Pine 发自 凹非寺
量子位 | 公众号 QbitAI
输入一段台词,让照片“演戏”又进阶了!
这次的AI直接让“演技”整体上了一个台阶,表演生气、开心、可怜……各种情绪都不在话下。
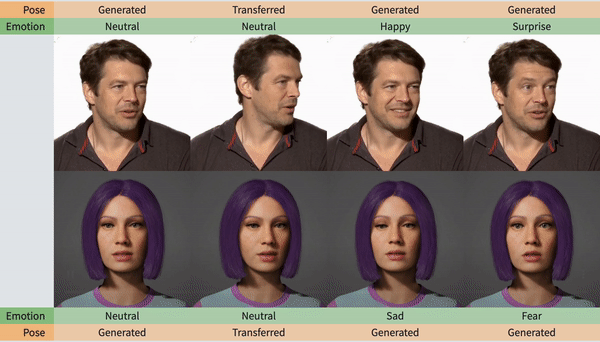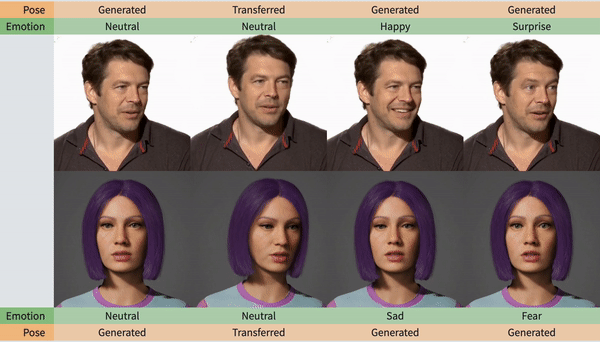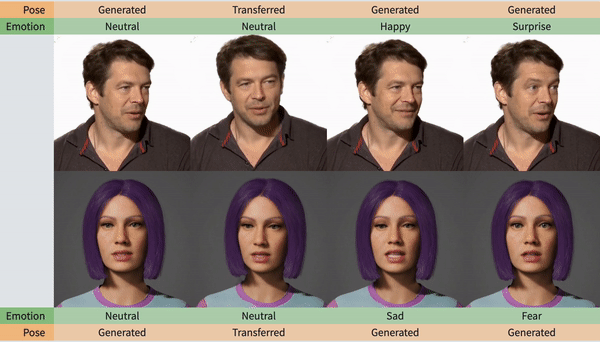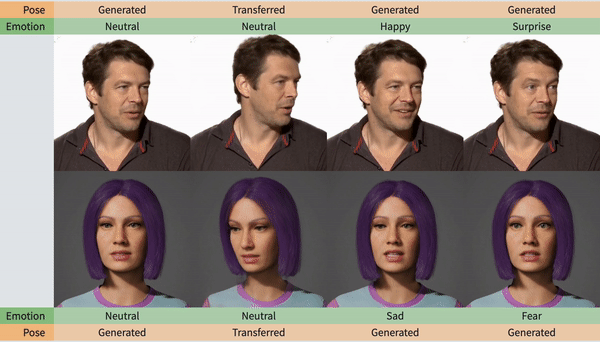



人脸动作更稳定,更注重细节
此前,最常使用的语音驱动照片的AI主要有三个:PC-AVS、MakeItTalk和Wav2Lip。
但这三个AI都或多或少有些缺陷之处,并且要么只能对口型,要么就只是整体面部控制的比较好,多个功能往往不能兼顾。
先来说说PC-AVS,它在对图像和语音进行处理时,会对输入图像进行严格的剪裁,甚至还会改变姿势,此外,生成的人脸动作很不稳定。
而MakeItTalk,在对口型方面效果不是很好,有时候生成的视频中还会出现空白的地方。
Wav2Lip的功能则比较单一,它主要是配音AI,只改变唇部的动作,唇部之外的面部表情毫无变化。
而这些问题,在SPACEx身上通通都被解决掉了,话不多说,直接看看它们之间的效果对比!


而细分到各个具体的功能,SPACEx都集成了哪些功能呢?
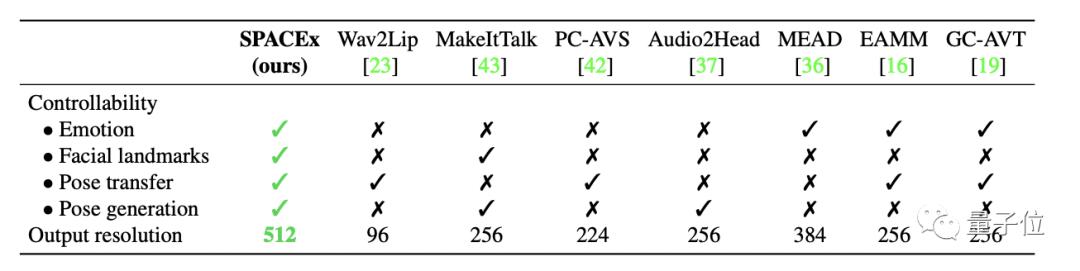
下面这个表格给出了答案,情绪控制、标记面部landmark、头部转动和动作生成,SPACEx都能很好地兼顾,不会像以往的模型顾此失彼。
值得注意的是,SPACEx生成视频的质量也整体上升了一个台阶,以往同类型的AI最高只能达到384的分辨率,而SPACEx这次已经达到了512X512。
具体原理
其中,很大一部分功劳是贡献的,它是英伟达两年前公布的一个AI算法。
它不仅能压缩视频的流量,还能保证视频的画质。


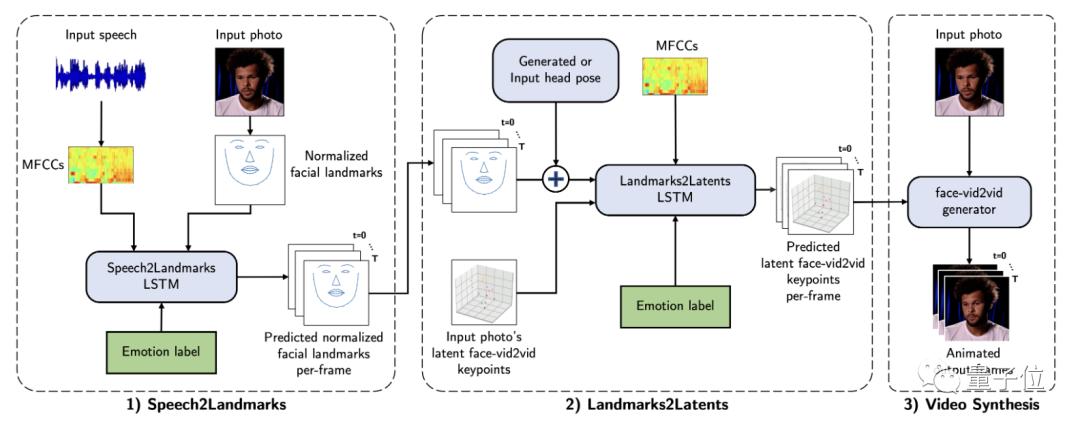
这得从SPACEx生成视频的过程来看,主要分三个阶段。
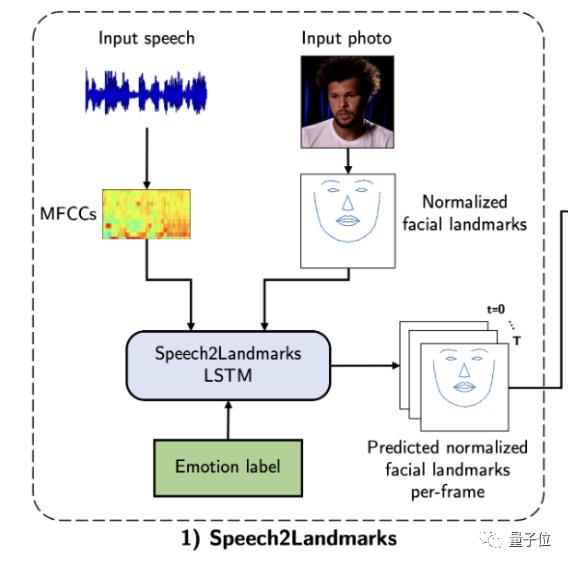
第一个阶段可以概括为Speech2Landmarks,即从输入的语音中来预测各个音节所对应的标准面部landmarks。
在预测的过程中,还会插入对应的情绪标签。
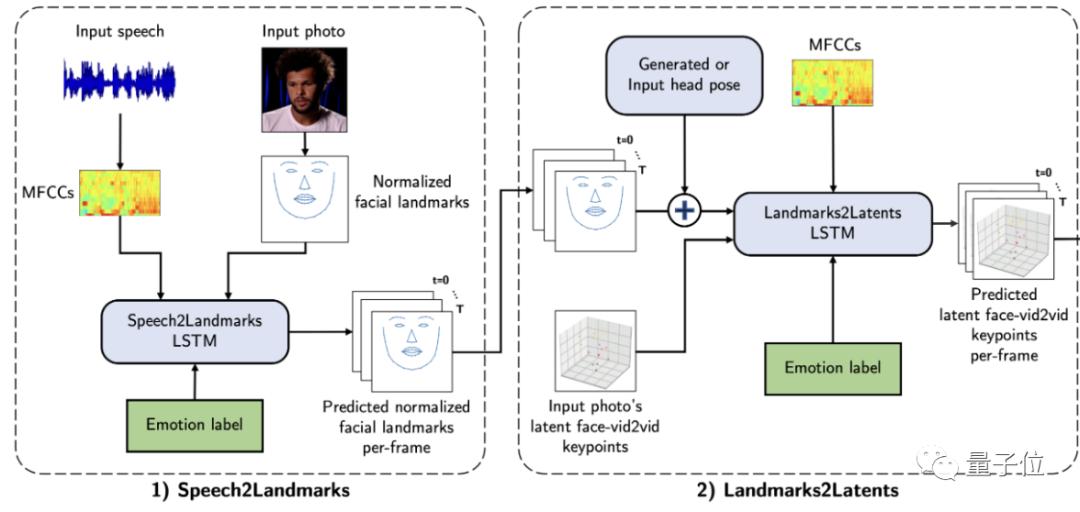
然后将这些关键点对应到上一步输出的标准面部landmarks上。
不过还是值得一试的,感兴趣可以戳下文链接~
论文地址:
https://arxiv.org/pdf/2211.09809.pdf
参考链接:
https://deepimagination.cc/SPACEx/
科技前沿进展日日相见 ~
原标题:《英伟达让AI“演技”再上台阶:仅靠语音驱动1张照片说话,惊讶恐惧表情狠狠拿捏》