原创 浙大管院 浙江大学管理学院 收录于合集 #“科研”ZJUSOM 19个
“科研 ”
ZJUSOM
如果一个商场持续促销,你会有立即购物的冲动吗?可能不会!没有间隔的促销或许会降低你的消费激情。
如果一个线上购物平台持续的向你推出同一品类的东西,你会买账吗?可能不会!过于相似的商品会让你产生审美疲劳,并失去下单的欲望。
然而,你相信吗,对于这些问题的改进,不需要商家或品牌方,仅仅通过人工智能就可以实现!从语音识别到图像处理、从自动驾驶汽车到医疗机器人,如今再到营销领域,人工智能的“深度强化学习”为数字领域带来很多前所未有的机会。

浙江大学管理学院市场营销学系教授王小毅和团队正是发现了“深度强化学习”为数字营销领域革命带来的巨大启示和变化,对其进行了一系列深入研究,并设计了一种基于DRL的个性化目标定位策略。
日前,王小毅与团队在管理科学领域国际顶刊《MANAGEMENT SCIENCE》上发表了有关数智营销的科研成果"Deep Reinforcement Learning for Sequential Targeting"(运用深度强化学习实现动态连续定位营销)。

究竟什么是“深度强化学习”?
人工智能算法是如何助力数字营销发展的?
科研团队都做了哪些尝试?
本期【“科研”】,让我们一起走进王小毅团队的“AI营销世界”。

王小毅:浙江大学管理学院市场营销学教授、博导,数字化转型与脑机智能营销交叉研究专家,获得中国商业联合会科技进步一等奖等省部级奖励多项。
在《管理世界》、Management Science、MarketingScience、JournalofMarketingResearch、InformationSystemsResearch等期刊发表论文,谷歌学术H指数为20。
他们为何聚焦机器学习来
研究营销定位策略?
目标市场定位营销(Target Marketing)通常是指企业识别各个不同的购买者群体,选择其中一个或几个作为目标市场,运用适当的市场营销组合,集中力量为目标市场服务,满足目标市场的需要。然而,在数字化时代,企业的营销策略越来越依赖于与消费者的高频次互动和对于营销策略的快速调整。此时,经典营销理论的传统思路和手段方法面临着越来越多的挑战。
传统的定位营销策略往往只考虑与顾客进行一次性“买卖”,较为依赖前期策划和庞大的广告投放,忽略了时间因素对消费者行为的影响和促销活动的连续性,成本巨大且结果不确定。
实际情况中,企业需要在多个周期内依次决定向谁发放优惠券、选择哪个促销活动以及决定两个活动之间的等待时长。与此同时,消费者的真实偏好也会随着时间的推移而快速改变。
因此,不论是学术界和产业界都迫切需要一种随着不断变化的顾客行为而进行调整的适应性定位营销策略。
作为一种新兴的人工智能算法,“深度强化学习”(Deep Reinforcement Learning,DRL)算法可以在没有人类监督的情况下持续“学习”提高性能,对解决上述问题具有巨大的潜力。
“深度强化学习(DRL)”是一种基于奖励的学习方法,它可以帮助定位营销策略实现个性化、强适应性,但它也面临着诸多挑战,例如对于时间影响的处理;对于复杂消费者行为维度的处理;对于策略效果的评估等。
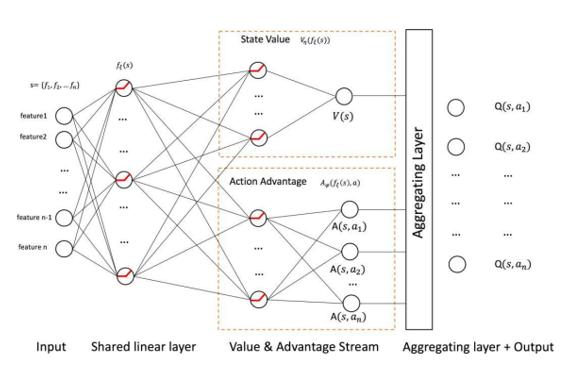
正是基于此背景,王小毅教授与团队提出了这种建立在DRL算法基础上的个性化目标定位策略,并使用一种基于量化的不确定性学习启发式方法来使DRL适应复杂的消费者行为维度。
科研团队都做出了哪些尝试?
人工智能的“自主学习”和不断升级,是通过“深度学习”和“强化学习”等技术来实现的。深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有决策能力,对感知问题束手无策。因此,将两者结合起来,优势互补,就能为复杂系统的感知决策问题提供新的解决思路,这就是我们所说的“深度强化学习(DRL)”,也是一种更接近人类思维方式的人工智能方法。
近年来,“深度强化学习(DRL)”取得了巨大突破,这种人工算法通过在给定奖励或惩罚反馈的情况下,让系统以不断试错的方式与营销环境进行连续交互,从而寻找到“最佳策略”,以完成学习的过程。
王小毅教授团队正是基于DRL人工算法,在序贯性定位营销设置的场景下,设计了这项个性化定位营销策略。
这项策略首先使用连续价格促销来吸引顾客的即时注意力并锁定他们,并在每两次价格促销之间提供一个非促销期(即冷却期),并且随着时间的推移逐渐增加冷却期的长度,以便顾客调整其价格参考点。
序贯性定位营销(Sequential Targeting),即连续地对消费者开展促销行为。
研究表明,采用深度强化学习方法可以解决当前实施连续定位营销策略所面临的三大挑战:
01
前瞻性
平衡公司当前收入和未来收入
02
边探索学习边获得市场回报
最大化利润,同时通过探索开发不断学习
03
可扩展性
应对高维状态和营销政策空间

为了更好地使DRL能够适应复杂的消费者行为维度,研究团队又提出了一种基于量化的不确定性学习启发式算法,以实现高效的探索开发。
通过评估,其结果表明,平均情况下,采用这种新算法代理(agent)产生的长期收入比采用传统方法所产生的收入多26.75%,学习速度也比所有基准中,其他产业界常用算法模型的速度快76.92%。
为了更好地理解研究结果背后的潜在机制,研究团队进行了多种可解释性算法的研究,能够解读个体和群体水平上学习最优策略的行为模式。
此外,王小毅教授与团队合作者提出的“模拟”在线测试环境为DRL训练和测试构建了用户行为模拟器,为平台提供了一种节省成本的方式来学习DRL代理,而无需在现实世界中运行大量、测试。

然而,不得不承认的是人工智能算法在营销领域的应用仍然面临着一些挑战。由于算法依靠训练数据和计算资源,需要进行大量的实验和优化来提高算法的效率和准确性;由于消费者行为的复杂性和不确定性,需要更多的数据和模型来解释和预测消费者行为;由于使用DRL算法的实时决策和调整需要在短时间内做出,因此需要建立一个实时决策系统来支持DRL算法的应用。
为了解决这些挑战,王小毅教授团队正在进一步努力开展研发工作,有望在今年提供一个更加通用和普适的DRL框架,框架也可以很容易地推广到其他目标市场营销场景,例如基于位置的服务、在线流媒体或在线教育的序贯推荐,可供平台和营销人员在日常实践中轻松使用。
该框架将基于量化的不确定性学习启发式方法,结合实时决策系统和用户行为模拟器,以提高DRL算法的效率和准确性,并帮助企业更好地理解和预测消费者行为,制定更加智能和有效的营销策略。
总体而言,王小毅教授团队的研究结果显示了“深度强化学习”方法在优化定位营销策略以最大化企业长期收入方面的巨大潜力,证明了这种方法在数字营销领域能够产生颠覆性影响。

他们的研究对
品牌价值和数字营销有何意义?
基于“深度强化学习”的营销策略对提升数字化营销效率有何作用?对助力企业制定数字化营销策略有何意义?
其实,这项听起来“神秘”的基于算法驱动的营销研究成果,与品牌、企业的息息相关,且在企业数字化转型中具有重要价值与战略意义。具体来说,它可以帮助企业更加精准地进行市场定位和目标营销,提高数字化营销的效率和精准度,实现业务增长和品牌价值的提升。
1
更好了解消费者的需求和偏好
“深度强化学习”可以帮助企业更好地了解消费者的需求和偏好,从而精准地进行市场定位和目标营销。
通过对消费者数据的深度分析,企业可以了解消费者的行为模式和心理特征,从而制定更加精准的营销策略。例如,企业可以根据强化学习算法的分析结果,适时调整产品定价、产品推荐、广告投放等策略,以提高消费者的消费忠诚度和购买转化率。
2
优化营销渠道,提升效率
“深度强化学习”可以帮助企业优化营销渠道,提高数字化营销的效率和精准度。
通过对不同营销渠道的数据进行分析和比较,企业可以了解每个渠道的贡献度和效果,从而制定更加科学的渠道策略。例如,企业可以根据强化学习算法的分析结果,适时调整各个渠道的投放比例和投放策略,以提高数字化营销的效率和精准度。
3
实现数字化营销的精细化和智能化
深度强化学习算法可以帮助企业实现数字化营销的精细化和智能化。
通过对消费者数据的深度学习和分析,企业可以了解消费者的行为和偏好,从而实现个性化的营销和服务。例如,企业可以根据强化学习算法的分析结果,针对不同的消费者群体,提供不同的营销方案和服务,以提高消费者的满意度和忠诚度。

基于这项研究成果,王小毅团队与阿里巴巴合作改进数字营销经营方法论、与浙江中烟合作设计智慧营销大脑,为传统零售商业的制定自有品牌策略等,为企业数智创新提供了新的路径和解题方式。
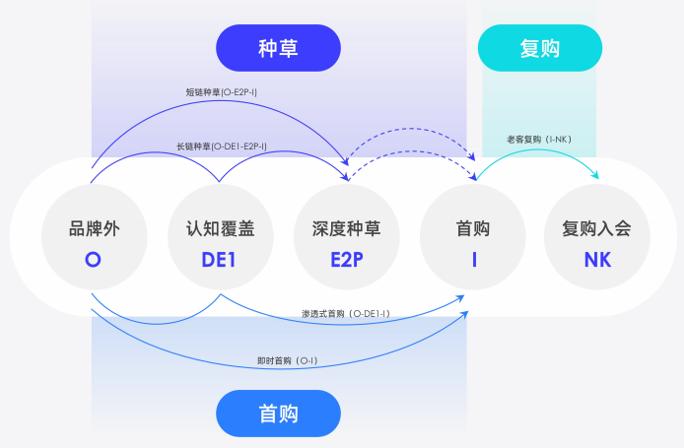
日前,王小毅教授联合阿里妈妈发布的DEEPLINK模型,详细解析了消费者从种草,到首购,在到复购的消费路径。
如果以“个性化定位营销策略”来分析解读模型中看似复杂无序的消费路径,可以将其拆解为:Discover发现—Engage种草—Enthuse热爱—Perform行动—Initial首购—Numerous复购—Keen忠诚。该模型是基于过去围绕销售漏斗的AIPL模型(Awareness认知-Interest兴趣-Purchase购买-Loyalty忠实)的进一步升级。
这样的路径分析能够帮助企业更好地理解和预测消费者行为,制定更加智能和有效的营销策略。
Deep reinforcement learning (DRL) has opened up many unprecedented opportu-nities in revolutionizing the digital marketing field. In this study, we designed a DRL-based personalized targeting strategy in a sequential setting. We show that the strategy is able to address three important challenges of sequential targeting: (1) forward looking (balancing between a firm’s current revenue and future revenues), (2) earning while learning (maximizing profits while continuously learning through exploration-exploitation), and (3) scalability (cop-ing with a high-dimensional state and policy space). We illustrate this through a novel design of a DRL-based artificial intelligence (AI) agent. To better adapt DRL to complex consumer behavior dimensions, we proposed a quantization-based uncertainty learning heuristic for effi-cient exploration-exploitation. Our policy evaluation results through simulation suggest that the proposed DRL agent generates 26.75% more long-term revenues than can the non-DRL approaches on average and learns 76.92% faster than the second fastest model among all bench-marks. Further, in order to better understand the potential underlying mechanisms, we con-ducted multiple interpretability analyses to explain the patterns of learned optimal policy at both the individual and population levels. Our findings provide important managerial- relevant and theory-consistent insights. For instance, consecutive price promotions at the begin-ning can capture price-sensitive consumers’ immediate attention, whereas carefully spaced nonpromotional “cooldown” periods between price promotions can allow consumers to adjust their reference points. Additionally, consideration of future revenues is necessary from a long- term horizon, but weighing the future too much can also dampen revenues. In addition, analy-ses of heterogeneous treatment effects suggest that the optimal promotion sequence pattern highly varies across the consumer engagement stages. Overall, our study results demonstrate DRL’s potential to optimize these strategies’ combination to maximize long-term revenues.
原标题:《他的UTD研究证明,AI算法可以给数字营销带来“巨变”……》