原创 Kai 世界顶尖科学家论坛

你能想象在一台电脑上复制一个人类大脑和它的工作原理吗?这就是人类大脑计划(Human Brain Project ,以下简称HBP)的一项内容。
这个为期10年的项目始于2013年,欧洲100多所大学、教学医院和研究中心的约500名科学家受雇参与其中。HBP是欧盟有史以来资助的最大科学项目——四个“未来和新兴技术旗舰项目”(Future and Emerging Technology)之一。
HBP将人脑项目将神经科学家、计算机和机器人专家聚集在一起,为了大脑研究建立一个独特的信息和通信技术(ICT)为基础的脑研究基础设施, 旨在增强脑部研究的能力,以了解人类大脑及其疾病,由此推动大脑医学和计算技术的发展。
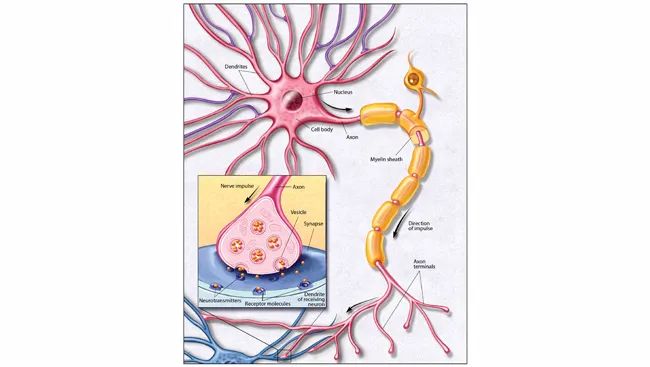
然而,这是一个复杂的挑战,因为人的大脑包含860亿个脑细胞(称为神经元),每个神经元平均有7000个连接到其他神经元(称为突触)。目前的计算机能力不足以对整个人脑进行这种程度的相互连接建模。
但HBP也没有放弃构思全脑模型。在这些模型中,最小的单位不是一个神经元,而是一个神经元群,对应的是大脑成像的分辨率。这些全脑模型是针对小鼠和人脑做的,它们可以直接整合来自连接组的数据。这样的模型可以用来预测和研究病理现象,如癫痫或中风等。
HBP在过去的七年间不断致力于以数据为动力推动神经系统科学的蓝图。神经科学领域大数据如火如荼的现象早已备受瞩目。
专注生命科学研究进展的媒体《生物通》在2018年发表标题为《2018年新技术:大数据时代的神经科学》的文章,描述了这项神经科学的新变化:当下成像技术和高通量记录技术的进步正在以前所未有的速度生成神经科学数据。
文中也提出追问:人脑是一个智能而复杂的机器,而其中大多数神经元行为非常复杂。定量的大数据分析真的能完全模拟神经元活动,并且主宰我们的神经元科学,带我们进入神经科学的大数据新纪元吗?
日前,曾在美国德克萨斯大学奥斯汀分校担任研究科学家,致力于研究机器学习和自然语言处理的美国作家(?)Erik Larson在国际期刊Inference上发布题为“Big Neuroscience”(大神经科学)的文章,深度刨析大数据研究对于神经科学的影响与未来。
在分析盘点了HBP及其前身“蓝脑计划”、美国Brain计划、Mindscope等计划后,Erik Larson提出了明确的观点:大数据只能作为帮手,而无法作为神经科学的主宰。
Erik Larson认为,数据就是数据,就是观察,就是经验,它永远不应该占据神经科学的核心地位。研究和实验亦不应该让位于数据收集和计算机分析。
世界顶尖科学家论坛以获得授权编译转载。
大神经科学
大数据从一开始就被夸大其词,而现在变成了一种过分吹嘘。Viktor Mayer-Schönberger和Kenneth Cukier将他们最近出版的书命名为《大数据:一场将改变我们生活、工作和思维方式的革命》。映入眼帘的并不是非常谦虚的前景。

当然,如果能对大数据有一个准确的定义,那就更有帮助了。《福布斯》杂志2012年发表的一篇文章就说明了概念上的混乱:"12个大数据的定义:你支持哪个?” 2001 年,早在这个术语本身还没有进入词典的时候, Doug Laney就将大量的数据集所带来的挑战描述为“由三个属性的同时扩展所带来的挑战”:“数量”(volume)、“速度”(velocity)和“多样性”(variety)。
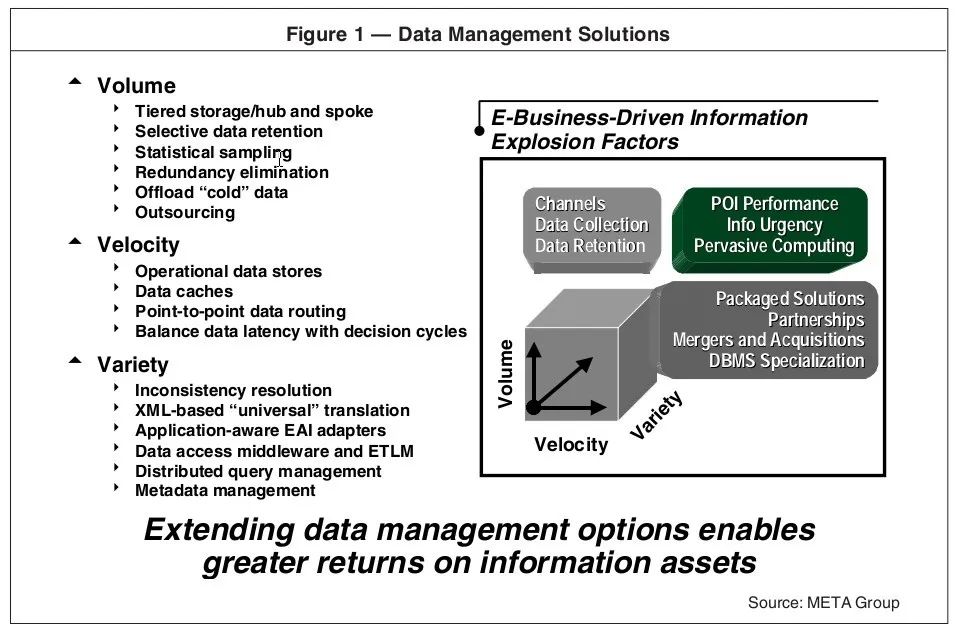
在这个3V的模型上,IBM又增加了“真实性”(veracity)。不满足于4V的模型,其他人还进一步扩大了框架,表现出对Laney最初的构思不屑一顾。甲骨文公司将大数据定义为 "从传统的关系型数据库驱动的商业决策中衍生出的价值,并辅以新的非结构化数据来源。"在 2012 年的一项研究中,英特尔设定了大数据的界限,即以“组织每周产生中位数为300TB的数据”为参照。另一方面,微软将大数据定义为一组用于分析大量的数据集的技术。数据可能是海量的;分析才是最重要的。

这些都甚至不能算定义,而是一系列的说法。混合和匹配:大数据指的是对数据集在一定规模上的存储和分析,而在这个过程中数据的分析使得新的见解的诞生成为了可能。
毫无疑问,这样的规模是存在的;数据分析确实能带来新的洞察力;但这些洞察力是否有很大的价值是另一回事。
在科学史上,大数据的光辉性是新的,但它深层的思想却不是。
经验主义如果不是这种将科学本质上看作数据的收集和分析的观念,那它又能是什么呢?科学的职责其实是观察。这是一个可以追溯到英国的经验主义者们:洛克、乔治·贝克莱、大卫·休谟的论点。经验主义就好像休谟所理解的那样,是一个出人意料的严厉的大师。

休谟认为,因果之间没有必然的联系。正如我们所知道的那样,下一个吞下一口马钱子碱的人可能会发现它是有营养的。如果因果之间没有必然的联系,那么在经验中也无法辨别。有吞食毒药,也有随之而来的死亡。它们之间的因果仍然是隐藏的。
休谟的结论是,正是事件之间的不断结合,为经验主义者提供了他所能知道的关于它们的因果结构的一切。
这个结论并不是给科学议程注入了乐观主义色彩。休谟观察到:
“当然,我们必须允许,自然界使我们与她的所有秘密保持着很大的距离,只给我们提供了物体的几个表面质量的知识;而她对我们隐瞒了那些完全依赖于这些物体的影响的力量和原则。”
英国的经验主义者虽然早已消亡,但在二十世纪上半叶又死灰复燃。逻辑实证主义者认为,我们在科学中所拥有的,就是休谟所说的我们所拥有的:经验的多元性,回过头来看,就是数据的记录。一些科学届的哲学家们认识到了随之而来的讨论的无菌性。
卡尔·汉普尔认为,即使是简单的现象,也不能用观察来解释。木头漂浮在水上,而不是铁。还有什么比这更简单呢?但是,木头有时会下沉,铁有时会浮起来。只有比重的概念才能让物理学家解释为什么一个有水的棺材会下沉,而一个空心的金属球体会浮起来。物体的比重就像事件之间的因果关系:两者都不能直接把握;两者都在面纱的背后;每一个都在解释中有重要的意义。
现代神经科学有赖于计算模型和模拟。令人印象深刻的计算资源是广泛存在的。这样的研究环境经常被称为脑观察站。位于西雅图的艾伦脑科学研究所(AIBS)就是一个例子。
Mindscope是目前AIBS的一个项目,它所关注的是建立现实的动物和人类大脑的以神经元为基础的模型。大脑观测站使大脑地图或地图集成为可能。这些是大型的、计算生成的模型。没有一个脑图集是不完整的,它是代表神经元、神经元回路和大脑区域之间的连接的网络图。
2011年由卡夫利基金会赞助的脑活动图谱(BAM),旨在开发小鼠、猴子和人类等动物脑活动的动态图谱。这个项目已被归入美国政府的 "通过推进创新神经技术研究计划"(BRAIN计划)——一个起始于2014年并且预计在接下来的十年里花费30亿美元的长期项目。AIBS也正在完成艾伦小鼠脑连接图谱的工作,哈佛医学院有全脑图谱,而密歇根大学有人脑图谱。
研究人员经常自豪地提到他们的数据集的规模。现在,大数据已经变得真的“非常”大了。人脑连接组项目预计将产生超过1PB的相对高质量的成像数据。AIBS在研究和映射小鼠大脑7500万个神经元的过程中,已经积累了1.8PB的数据。虽然规模令人印象深刻,但这些数据集与大型强子对撞机每年产生的30PB的数据相比还是相形见绌的。
一些模拟已经得到了媒体的极大关注。也许最广为人知的是Henry Markram的用来模拟老鼠大脑皮层柱的 "蓝脑计划",是以IBM蓝色基因超级计算机来命名的。尽管这个项目被广泛认为“几乎没有告诉我们任何有关大脑如何引发行为”,但却激发了一个被称人类大脑计划(HBP)的后续项目。

其他值得注意的大规模大脑模拟包括Dharmendra Modha的在神经形态自适应塑料可扩展电子项目系统(SyNAPSE)项目里开展的工作。IBM认知计算小组经理Modha将他的模拟工作描述为“通过Synaptronics和超级计算进行认知计算”。他的工作的目标是尽可能便宜和快速地构建大脑。Modha声明他已经通过配备有147456个CPU和144TB内存的IBM 蓝色基因的超级大脑逆向推理了一只猫的整个皮层。
正如一个人可能会想的那样,Markram对这些声明提出了批评,认为Modha的模拟不符合生物学的实际情况。公平至上。虽然比Modha的项目复杂得多,但即使是Markram的工作也简化了实际神经元的行为。
HBP于2013年在洛桑联邦理工学院(École polytechnique fédérale de La Lausanne)启动,已在欧盟的批准下在10年内获得超过10亿欧元的资助。HBP致力于以数据为动力推动神经系统科学的蓝图。
HBP断言,智慧来自于大脑神经元的复杂互动。智慧的出现,除了模拟神经元以及神经元之间的突触连接的方案之外,不需要更多的东西。旨在发现我们知识中缺失的部分的分头的努力是没有必要的,并且事实上往往会使神经科学支离破碎,最终阻碍研究工作的进行。2010年,超过60000篇标题写着“大脑”的论文被出版了。
在Markram看来,神经科学已经令人绝望地支离破碎。
科学史现在要重新确立自己的地位了。
“木头会漂浮,但铁会下沉”的陈述中几乎没有提到浮力的事情,而陈述中提到的那一丁点儿也是错的。而关于神经元的陈述——它们有什么不同吗?如果有,是怎样的?如果需要用比重来解释浮力,那么解释大脑又可能需要用到什么样的理论概念呢?这个问题的正确是:谁知道呢?几乎所有的神经科学家,包括Markram本人在内,都承认我们还没有具备那个能使大量的数据有意义的理论框架。
大脑起初所使用的产生复杂的认知,知觉和运动行为的复杂、多元神经代码实际上到底是什么呢?这段代码某种程度上与神经元突跳的行为有关,但我们尚不知道如何。
Markram认为神经元尖峰可以主要用由离子电荷差异引起的膜行为来解释;因此,与振荡等高阶模式相比,时序的相关性更大。
一旦数据生成后,它们被用来扩大多变量模拟的规模。为了模拟生物学上逼真的神经元及其连接,需要建立一个神经元行为模型。Markram的理论基于Hodgkin和Huxley方程,这是一组描述动作电位的启动和传播的非线性微分方程,Alan Lloyd Hodgkin和Andrew Huxley以普通电路为框架在20世纪50年代提出了他们的模型。
20世纪90年代在耶鲁大学开发的NEURON软件是在H-H模型的基础上开发出来的,今天在一系列神经科学项目(包括HBP)中使用。
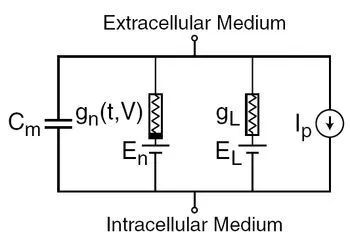
H-H模型并不能完全解释神经元的尖峰行为,甚至是离子通道行为。尽管如此,还是取得了一些进展。Hodgkin和Huxley无法确定离子传导的时间激活序列。他们只能对其进行近似。20世纪60年代和70年代的研究通过使用膜跨越蛋白的孔隙理论,部分地解决了这个问题。然而,除了这些相对较小的调整之外,至今在神经科学中仍占主导地位的是基本的H-H模型。
在他们最初的研究中,Hodgkin和Huxley提出了描述离子门处于开放状态的概率的一阶速率方程。他们的方程依赖于一些参数化的推理。他们是如何得出他们的具体推理的,Hodgkin和Huxley也承认这一点。
因此,一个典型的HBP协议具有以下形式:
a. 研究论文扫描其数值参数:应用刺激协议、离子通道的反向电位和灭活动力学。
b. 由于从经验发现的参数建立H-H模型所需的方程往往从文献中缺失,因此,曲线数字化是用来重现它们。这是一种将图形图像转换为数值公式的技术。给出一条标准的激活曲线,在笛卡尔坐标系中绘制了一条标准的激活曲线,曲线数字化技术可以提取一个函数,在坐标系中重新创建曲线。目前,一个开放源码软件包Engauge Digitizer就是用于此目的。
c. 数字化和曲线拟合后,用另一个软件包GenericFit来模拟H-H模型。
d. 由于生成的初始模拟通常是错误的,因此需要对参数进行重新调整。计算机模型是通过调整从参数识别中提取的数字来拟合实验结果的,这个过程被称为双重推演。
这不是一个计算出来的方案,如果只是因为在单个神经元水平上引入的错误会传播到下游模拟中的神经元组和电路中的神经元,那么这并不是一个激发信心的方案。
然后是预测性神经科学(PN),这是一种由研究人员使用HBP模拟神经元之间的连接的方法。利用归纳机器学习技术,从已知联系中确定未知的突触联系。传统的神经网络,以及更强大的扩展网络,即卷积神经网络,都被使用。
Markram已经表明,机器学习函数可以正确预测大鼠大脑皮层柱中先前未知的连接。使用标准F度量统计量进行的分析得出的这种方法的准确性接近80%。虽然代表了将机器学习应用到生物数据集上的一个进步,但这种方法的平均错误率为十分之二。这对任何逆向工程人脑的策略都不是什么吉祥的含意。但撇开这个问题不谈,在这里值得关注的是这种方法所固有的归纳性假设。
机器学习的方法首先是为模型提供一些已知的训练实例。每个经过实验验证的神经元可能构成一个实例。某些参数被指定,然后模型通过训练实例学习神经元之间的连接点。数值优化技术迫使模型收敛到最适合训练实例的参数值。一旦训练完毕,模型就可以在之前未见过的实例上运行。对测试或生产数据集上的连接点的预测通过与训练集进行比较来测试。
机器学习技术是归纳式的。单纯的归纳是保守的,即把我们已经知道的东西应用到新的实例上。但是,当一组观察结果背后的基本原理不完整或基本未知时,这种方法就会失败。
HBP对PN的接纳特别容易受到这些危险的影响。我们对产生的关于大脑的数据的基本分布缺乏一个完整的或者甚至是充分的理解。如果说这种情况似乎令人不安,那么对大规模大脑模拟及其对数据驱动方法的依赖的更广泛的看法就更令人不安。
考虑一下 "兴起 "的概念—对这种“神经元层面的数据分析足以解释认知、或者感知、或者意识又或者是观念”的声明的流行解释。
只要有足够的数据,必然会有新的东西出现。
正如Markram所指出的那样,神经科学家们已经接受了模拟,希望这种模拟可以扩大规模,希望扩大规模本身就能产生洞察力。而如果扩大数据规模不可能产生任何感兴趣的东西,那么为什么不扩大研究人员的规模呢?很显然,关键是要扩大规模。Markram和国际神经信息学协调机构的主任Sean Hill都是蜂群科学的支持者。因此,Hill说:
"人脑项目的一个目标是引发和促进神经科学领域的新一轮全球合作。..............如果成功地让社区参与进来,目标是让成群的科学家一起攻克理解大脑及其疾病的主要挑战--在这样的环境中,每个人都会因为自己的贡献而得到认可。"
蜂群的比喻可以说是大数据的逻辑终点。数据收集和计算机分析占据了核心地位。研究和实验已经退出了人们的视野。
这里面没有什么是新的东西。类似的众人智慧的观念,其实一直是传世趋势的标志,如Web 2.0等。如果优化已知的数量是最重要的,那么以群体为中心的方法是有价值的,但如果不是这样,它们就会变得毫无效果。
当然,这是我们早知道或应该知道的事情。
更广泛的神经科学界,尤其是欧洲的神经科学界,对HBP提出了尖锐的批评。2014年7月,一份有800多个签名的请愿书对项目的进程表示了担忧,指出第二轮供资 "不幸的是,第二轮供资 反映了目标和资金分配的近一步缩小,包括取消了整个神经科学子项目,并因此删除了另外18个实验室。” 如果对HBP进行正式审查证明无效,签署方要求:
欧盟委员会和成员国将目前分配给HBP核心项目和合作项目的资金重新分配给广泛的神经科学导向的资金,以实现HBP的最初目标--了解大脑功能及其对社会的影响。
神经科学,乃至科学本身的希望,都依赖于我们的工具和仪器的进步,包括我们的计算资源。这类工具是帮手,而不是主宰。
科学中的大数据已经是众所周知的事情。它是数据。数据就是观察。观察就是经验。而没有理论的经验,正如伊曼纽尔·康德所说,没有理论的经验是盲目的。
Erik Larson 介绍
Erik Larson是美国作家,曾任美国德克萨斯大学奥斯汀分校的研究科学家,专门研究机器学习和自然语言处理。目前,他正在撰写一本书,探讨现代社会中的人工智能问题。

世界顶尖科学家协会成员、1979年物理学奖得主、美国理论物学家Sheldon Lee Glashow担任Inference 的编委和自由编辑,他本人也是广受欢迎的美剧《生活大爆炸》里“谢耳朵”的原型;世界顶尖科学家协会成员、2017年诺贝尔物理学奖得主、“引力波研究”先驱Barry Barish和中国科学院院士、清华大学跨学科信息科学研究所所长、2000年图灵奖获得者姚期智同为该刊编委。
世界顶尖科学家论坛(WLF)得到了Inference平台的授权,将逐步引入其中的精彩文章。
(备注:编译稿件仅供参考,Inference 原文以英文原文为准,点击阅读原文查看)

1. 生物通,2018年新技术:大数据时代的神经科学,http://www.ebiotrade.com/newsf/2018-1/2018125172340284.htm
2. Brain Facts, The Neuron, https://www.brainfacts.org/brain-anatomy-and-function/anatomy/2012/the-neuron
3. Data Innovation, Book Review of “Big Data: A Revolution That Will Transform How We Live, Work and Think”, https://www.datainnovation.org/2013/05/book-review-of-big-data-a-revolution-that-will-transform-how-we-live-work-and-think/
4. Coursera, Douglas B. Laney, https://www.coursera.org/instructor/dblaney
5. Gartner Blog Network,
Deja VVVu: Others Claiming Gartner’s Construct for Big Data, https://blogs.gartner.com/doug-laney/deja-vvvue-others-claiming-gartners-volume-velocity-variety-construct-for-big-data/
6. OUP Blog, David Hume: friendships, feuds, and faith, https://blog.oup.com/2017/05/david-hume-life/
7. Loop,Henry Markram,https://loop.frontiersin.org/people/74/bio
8. Wikia, Hodgkin-Huxley model, https://psychology.wikia.org/wiki/Hodgkin-Huxley_model
9. Human Brain Project,Overview,https://www.humanbrainproject.eu/en/about/overview/
10. European Commission, Human Brain Project (HBP) Flagship, https://ec.europa.eu/digital-single-market/en/human-brain-project
头图源自https://blogs.oracle.com/bigdata/big-data-highlights-from-oracle-openworld-2019
(责任编辑:小文)