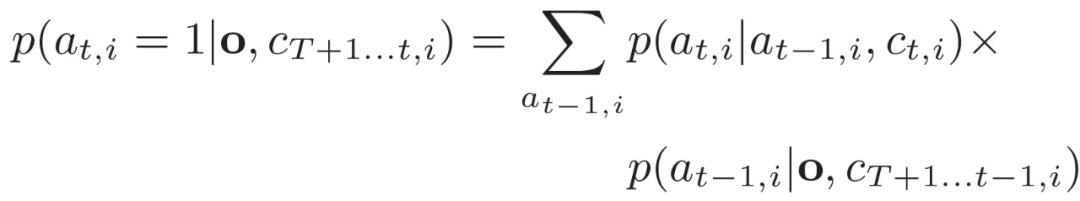
初始步骤通过使用 Baum-Welch 方法计算总概率。在这里,由于偷猎者行为的时间依赖性,公式 (3.14) 中的目标不能再划分为特定 (t, i) 的单一覆盖概率的独立子效用函数。因此,我们不能像单步巡逻计划中那样应用分片线性近似来快速解决式(3.11)-(3.13)。作者提出使用非凸求解器来解决式(3.11)-(3.13)。
3.3 实验分析
作者在实验阶段给出了不同场景下的实验结果,以验证 CAPTURE 的有效性。为了学习偷猎者的行为,作者使用护林员从 2003 年到 2014 年在 QENP 收集的 12 年的野生动物数据(图 16 为动物密度)。这项工作是在与野生动物保护协会(WCS)和乌干达野生动物管理局(UWA)的合作下完成的。在巡逻过程中,公园管理员记录信息,如地点(经度 / 纬度)、时间和观察结果(例如,人类非法活动的迹象)。作者还将收集到的人类迹象分为六组:商业动物(即指偷猎水牛、河马和大象等商业动物的人类迹象)、非商业动物、渔业、侵占、商业植物和非商业植物。在这项工作中,我们主要关注两种类型的人类非法活动:商业动物和非商业动物。其中,非商业性动物主要是指针对大象等关键物种的主要威胁。然后根据乌干达的四个季节将偷猎数据分为四个不同的组别:旱季 I(六月、七月和八月),旱季 II(十二月、一月和二月),雨季 I(三月、四月和五月),以及雨季 II(九月、十月和十一月)。我们的目的是学习偷猎者在这四个季节的行为,因为偷猎者的活动通常会随季节变化。最后,基于上述划分的两种偷猎类型和四个季节,我们得到了八个不同类别的野生动物数据。此外,在学习偷猎者的行为时还使用了域特征,包括动物密度、坡度、栖息地、净初级生产力(net primary productivity,NPP)和村庄 / 河流 / 道路的位置。
将野生动物园区域划分为 1km×1km 的网格,总共包含 2500 多个网格单元。然后将域特征和护林员的巡逻和观察汇总到网格单元中。进一步的,通过删除所有异常的数据点来完善偷猎数据,如表征护林员在 QENP 野生动物园外进行巡逻的轨迹数据或护林员行动太快的数据点等。由于试图根据偷猎者过去的活动来预测他们未来的行动,作者采用了一个时间窗口(即 5 年),其中有 1 年的迁移期,将偷猎数据分成 8 对不同的训练 / 测试集。例如,对于(商业动物,雨季 I)类别,最古老的训练 / 测试集对应于该类别的四年数据(2003-2006)进行训练,对应于一年(2007)的数据进行测试。最新的训练 / 测试集分别指四年(2010-2013)和一年(2014)的数据。总的来说,我们的八个数据类别中的每一个都有八个不同的训练 / 测试集。
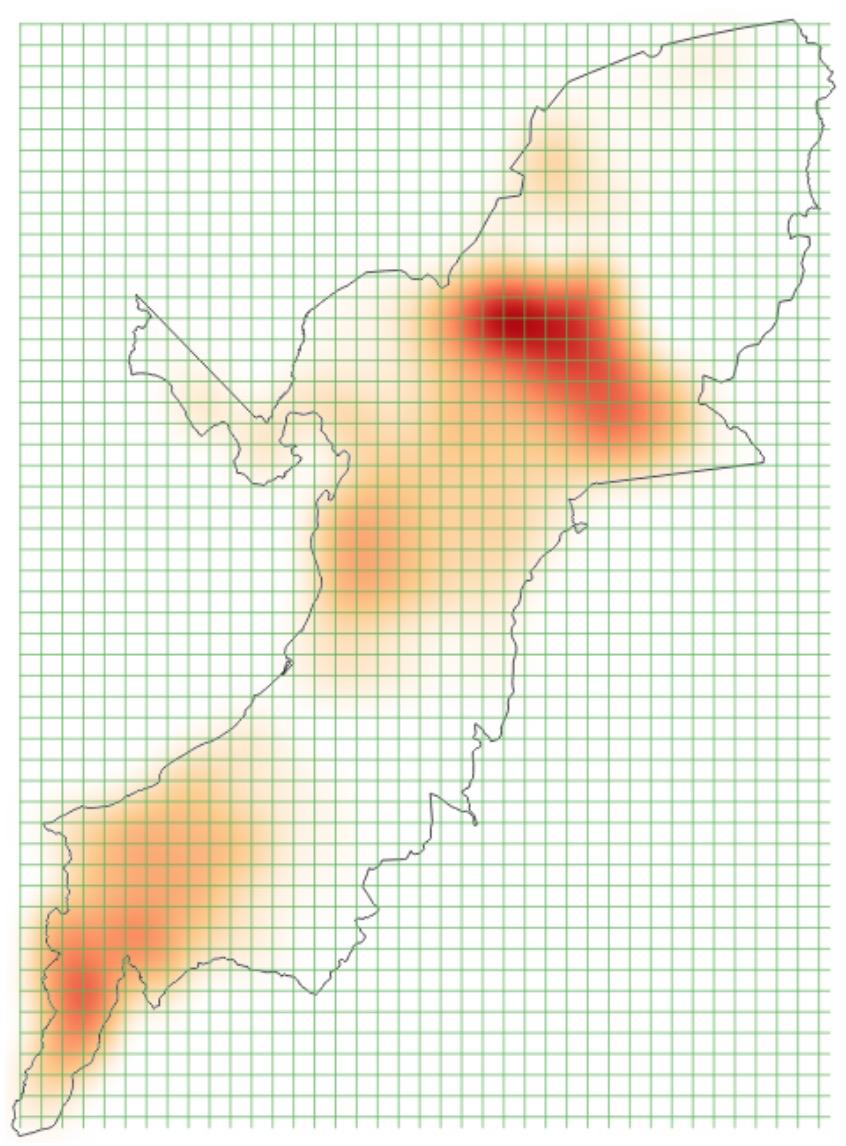
图 16. QENP 动物密度
在这项工作中,作者比较了六个模型的预测准确性。1)CAPTURE(参数分离的 CAPTURE);2)CAP-Abstract(参数分离和目标抽象的 CAPTURE);3)CAP-NoTime(参数分离的 CAPTURE,没有时间效应的成分);4)Logit(逻辑回归);5)SUQR;6)SVM。作者使用 AUC 来衡量这些行为模型的预测准确度。从本质上讲,AUC 指的是一个模型在将这些样本标记为阳性时,随机的阳性偷猎样本的权重高于随机的阴性偷猎样本的概率(所以,AUC 值越高越好)。此外,作者还给出了所有季节的平均预测准确率。作者使用 bootstrap-t 来衡量结果的统计学意义。最终的统计数据分别见表 3 和表 4。CAPTURE 比最先进的技术(SUQR 和 SVM)的预测准确性还有所提高。表 3 中 CAPTURE 的平均 AUC(基本上是四个季节的八个测试集的 32 个数据点)是 0.7475,而 SUQR 是 0.575,在表 4 中是 0.74 而 SUQR 是 0.57。
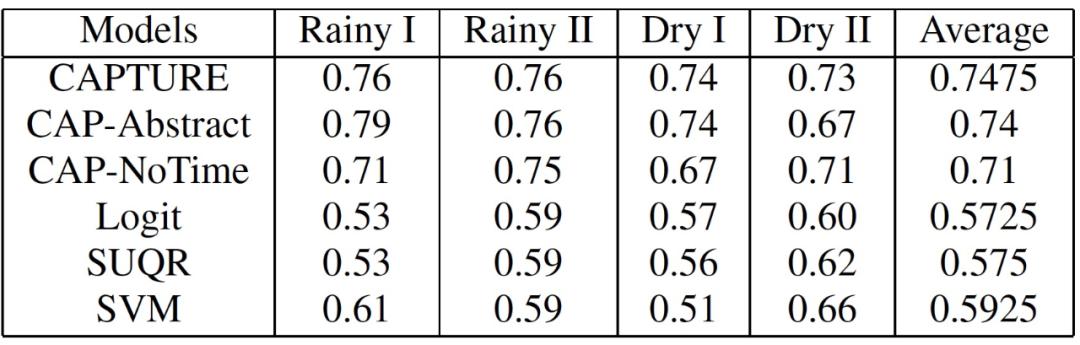
表 3. AUC:商业动物
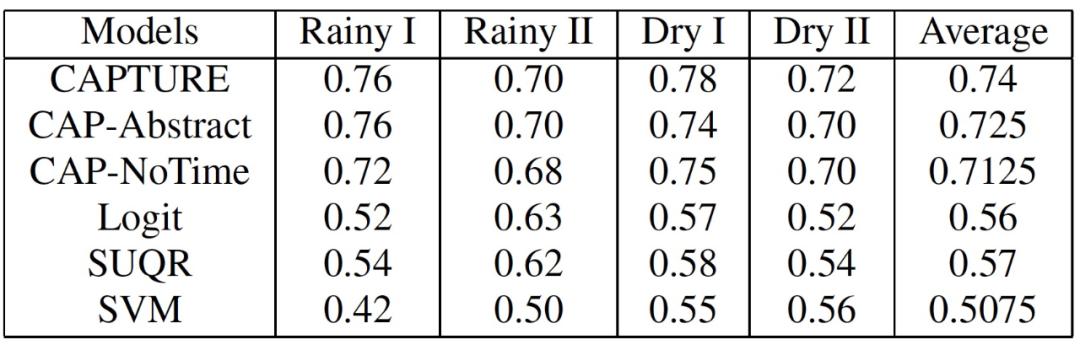
表 4. AUC:非商业动物
最后,作者应用 CAPTURE 规划算法来生成护林员的最佳巡逻计划。具体针对解决方案的质量评估是基于现实世界的 QENP 与 SUQR 的比较来完成的(护林员对基于 SUQR 的偷猎者的最佳计划),Maximin(护林员对最坏情况下偷猎者反应的最大化策略)和护林员的真实世界巡逻计划。鉴于 CAPTURE 的预测准确率是所有模型中最高的,在本文实验中,作者假设偷猎者的反应遵循 CAPTURE 模型。根据 QENP 的实验设置,护林员在每个目标的奖励被设定为零,而惩罚则与动物密度相反。作者根据护林员资源的不同数量(即护林员在巡逻期间可以覆盖的目标数量)来评估所有算法的解决方案质量。此外,还考虑了生成巡逻的不同时间步数。
图 17 中给出的实验结果是所有年份和季节的平均数。其中,X 轴是护林员的资源数量,Y 轴是护林员在两个和四个时间步骤(季节)内分别应用 CAPTURE、SUQR、Maximin 和 Real-world 巡逻计划所获得的综合效用。如图 17 所示,CAPTURE 规划算法为护林员提供了最高的效用。特别是当护林员的资源数量增加时,CAPTURE 规划算法明显提高了护林员巡逻计划的质量。此外,CAPTURE 提供的巡逻计划考虑到了对偷猎者行为的时间影响。因此,当时间步数增加时(图 17(b)),本文算法与其他算法相比提高了其解决方案的质量。
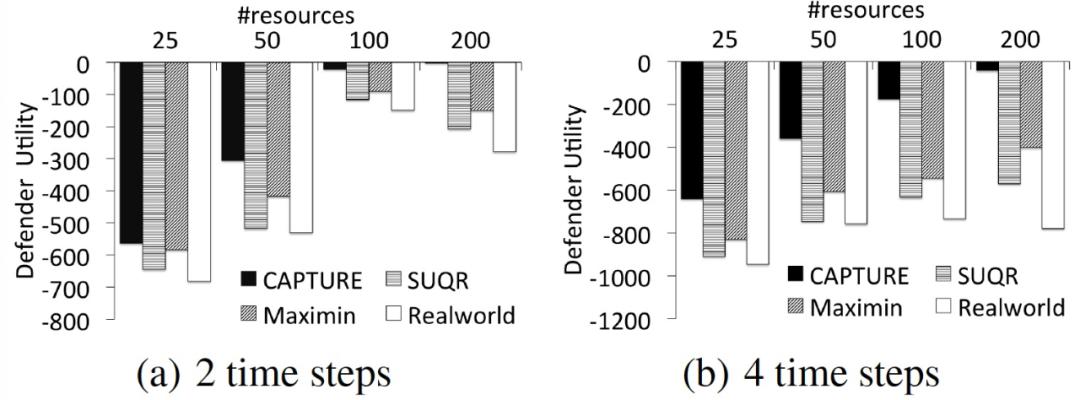
图 17. CAPTURE 规划算法生成护林员的最佳巡逻计划结果比较
CAPTURE 工具可供护林员预测偷猎者的行为并设计最佳的巡逻时间表。不过,在真实情况中并非所有地区对偷猎者都有着相同的吸引力,因此,检测偷猎者的活动热点地区并提高对这些地区的保护概率将可能会更加有效。考虑到这一问题的软件的一般工作流程可以分为以下几项。1)汇总以前从野生动物园收集的数据,创建一个数据库,包括域特征、偷猎迹象和护林员保护该地区的努力;2)对数据点进行预处理;3)运行 CAPTURE 工具,预测攻击概率、护林员对该地区的观察并生成最佳巡逻计划;4)对结果进行后期处理并生成相关热图。
为了比较 CAPTURE 提供的单步巡逻计划算法所产生的最佳计划和当前在该地区部署的实际计划,作者根据防御者的覆盖范围绘制了相关的热图,如图 18(a)和图 19(a)所示。该地区颜色越深,其被护林员覆盖的机会就越大。另外,作者用 CAPTURE 预测了基于这些巡逻计划的攻击概率。这些热图显示在图 18(b)和图 19(b)中。地图上的深色区域显示了对偷猎者更有吸引力的区域。根据热图,我们可以看到以下关键点:(i)最佳巡逻计划覆盖了更多动物密度较高的区域。因此,部署最优计划将会对动物密度较高的地区提供更多的保护。(ii)如图 18(a)和 18(b)所示,偷猎热图显示在动物密度较高的地区,攻击者对人类产生的巡逻的预测活动明显较高。
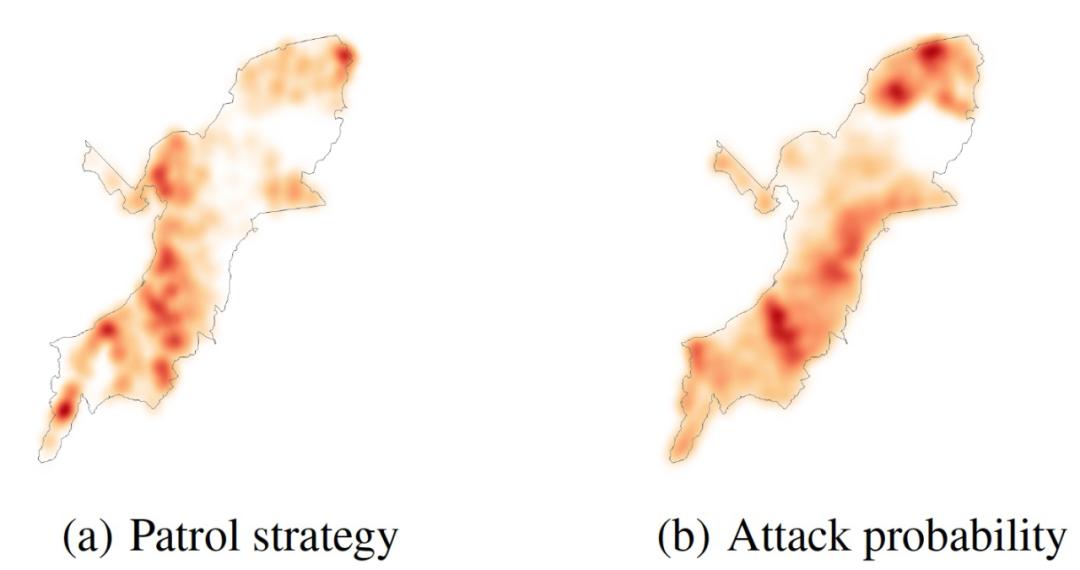
图 18. CAPTURE 的热图(基于真实的巡逻策略)
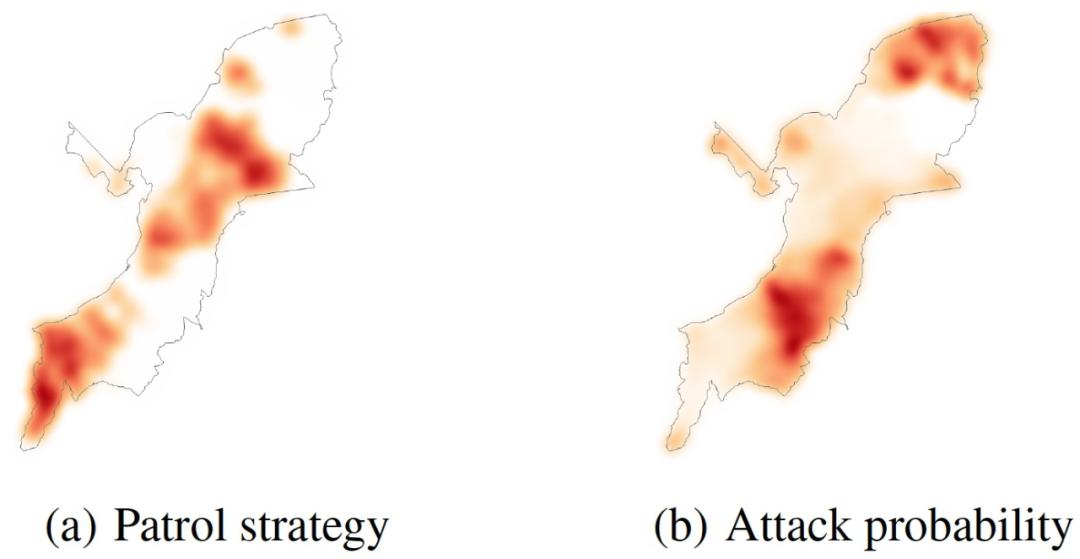
图 19. CAPTURE 的热图(基于最佳策略)
4 文章小结
本文讨论了人工智能的一个专门应用领域:野生动物保护,具体包括了对野生动物的监测和对偷猎者轨迹预测两个方面。国内外也有大量的研究学者和研究机构在致力于这项工作,结合不同区域特征、动物特征和生物学需求等开发不同的工具,将不同的人工智能、机器学习方法应用于野生动物保护事业中。人工智能技术需要真正和实际问题结合起来,才能慢慢改变世界,让劳动力从野外工作的危险和枯燥解脱出来。我们也希望看到越来越多的人工智能技术能够应用于类似的领域,让整个世界变得更加美好。
部分参考引用的文献
[1] Eric J. Howe, Stephen T. Buckland, Marie-Lyne Despres-Einspenner, and Hjalmar S. Kuhl. Distance sampling with camera traps. Methods in Ecology and Evolution, 8(11):1558{1565, 2017. doi: 10.1111/2041-210X.12790. URL https://besjournals.onlinelibrary.wiley.com/doi/abs/10.1111/2041-210X.12790.
[2] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross B. Girshick. Mask R-CNN. CoRR, abs/1703.06870, 2017. URL http://arxiv.org/abs/1703.06870.
[3] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2. https://github.com/facebookresearch/detectron2, 2019.
[4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015. URL http://arxiv.org/abs/1512.03385.
[6] Z. Xu, S. Liu, J. Shi, and C. Lu. Outdoor rgbd instance segmentation with residual regretting learning. IEEE Transactions on Image Processing, 29:5301{5309, 2020. doi: 10.1109/TIP.2020.2975711.
[7] Blender Foundation. Blender - a 3D modelling and rendering package, 2018. URL http://www.blender.org (http://www.blender.org/).
[8] Timm Haucke,Volker Steinhage, Exploiting Depth Information for Wildlife Monitoring, 2021, https://arxiv.org/abs/2102.05607v1
[9] Chalmers, C. , et al. "Modelling Animal Biodiversity Using Acoustic Monitoring and Deep Learning." (2021).https://arxiv.org/abs/2103.07276
[10] Beale, C. M. , et al. "CAPTURE: A New Predictive Anti-Poaching Tool for Wildlife Protection." International Foundation for Autonomous Agents and Multiagent Systems(2016).https://pure.york.ac.uk/portal/en/publications/capture(a5f3ca8c-9a4e-4366-af26-095154c2f7d6).html
[11] F. Fang, T. H. Nguyen, R. Pickles, W. Y. Lam, G. R. Clements, B. An, A. Singh, M. Tambe, and A. Lemieux. Deploying paws: Field optimization of the protection assistant for wildlife security. In IAAI, 2016.
[12] R. Critchlow, A. Plumptre, M. Driciru, A. Rwetsiba, E. Stokes, C. Tumwesigye, F. Wanyama, and C. Beale.
Spatiotemporal trends of illegal activities from ranger-collected data in a ugandan national park. Conservation Biology, 2015.
[13] R. Yang, F. Ordonez, and M. Tambe. Computing optimal strategy against quantal response in security games. AAMAS, 2012.
分析师介绍:
本文作者为仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
原标题:《AI专用领域之一:声音、相机陷阱用于野生动物研究和保护》