翻译、编辑:Alex
技术审校:刘连响
本文来自_Smashing Magazine_,原文链接:
https://www.smashingmagazine.com/2021/08/http3-core-concepts-part1/
什么是 QUIC?
你也许很好奇:为什么 QUIC 如此重要?谁在乎这些特性是在 HTTP/3 还是 QUIC 中?在我看来,它很重要,因为 QUIC 是一个通用传输协议,它和 TCP 非常相似,除了 HTTP 和网页加载外,它可以并将用于许多应用场景,比如,DNS、SSH、SMB 和 RTP 等都能运行在 QUIC 之上。因此,让我们一起来更深入地了解 QUIC,因为我读到的关于 HTTP/3 的大部分误解都来自它。
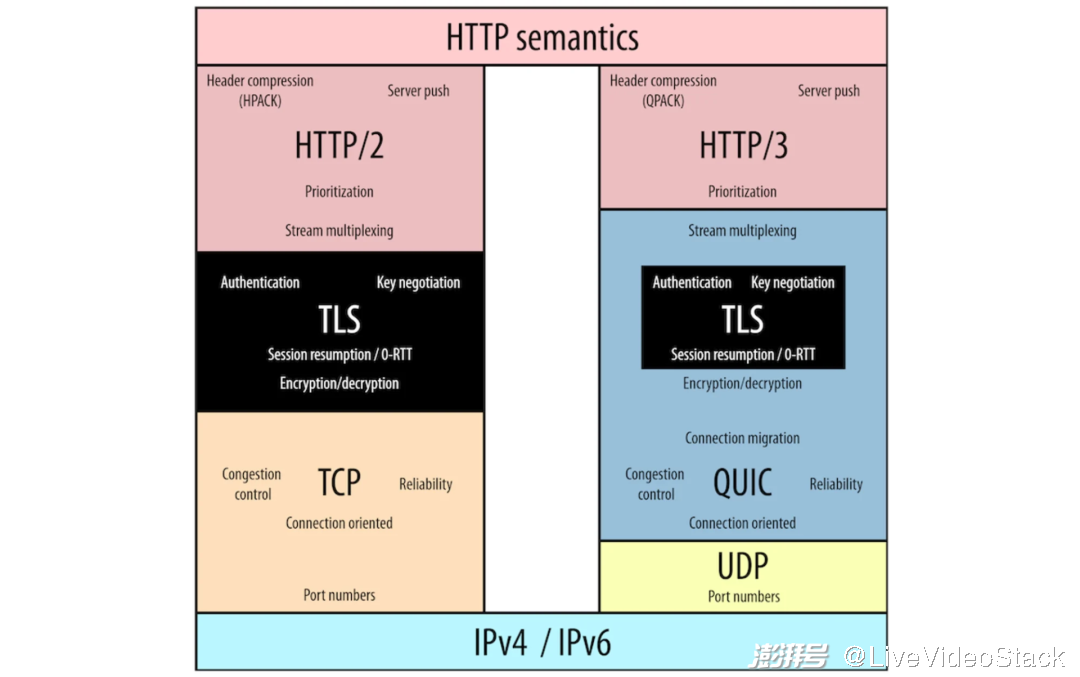 HTTP/2 vs. HTTP/3 协议栈对比
HTTP/2 vs. HTTP/3 协议栈对比
你也许听说过,QUIC 运行在另一个被称为 UDP (User Datagram Protocol) 的协议之上。没错,确实是这样,但并不是许多人所宣称的(性能)原因。理想情况下,QUIC 原本可以成为一个完全独立的新型传输协议,直接运行在协议栈中的 IP 之上(参见上图)。
然而,这么做会出现我们尝试升级 TCP 时所产生的相同问题:为了识别和允许 QUIC,互联网上的所有设备必须先进行升级。幸运的是,我们将 QUIC 构建在了另一个在互联网上被广泛支持的传输层协议 ——UDP 之上。
“你知道吗?
作为最基础的传输协议,除了所谓的端口号(比如,HTTP 使用端口 80,HTTPS 使用端口 443,DNS 使用端口 53),UDP 不提供任何特性。它既不会通过握手建立连接,也不可靠:如果一个 UDP 包丢失,不会获得自动重传。UDP 这种 “尽力而为” 的方法意味着你可以获得高性能:无需等待握手,也没有队头阻塞。实际上,UDP 主要用于以高速率更新的实时流量,因此很少受到丢包的影响,因为丢失的数据很快就会过时(比如实时视频会议和游戏)。UDP 也可用于低延迟预先请求的场景,比如,只需一次往返即可完成的 DNS 域名查找。
许多人声称 HTTP/3 之所以构建在 UDP 之上是因为性能。他们说,HTTP/3 更快是因为它和 UDP 一样,不用建立连接也无需等待数据包重传。这些说法都是错误的。正如我们之前所说,QUIC 和 HTTP/3 使用 UDP,主要是因为 UDP 可以使它们更容易部署,因为它已经被互联网上(几乎)所有设备所熟知和实现。
接着,在 UDP 之上,QUIC 基本上重新实现了使 TCP 协议变得如此强大和流行(但有些慢)的几乎所有特性。QUIC 绝对可靠:它通过确认接收到的数据包 [1] 和重传 [2] 来确保丢包依然能够到达。QUIC 也会建立连接,并具备非常复杂的握手 [3]。
最后,QUIC 也使用所谓的流量控制(flow-control)[4] 和拥塞控制(congestion-control)[5] 机制来阻止发送方使网络或者接收方超载,但这也使得 TCP 比 UDP 更慢。关键是,QUIC 以一种比 TCP 更加巧妙、更加高效的方式实现了这些特性。它将 TCP 多年的部署经验和最佳实践与一些新的核心特性结合起来。我们将在下文深入讨论这些特性。
要点:
上文的要点是:天下没有免费的午餐。HTTP/3 并不会仅仅因为我们将 TCP 换成了 UDP 而神奇般地比 HTTP/2 快。相反,我们已经重新构想和实现了一个更加高级的 TCP 版本,并将其称为 QUIC。因为我们想让 QUIC 更容易部署,所以我们将它运行在 UDP 之上。
主要变化
所以,QUIC 在哪些方面优于 TCP? 它们之间有何不同?在本系列的下一部分中,我们将具体讨论 QUIC 中新的特性和机会(0-RTT 数据、连接迁移、应对网速慢和丢包的更强恢复能力)。所有这些新事物基本上可以总结为四个主要变化:
·QUIC 与 TLS 深度集成。
·QUIC 支持多个独立的字节流。
·QUIC 使用连接 ID。
·QUIC 使用多个数据帧(frame)。
接下来,让我们详细了解每个变化。
| 没有 TLS 就没有 QUIC
如前所述,TLS [6]( Transport Layer Security protocol,传输层安全协议) 负责保护和加密互联网上发送的数据。当你使用 HTTPS 时,你的纯文本 HTTP 数据先由 TLS 加密,再由 TCP 传输。
“你知道吗?
好在这里并不需要介绍 TLS 的技术细节 (https://hpbn.co/transport-layer-security-tls/)。你只需要知道,某些非常高级的数学和非常大的数字(质数)实现了这些加密。在单独的特定 TLS 加密握手中,客户端和服务器之间协商这些数学参数。像 TCP 握手一样,这次协商需要一些时间。在 TLS 的旧版本中(如 1.2 和更早的版本),通常需要两次网络往返。幸好,新版本的 TLS(1.3 是最新版本)减少到只需一次往返。这主要是因为 TLS 1.3 将所协商的不同数学算法严格限制为少数几个(最安全)。这意味着客户端可以立即猜到服务器会支持哪些算法,而无需等待显示列表,从而节省了一次往返。
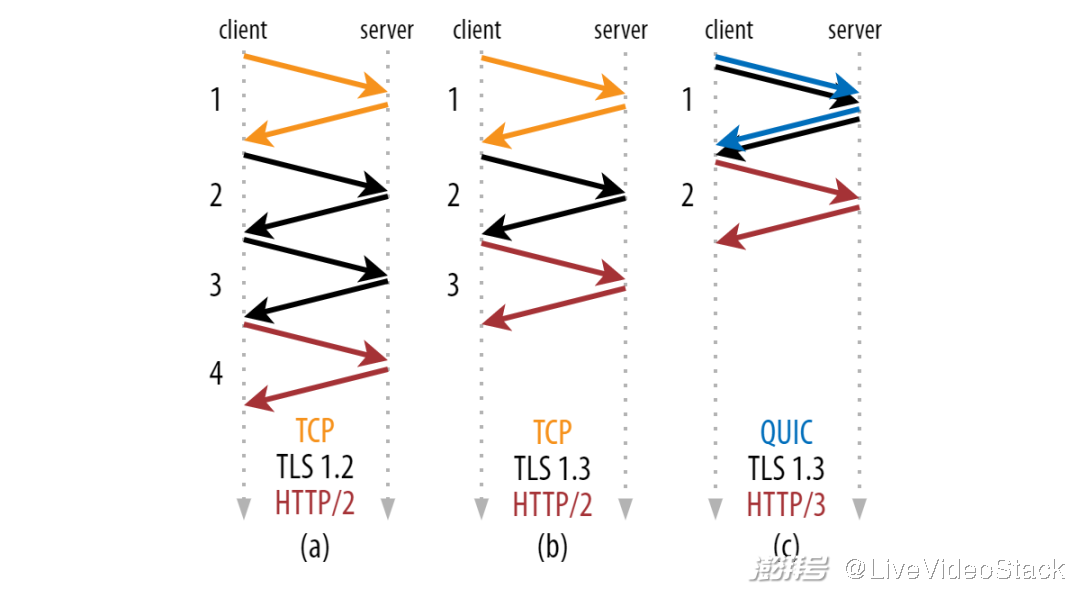 TLS、TCP 和 QUIC 握手持续时间
TLS、TCP 和 QUIC 握手持续时间
互联网发展早期,在处理方面,加密流量的成本非常高。除此之外,并不是所有应用场景都需要这种加密。因此,从历史的角度看,TLS 一直都是一个完全独立、可以选择性地运行在 TCP 之上的协议。这就是 HTTP(没有 TLS)和 HTTPS(有 TLS)的区别所在。
随着时间的推移,我们对待互联网安全的态度(当然)已经转换为 “默认安全 [7]”。因此,虽然 HTTP/2 在理论上无需 TLS(甚至在 RFC 规范中被定义为明文 HTTP/2 [8])就可以直接运行在 TCP 之上,但(流行的)Web 浏览器实际上却并不支持这一模式。某种程度上,浏览器厂商在有意识地以性能为代价来获取更高的安全性。
由于始终运行的 TLS 不断发展(尤其对于 Web 流量来说),那么 QUIC 的设计者决定利用这一趋势更进一步也就不足为奇了。他们没有简单地为 HTTP/3 定义明文模式,而是选择将加密深深内置于 QUIC 之中。虽然第一个谷歌版本的 QUIC 为此使用了自定义设置,但是标准化的 QUIC 直接使用了现有的 TLS 1.3。
为此,由上图所示,它使协议栈中协议之间不再完全分离。虽然 TLS 1.3 依然可以独立运行在 TCP 之上,但 QUIC 将 TLS 1.3 进行了封装。换句话说,如果没有 TLS,就无法使用 QUIC;QUIC(以及 HTTP/3)始终完全加密。除此之外,QUIC 还加密它的(几乎所有)数据包头字段;传输层信息(如从没有被 TCP 加密的数据包序号)不再被 QUIC 的中间件读取(甚至是一些数据包头的 flag 也被加密)。
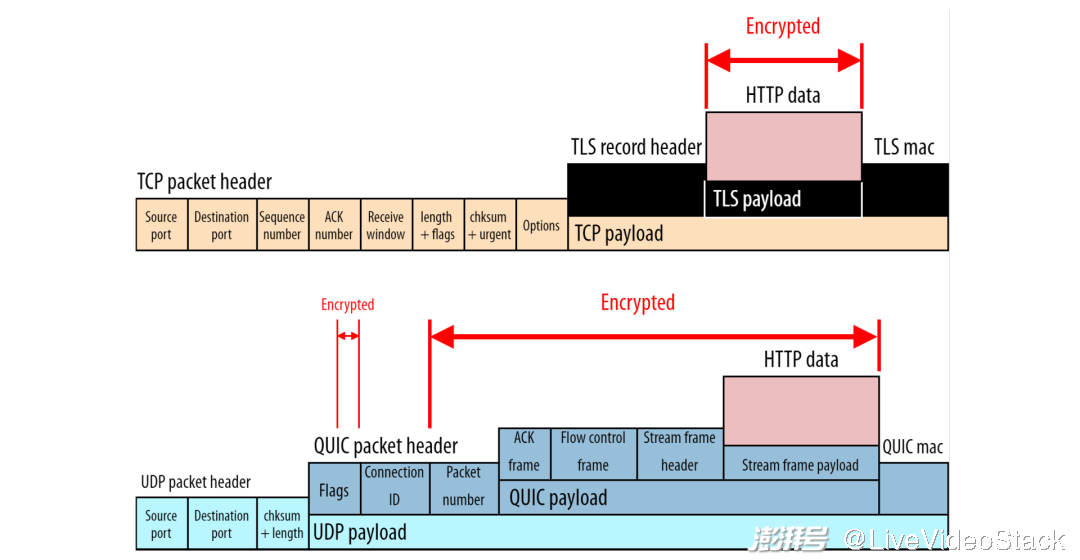 与 TCP+TLS 不同,QUIC 也加密数据包头和负载中的传输层元数据(注意:字段大小可扩展)
与 TCP+TLS 不同,QUIC 也加密数据包头和负载中的传输层元数据(注意:字段大小可扩展)
尽管如此,QUIC 首先使用 TLS 1.3 握手(几乎像你使用 TCP 那样)来创建数学加密参数。然而,在这之后,QUIC 接手并由它自己加密数据包。而使用 TLS-over-TCP,则由 TLS 加密。这一看似微小的差别代表了始终开启加密(加密将会在更加底层的协议层强制执行)的一个根本概念变化。
这种方法为 QUIC 带来了几个优势:
·对用户来说,QUIC 更安全。
因为无法运行明文 QUIC,所以攻击者和窃听者所能够监听的选项也更少。(最近的研究显示了 HTTP/2 的明文选项有多危险:https://labs.bishopfox.com/tech-blog/h2c-smuggling-request-smuggling-via-http/2-cleartext-h2c)
·QUIC 可以更快地建立连接。
对于 TLS-over-TCP,TLS 和 TCP 协议都需要单独握手,而 QUIC 将传输和加密握手合并为一次握手,节省了一次往返(见上图)。我们将在第二部分详细讨论这一点。
·QUIC 更易进化。
因为 QUIC 被完全加密,所以网络中的中间件无法像观察和理解 TCP 那样知悉 QUIC 的内部工作原理。因此,这些中间件也不会因为不再更新而在新版本的 QUIC 出现(意外)中断的情况。如果未来我们想向 QUIC 中添加新的特性,我们 “只” 需更新终端设备即可,而无需更新全部中间件。
然而,除了这些优势以外,广泛加密也存在潜在的缺点:
·许多网络将对允许 QUIC 犹豫不决。
很多公司也许希望将 QUIC 阻挡在防火墙上,因为监测不需要的流量变得更加困难。ISP 和中间网络可能会阻止它,因为很难再获取平均延迟和丢包率等指标,这使得发现和诊断网络问题难上加难。这也意味着 QUIC 也许永远都无法获得普遍应用,我们将在第三部分详细探讨。
·QUIC 拥有更高的加密开销。
QUIC 使用 TLS 加密每个单独的数据包,而 TLS-over-TCP 可以同时加密多个数据包。因此,QUIC 很可能会在高吞吐量的场景中变慢(我们将在第二部分讨论)。
·QUIC 使网络变得更加中心化。
我经常听到这样的抱怨:“谷歌之所以推动 QUIC 发展是因为这可以让他们充分访问数据,而不与他人共享。” 我很不同意这种说法。首先,与 TLS-over-TCP 相比(QUIC 保持了现状),QUIC 不会向外部观察者隐藏更多(或者更少!)的用户层信息,比如:你在访问哪些 URL。
其次,虽然谷歌发起了 QUIC 项目,但我们今天讨论的最终协议由 IETF 中更广泛的团队设计。在技术方面,IETF 的 QUIC 与谷歌的 QUIC 差别很大。不过,IETF 的工作组成员确实大部分都来自如谷歌和 Facebook(现更名为 Meta)这样的大公司,还有 Cloudflare 和 Fastly 等 CDN 公司。由于 QUIC 的复杂性,只有这些公司知道如何正确和高性能地部署它(比如,实际部署中的 HTTP/3),而令人担忧的是,这将很可能导致这些公司更加中心化。
“Robin 的话:
这也是我写作这种类型的文章以及发表许多技术演讲 [9] 的原因之一:确保更多人理解协议细节,并能够独立于这些大公司使用它们。
要点:
上文的关键要点是:QUIC 默认深度加密。这不仅提高了它的安全性和隐私特性,而且有助于它的可部署性和不断进化。虽然这使得 QUIC 运行起来有些重,但作为回馈,它允许其他优化,比如更快的连接建立。
| QUIC 支持多个字节流
QUIC 和 TCP 之间的第二个重大区别更具有技术性,我们将在第二部分详细探讨其中的细节。不过现在,我们可以从更高层次理解它的主要方面。
“你知道吗?
首先要考虑到,即使是一个简单的网页也是由许多独立的文件和资源组成的,其中包括 HTML、CSS、JavaScript 和图片等等。每一个文件都可以看作一个简单的 “二进制 blob”:被浏览器以某种方式解释的 0 和 1 的集合。当在网络上发送这些文件时,我们并不会一次性传输它们,而是将它们分为更小的数据块(通常每个大约 1400 字节)并以单个数据包的形式发送。因此,我们可以将每个资源看作一个单独的 “字节流”(因为数据会随着时间而下载或者逐个 “流式传输”)。
对于 HTTP 1.1 来说,下载资源的过程非常简单,因为每个文件都有自己的 TCP 连接并可以被完整下载。比如,如果我们有 A、B 和 C 三个文件,那么我们就会有三个 TCP 连接。第一个连接会看到一个 AAAA 的字节流,第二个是 BBBB,第三个是 CCCC(每个重复的字母都是一个 TCP 数据包)。这么做倒是行得通,但是却非常低效,因为每个新连接都有一些开销。
实际上,浏览器会限制用到的并发连接数量(以及并行下载的文件数量):通常情况下,每个页面加载在 6 到 30 个之间。一旦前一个文件被完全传输,就会重用连接下载新的文件。这些限制最终开始影响现代页面(通常加载超过 30 个资源)中的网络性能。
HTTP/2 的主要目标之一就是改善这种情况。它的做法是:不再向每个文件开放 TCP 连接,而是使用单一 TCP 连接下载不同的资源。“多路复用不同的字节流” 实现了这一切。多路复用是一种高级的说法:即我们在传输时将不同文件的数据混合。对于我们的三个文件示例而言,我们将获得一个单一的 TCP 连接,传入的数据也许看起来像 AABBCCAABBCC(虽然也有许多其他排序方案 [10])。这种操作足够简单而且确实很有效,使得 HTTP/2 能够在开销比 HTTP/1.1 少很多的情况下,速度和 HTTP/1.1 一样快(或者比 HTTP/1.1 还快一点)。
让我们仔细看看这一区别:
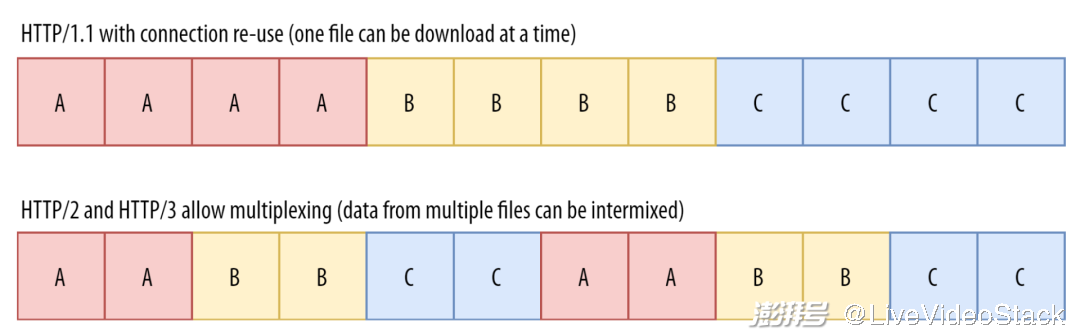 与 HTTP/2 和 HTTP/3 不同,HTTP/1.1 不允许多路复用
与 HTTP/2 和 HTTP/3 不同,HTTP/1.1 不允许多路复用
然而,TCP 还存在一个问题。你看,TCP 这个 “古老” 的协议并不是为了加载网页而设计的,所以它根本不知道 A、B 和 C。在 TCP 内部,它认为自己只传输单一文件 ——X,它并不在乎被看作 XXXXXXXXXXXX 的数据包实际上是 HTTP 层面的 AABBCCAABBCC。在大多数情况下,这无关紧要(实际上它使 TCP 变得相当灵活)。但是当网络上出现丢包时,情况就发生了变化。
假设第三个 TCP 数据包(包含文件 B 的第一数据)发生丢包,但其他所有数据都被传输。TCP 通过重传一个内含丢失数据新副本的数据包来处理丢包,但这种重传需要消耗一些时间(至少一个 RTT)才能到达。你也许认为这不是什么大问题,因为我们没有看到资源 A 和 C 的丢失,所以我们可以在等待 B 的丢失数据的同时开始处理它们,对吧?
遗憾的是,不可以。因为重传逻辑发生在 TCP 层,而 TCP 不知道 A、B 和 C!相反,TCP 认为单一 X 文件的一部分已经丢失,所以它觉得自己必须阻止 X 的剩余数据被处理,直到填满漏洞。换句话说,虽然在 HTTP/2 层,我们知道我们已可以处理 A 和 C,但 TCP 并不知晓这一点,因此导致速度变慢。这种低效就属于 “队头阻塞 [11]” 问题。
QUIC 的主要目标就是解决传输层的队头阻塞问题。不同于 TCP,QUIC 清楚地知道它在多路复用多个、独立的字节流。当然,它并不知道自己在传输 CSS、JavaScript 和图像;它只知道这些流是彼此分开的。因此,QUIC 可以在每个流的基础上执行丢包监测和恢复逻辑。
在上面的场景中,它只会保留字节流 B 的数据,而且不同于 TCP,QUIC 会尽快将 A 和 C 的数据传输给 HTTP/3 层(请看下图说明)。理论上,这么做会改进性能。但现实情况却很微妙,我们将在第二部分讨论。
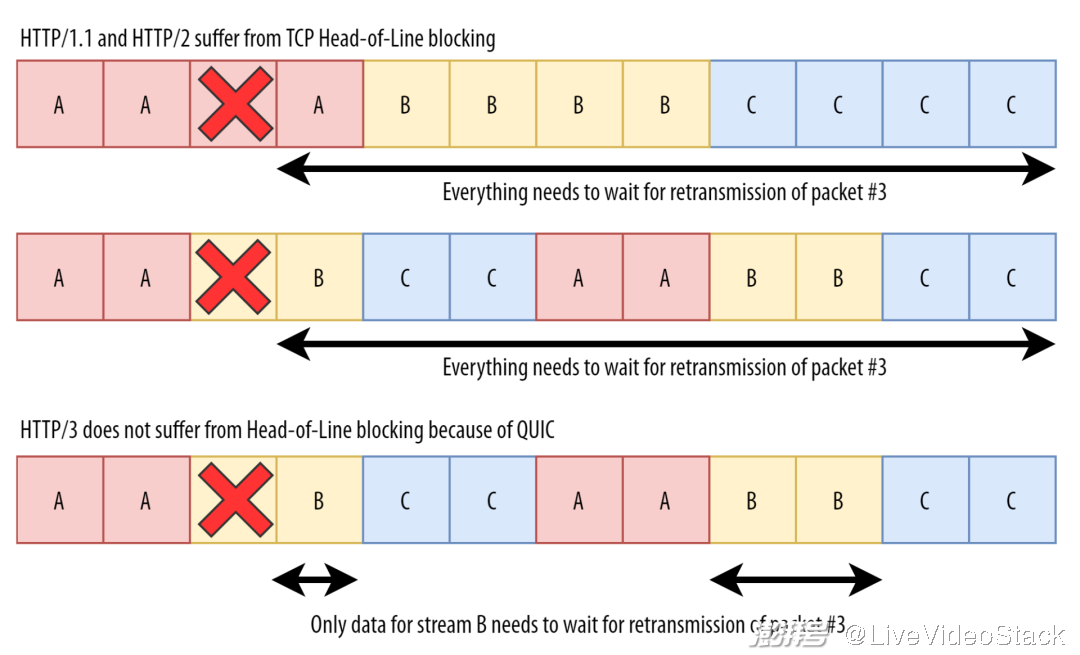 QUIC 使 HTTP/3 绕过队头阻塞问题
QUIC 使 HTTP/3 绕过队头阻塞问题
现在,我们已经了解到 TCP 和 QUIC 之间的基本区别。这一区别也很偶然地成为了我们无法在 QUIC 上运行 HTTP/2 的主要原因之一。正如我们之前所说,HTTP/2 还包括在单一(TCP)连接上运行多个流的概念。因此,HTTP/2-over-QUIC 将会有两路不同且相互竞争的流彼此叠加。
将它们放在一起 “和谐” 运行将会是一个非常复杂且容易出错的操作,所以 HTTP/2 和 HTTP/3 之间的关键区别之一就是:后者可以移除 HTTP 流并重用 QUIC 流,但这么做也会对一些特性(如服务器推送、头部压缩和优先级)的实现方式产生影响,我们将会在第二部分了解。
要点:
上文的要点是:TCP 的设计目的从来不是在单一连接上传输多个、独立的文件,但因为这正是网页浏览所需要的,所以多年来产生了很多低效问题。通过在传输层传输多个字节流以及在每个流基础上处理丢包问题,QUIC 解决了 TCP 的这一难题。
| QUIC 支持连接迁移
QUIC 中的第三个重大改进就是让连接可以保持更长时间。
“你知道吗?
当讨论协议时,我们经常使用 “连接” 的概念。但是,到底什么是连接?通常只要两个端点(比如浏览器或客户端和服务器之间)间发生一次握手,人们就会说这是 TCP 连接。这也是 UDP 经常被称为 “无连接” 的原因(有些误导),因为它没有这样的握手。然而,这种握手没有什么特别之处:只是一些特定形式的数据包被发送和接收。它有几个目的,其中最主要的就是确保对面存在通信对象,并愿意且能够与我们交流。值得反复一提的是,即使 QUIC 在 UDP 之上运行,它也有握手操作(UDP 却没有)。
所以,问题就变成了:那些数据包如何到达正确的目的地?在互联网上,IP 地址用于在两台独特的机器之间发送数据包。然而,只拥有手机和服务器的 IP 还不够,因为它们都希望能够在每一端同时运行联网程序。
为了区分连接和它们所属的应用,每个单独连接都会在两个端点处被分配一个端口号。服务器应用通常根据自身功能而拥有固定的端口号 [比如 HTTP (S) 的端口 80 和端口 443,DNS 的端口 53],而客户端通常为每个连接(半)随机选择端口号。
因此,要定义各种机器和应用间的连接,我们需要一个四元组:客户端 IP 地址 + 客户端端口 + 服务器 IP 地址 + 服务器端口。
在 TCP 中,仅使用四元组就可以识别连接。所以,如果这四个参数之一发生了变化,就会变成无效连接并需要重新建立连接(包括一次新的握手)。为了理解这一点,可以想象一下 “停车场问题”:你现在在一个有 Wi-Fi 的建筑内使用智能手机,那么 Wi-Fi 网络上就会出现你的 IP 地址。
如果你现在走到了外面,你的手机很可能切换到了蜂窝 4G 网络。因为这是一个新的网络,它将获得一个全新的 IP 地址,这是因为 IP 地址会根据网络而发生变化。现在,服务器将看到 TCP 数据包来自之前从未见过的客户端 IP(当然,这两个端口和服务器 IP 可以保持不变)。如下图所示。
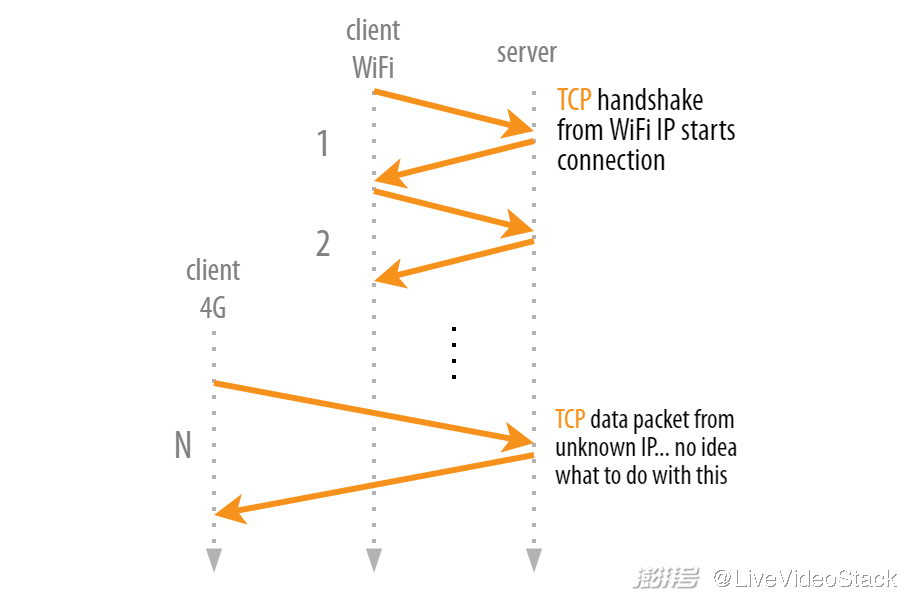 TCP 的 “停车场问题”:一旦客户端获得一个新的 IP,服务器就不再将它链接到连接
TCP 的 “停车场问题”:一旦客户端获得一个新的 IP,服务器就不再将它链接到连接
但是服务器怎么知道来自新 IP 的数据包属于 “连接”?它怎么知道这些数据包不属于来自另一个蜂窝网络 [选择了同一个(随机)客户端端口(很容易发生)] 的新连接?很遗憾,它不知道。
因为在我们还梦想着蜂窝网络和智能手机以前,TCP 就已经发明了,(比如)所以没有任何机制允许客户端让服务器知道它已经更改了 IP。甚至没有办法 “关闭” 连接,因为发送到旧四元组的 TCP 重置和 fin 命令不会再到达客户端。因此,实际上,每个网络更改都意味着无法再使用现有的 TCP 连接。
必须执行新的 TCP(也许是 TLS)握手才能建立新的连接,而且根据应用层协议,需要启动重新连接。比如,如果你正在通过 HTTP 下载大文件,然后该文件很可能需要从头重新请求 [比如,如果服务器不支持范围请求 [12](range request)]。另一个例子是视频会议,因为在切换网络时,你也许会遇到短暂的停电。
请注意,还存在其他导致四元组发生变化的原因(比如,NAT rebinding [13]),我们将在第二部分探讨。
重启 TCP 连接会带来严重的影响(等待新的握手、重新开始下载、重建 context)。为了解决这些问题,QUIC 推出了一个被称为连接标识符(CID, connection identifier)的新概念。每个连接都在四元组之上分配了另一个编号,可以在两个端点间唯一识别它。
最重要的是,因为 CID 在 QUIC 中的传输层定义,所以它不会在切换网络时发生改变!请看下图所示。为了实现这一点,CID 包含在每个 QUIC 数据包的前端(这与 IP 地址和端口在每个数据包中的呈现方式很像)。(实际上,CID 是 QUIC 包头中少数几个没有加密的东西!)
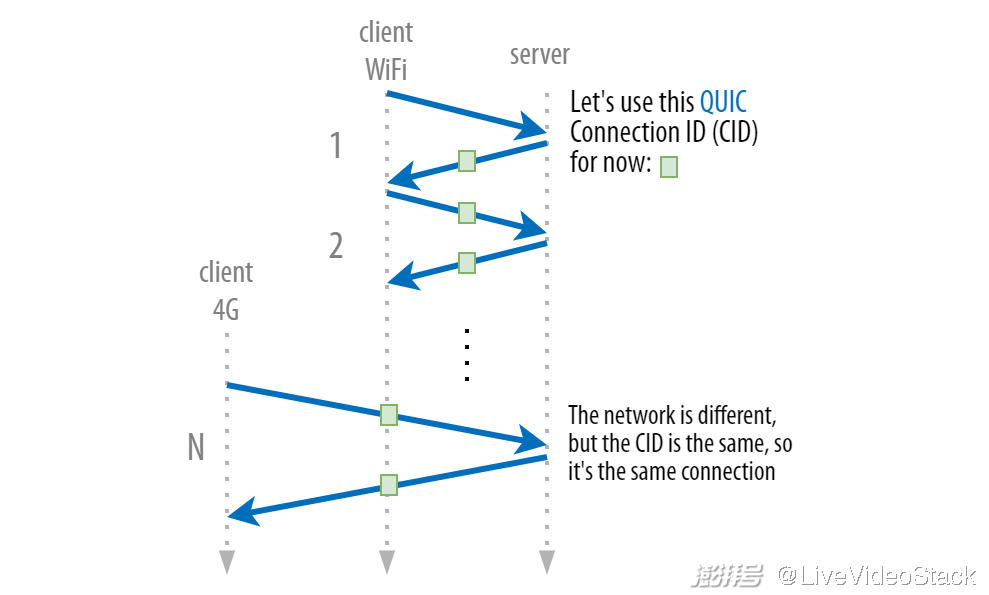 QUIC 通过 CID 使连接在切换网络时依然存在
QUIC 通过 CID 使连接在切换网络时依然存在
通过这种设置,四元组中的任何一项发生变化,QUIC 服务器和客户端只需看下 CID,就能知道还是之前的同一个连接,接着继续使用它即可。不需要新的握手,下载状态也可以维持原样。这个特性通常被称为连接迁移(connection migration)。在理论上,这将有利于性能的提升,但我们会在第二部分详细讨论实际中所发生的情况。
使用 CID 还需要克服其他挑战。比如,如果我们只用一个 CID,那么黑客和窃听者将极易跨网络跟踪用户,进而推断出他们(准确)的地理位置。为了阻止这种隐私 “噩梦”,当使用新的网络时,QUIC 每次都会更改 CID。
不过,这可能令你感到困惑:我刚才不是说过网络中的 CID 应该是相同的吗?是的,那是过于简化了。真正在内部发生的是:客户端和服务器在通用的 CID 列表(随机生成) 上达成一致,这些 CID 都映射到相同的概念上的 “连接”。
比如,客户端和服务器都知道 CID K、C 和 D 在现实中都映射到连接 X。因此,客户端可能在 Wi-Fi 上会使用 K 标记数据包,而在 4G 上便会切换到使用 C 标记。这些通用列表在 QUIC 中的协商是完全加密的,所以潜在攻击者将无法得知 K 和 C 实际上是 X,但客户端和服务器会知道,并且它们会一直保持连接状态。
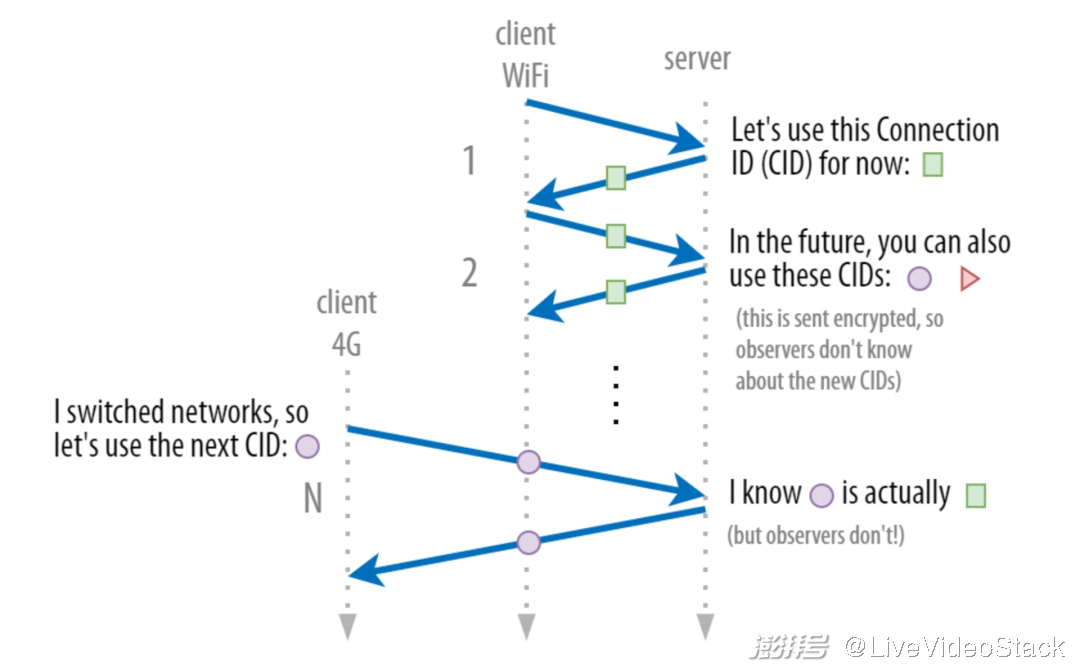 QUIC 使用多个协商连接标识符(CID)阻止用户被追踪
QUIC 使用多个协商连接标识符(CID)阻止用户被追踪
现在越来越复杂了,因为客户端和服务器将拥有(它们自己选择的)不同的 CID 列表,就像它们拥有不同的端口号一样。这主要是为了支持大规模服务部署中的路由和负载均衡(routing and load balancing)。我们将在第三部分详述。
要点:
上文的要点是:在 TCP 中,连接由四个参数定义,而当端点切换网络时,这些参数也会发生变化。因此,这些连接有时需要重启,从而导致停机。QUIC 为此增加了另一个参数 ——CID。QUIC 客户端和服务器都知道 CID 所映射到的连接,所以在面对网络变化时更容易恢复。
| QUIC 灵活且可进化
QUIC 的最后一个特点就是它经过专门设计,更容易进化(evolve)。它通过几种不同的方法实现了这一点。首先,如前所述,QUIC 几乎完全加密这一事实意味着我们只需更新端点(客户端和服务器),而不是所有中间件(如果我们想要部署新版本 QUIC 的话)。这仍然需要时间,但通常只需要几个月,而不是几年。
其次,不同于 TCP,QUIC 没有使用单一固定的数据包头来发送所有协议元数据,而是具有较短的数据包头并在有效负载内部使用几种 “数据帧(frame)”[14](有些像微型专用数据包)来传递额外的信息。比如,用于确认的 ACK 数据帧、帮助建立连接迁移的 NEW_CONNECTION_ID 数据帧、传输数据的 STREAM 数据帧,如下图所示。
这么做主要是为了优化,因为并不是每个数据包都会传送所有可能存在的元数据(所以 TCP 数据包头通常会浪费相当多的字节,参见上图)。使用这些数据帧还会带来一个非常有用的副作用:未来为 QUIC 扩展定义新的数据帧类型将会变得非常容易。比如,很重要的 DATAGRAM 数据帧 [15]:它允许通过加密 QUIC 连接发送非可靠数据。
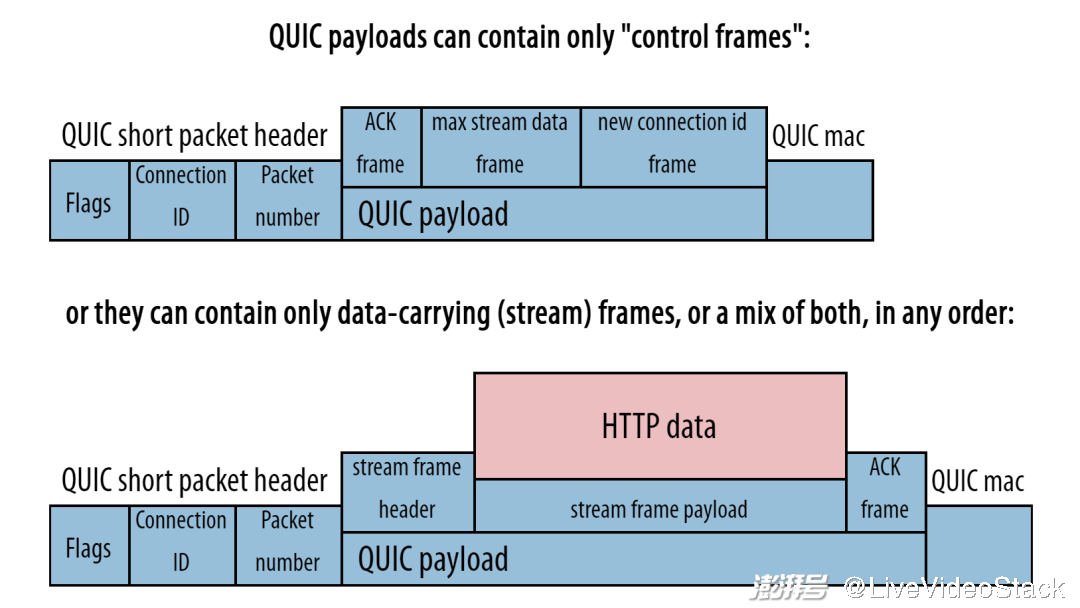 QUIC 使用单独的框架(而不是大的固定数据包头)发送元数据。
QUIC 使用单独的框架(而不是大的固定数据包头)发送元数据。
第三,QUIC 使用了一个自定义的 TLS 扩展来传送传输参数 [16]。客户端和服务器因此可以为 QUIC 连接选择配置,意味着它们能够协商启用哪些特性(比如,是否允许连接迁移、支持哪些扩展等)和传递某些机制(比如,支持的最大数据包大小、流量控制限制)的合理默认值。虽然 QUIC 标准定义了很长的参数列表 [17],但它也允许扩展定义新的参数,这也让 QUIC 变得更加灵活。
最后,虽然这并不是 QUIC 本身的真正要求,但目前大部分实现都是在 “用户层” 完成的(而 TCP 是在 “内核层” 完成的)。我们将在第二部分详细讨论,但这也意味着试验和部署各类 QUIC 实现变体和扩展要比 TCP 容易得多。
要点:
虽然 QUIC 现在已经被标准化,但它确实应被视为版本一(RFC 中有清晰说明 [18]),并且已经有明确创建版本 2(而且更快)的想法。最重要的是,QUIC 允许轻松定义扩展,所以可以实现更多应用场景。
总结
让我们来总结一下在本部分所学到的内容。我们主要讨论了无处不在的 TCP 协议,以及它是如何被设计出来的(在很多当前挑战还未知的情况下)。当我们想要升级 TCP 赶上时代潮流,却发现在实际中这很难办到,因为几乎每个设备都有自己的 TCP 实现,并且都需要更新。
为了在改进 TCP 的同时绕过这个问题, 我们开发了新的 QUIC 协议(实际上是 TCP 2.0)。为了使 QUIC 更容易部署,它被运行在 UDP 之上(大部分网络设备也支持 UDP);为了确保 QUIC 可以不断进化,它几乎默认被完全加密,且使用了一个灵活的数据帧机制。
除此之外,QUIC 在很大程度上映照了已知的 TCP 特性,如握手、可靠性和拥塞控制。除了加密和使用数据帧,支持多个字节流和引入 CID 是 QUIC 的两大变化。不过,这些变化足以阻止我们直接在 QUIC 上运行 HTTP/2,因此我们需要创建 HTTP/3(实际上就是 HTTP/2-over-QUIC)。
QUIC 的新方法带来了很多性能上的改进,但它们的潜在收获比很多 QUIC 和 HTTP/3 文章中所传达的内容更微妙。既然我们已经了解了一些基础知识,接下来我们会在下一部分深入探索这些微妙之处。
注释:
[1] https://www.rfc-editor.org/rfc/rfc9000.html#name-generating-acknowledgments
[2] https://www.rfc-editor.org/rfc/rfc9000.html#name-retransmission-of-informati
[3] https://www.rfc-editor.org/rfc/rfc9000.html#name-cryptographic-and-transport
[4] https://www.rfc-editor.org/rfc/rfc9000.html#name-flow-control
[5] https://www.rfc-editor.org/rfc/rfc9002.html
[6] https://www.cloudflare.com/en-gb/learning/ssl/transport-layer-security-tls/
[7] https://blog.chromium.org/2021/03/a-safer-default-for-navigation-https.html
[8] https://www.rfc-editor.org/rfc/rfc7540#section-3.1
[9] https://www.youtube.com/results?search_query=robin+marx+quic
[10] https://blog.cloudflare.com/better-http-2-prioritization-for-a-faster-web/
[11] https://calendar.perfplanet.com/2020/head-of-line-blocking-in-quic-and-http-3-the-details/
[12] https://developer.mozilla.org/en-US/docs/Web/HTTP/Range_requests
[13] https://blog.cloudflare.com/the-road-to-quic/#onenattobringthemallandinthedarknessbindthem
[14] https://www.rfc-editor.org/rfc/rfc9000.html#name-frames-and-frame-types
[15] https://datatracker.ietf.org/doc/html/draft-ietf-quic-datagram-02
[16] https://www.rfc-editor.org/rfc/rfc9000.html#name-transport-parameters
[17] https://www.rfc-editor.org/rfc/rfc9000.html#name-transport-parameter-definit
[18] https://www.rfc-editor.org/rfc/rfc9000.html#name-overview
作者简介:
Robin Marx: IETF 贡献者、HTTP/3 和 QUIC 工作组成员。2015 年,作为 PhD 的一部分,Robin 开始研究 HTTP/2 的性能,这使他后来有机会在 IETF 中参与 HTTP/3 和 QUIC 的设计。在研究这些协议的过程中,Robin 开发了 QUIC 和 HTTP/3 的调试工具(被称为 qlog 和 qvis),目前这些工具已经使来自世界各地的许多工程师受益。
致谢:
本文已获得_Smashing Magazine_和作者 Robin Marx 的授权翻译和发布,特此感谢。